


파이썬 GIL(Global Interpreter Lock)와 asyncio 라이브러리
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
지난 글은 파이썬의 비동기 작업을 위한 제너레이터(generator)에 대해 정리했다. 이번 글은 파이썬의 전역 인터프리터 락(GIL, Global Interpreter Lock)과 비동기 작업에 대한 내용을 정리해봤다.
1. Python GIL(Global Interpreter Lock)
우선 파이썬의 특징을 살펴볼 필요가 있다. 파이썬은 GIL(Global Interpreter Lock)이 존재해서 여러 개의 스레드가 존재하더라도 한 시점에 단 하나의 스레드만 파이썬 바이트코드(bytecode)를 실행할 수 있다. 인터프리터 자체에 전체적인 락(lock)을 거는 메커니즘이다. 멀티 스레드를 지원하지만, GIL에 의해 단일 스레드를 강제 받는 모양새다.
파이썬은 객체의 생성과 소멸 시점을 관리하기 위해 해당 객체가 얼마나 참조되고 있는지를 세는 참조 횟수(Reference Count) 방식을 사용한다. GIL이 없는 멀티 스레드 환경이라면 여러 스레드가 동시에 하나의 객체에 접근할 때 경쟁 상태가 발생할 수 있다. 이로 인해 참조 횟수가 중복으로 올라가거나 사용 중인 스레드가 있음에도 참조 카운트가 0이 되어 객체가 비정상적으로 소멸해버리는 치명적인 문제가 생길 수 있다.
이를 막으려면 개별 객체마다 락을 거는 방법도 있지만, 이는 연산 비용이 비싸고 스레드 간에 서로 락을 기다리다 멈춰버리는 데드락(deadlock)을 유발할 수 있다. 파이썬 창시자인 귀도 반 로섬(Guido van Rossum)은 복잡한 객체 단위의 락 대신, 인터프리터 전체에 단 하나의 락을 걸어 한 번에 하나의 스레드만 안전하게 코드를 실행하게 하는 단순하고 강력한 방식을 선택했다.
멀티 코어 프로세서를 사용하더라도 한 번에 단 하나의 스레드만 인터프리터에서 실행되도록 강제하기 때문에 실제로는 스레드들이 병렬(parallel)이 아닌 순차적(serial)으로 실행되며, 다중 스레드의 최대 이점인 병렬 처리 능력이 크게 저하된다.
그나마 네트워크 요청이나 파일 입출력(읽기/쓰기)처럼 대기 시간이 긴 I/O 작업이 발생하면 해당 스레드는 자발적으로 GIL을 해제한다. 한 스레드가 I/O 응답을 기다리며 멈춰 있는 동안, 다른 스레드가 즉시 GIL을 획득하여 코드를 실행할 수 있으므로 I/O 대기 시간을 숨기고 병렬적인 처리를 수행하는 효과를 얻게 된다. I/O 작업에 한해서는 멀티 스레드의 이점을 가질 수 있다.
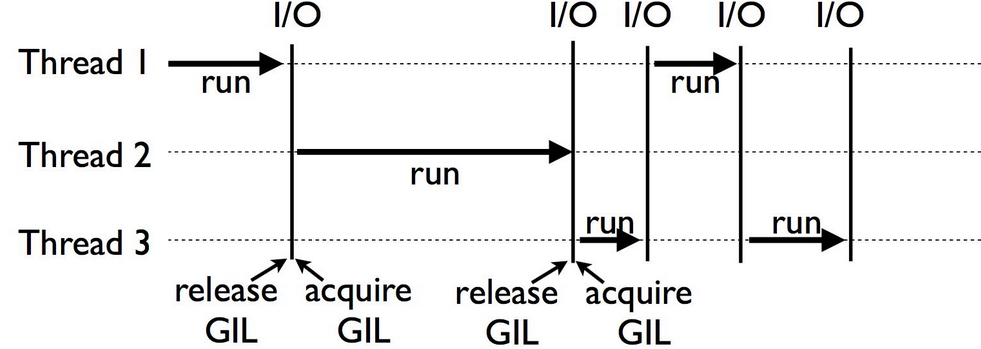
하지만 I/O 처리를 위해 멀티 스레드를 사용할 때 한계와 부작용도 존재한다. 수많은 동시 I/O 연결을 처리하기 위해 그만큼의 스레드를 생성하면, 각각의 OS 스레드가 차지하는 메모리 소모가 커지고 스레드 간 전환 비용이 급격히 늘어나 시스템 부하가 커진다. 메모리 및 문맥 전환(context switching)에 오버헤드가 발생한다.
I/O 작업이 OS의 버퍼링 덕분에 즉시 완료될 수 있는 상황에서도 무조건 GIL을 해제한다. 부하가 높은 상황에서는 다른 스레드들과 GIL을 획득하기 위해 다투면서 오히려 성능을 갉아먹는 스래싱(thrashing) 현상이 발생할 수 있다. 특히 I/O 스레드가 CPU 연산을 많이 하는 스레드와 함께 실행될 경우, I/O를 마치고 돌아온 스레드가 GIL을 다시 획득하는 데 어려움을 겪어 응답성이 매우 나빠지는 현상도 일어난다.
멀티 스레딩은 I/O 작업의 효율을 분명히 높여주지만 스레드 개수가 많아지면 운영체제 차원의 오버헤드와 GIL로 인한 병목 현상이 발생한다. 이런 문제를 피하고 I/O 효율을 극대화하기 위해, 최신 파이썬 생태계에서는 OS 스레드를 늘리지 않고 단일 스레드 내에서 이벤트 루프를 통해 I/O 작업을 처리하는 asyncio 기반의 비동기 프로그래밍이 널리 사용된다.
2. Multitasking in Python
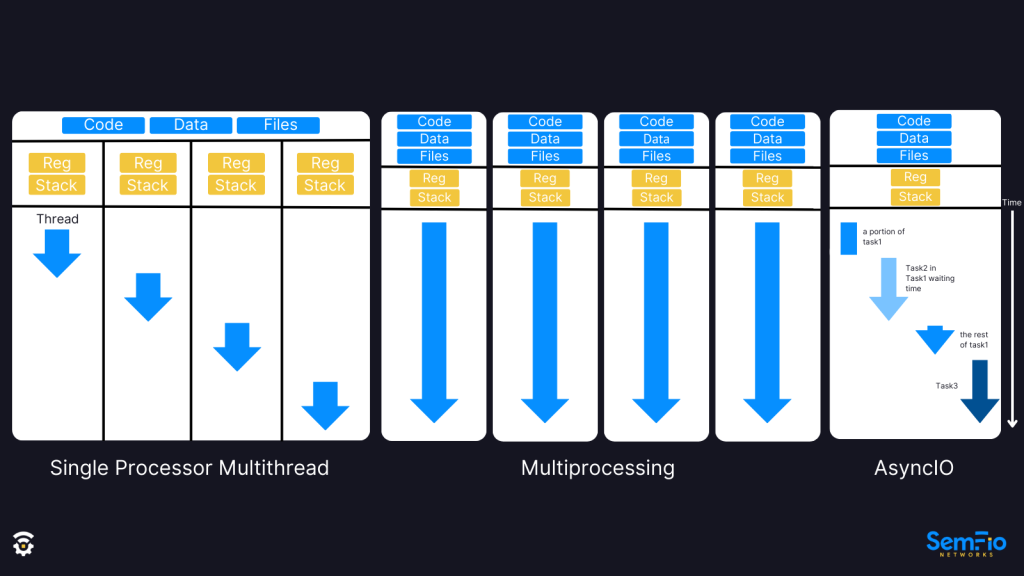
파이썬은 GIL이라는 언어 자체의 구조적 제약 때문에 멀티 스레드 모델은 성능 및 리소스 비용 문제를 유발한다. 그렇기 때문에 파이썬은 비동기 I/O(async I/O)를 통한 협력적 멀티태스킹(Cooperative Multitasking) 방식을 채택했다. 멀티태스킹이란 여러 작업을 동시에 처리하는 포괄적인 개념이다. 멀티 스레딩, 멀티 프로세싱, 비동기 I/O는 멀티 태스킹을 구현하는 구체적인 기술들이다. 아래 이미지를 통해 각 차이점을 살펴보자.
- 싱글 프로세서(e.g. CPU 코어)의 멀티 스레드 방식은 코드, 데이터, 파일들을 공유하고 여러 스레드를 하나의 프로세서가 번갈아가면서 실행한다. 각 스레드는 레지스터(register)와 스택 메모리를 별도로 가지고 있다. 예를 들어, 자바(Java)는 멀티 태스킹을 지원하기 위해 멀티 스레드 방식을 사용한다.
- 멀티 프로세싱은 여러 개의 프로그램이 동시에 실행되는 것이다. 멀티 스레드와 다르게 코드, 데이터, 파일을 공유하지 않는다. 프로세스 안의 실행 흐름이 스레드다. 컴퓨터에서 브라우저, VSCode, 에디터 같이 별도의 프로그램이 실행되는 것을 예로 들 수 있다.
- 비동기 I/O는 하나의 프로세스에서 하나의 스레드가 동시에 여러 개의 태스크를 수행하는 것을 의미한다. 하나의 프로세스이기 때문에 코드, 데이터, 파일을 공유하고, 하나의 스레드이기 때문에 레지스터와 스택을 공유한다. 중간에 I/O 작업이 필요하면 다른 곳에 위임하고, 메인 스레드는 다른 작업을 실행한다. 자바스크립트 런타임(JavaScript runtime)인 Node.js 나 브라우저가 이렇게 동작한다.
파이썬의 비동기 I/O는 자바스크립트 런타임의 비동기 작업과 동일하게 이벤트 루프(event loop)로 구현되어 있다. 두 환경 모두 기본적으로 하나의 메인 스레드에서 이벤트 루프가 돌아가고, 네트워크 I/O, 파일 입출력, 타이머 등 비동기 작업이 끝나는 것을 감지해서 콜백(callback)이나 코루틴(coroutine)을 실행한다. 두 언어 모두 단일 스레드 기반이므로 무거운 수학 연산 같은 CPU를 오래 점유하는 작업이 실행되면 제어권을 양보하지 않아서 이벤트 루프 전체가 정지되고 다른 작업들도 지연되는 단점도 동일하다.
3. async/await, coroutine and asyncio library
파이썬의 async와 await는 파이썬 3.5(PEP 492)부터 도입된 네이티브 코루틴(native coroutine)을 정의하고 제어하기 위한 전용 문법이다. 네이티브 코루틴은 다음과 같이 async def 키워드를 통해 정의할 수 있다.
import asyncio
async def fetch_data():
print("run fetch data")
await asyncio.sleep(1)
return "fetched data"
if __name__ == "__main__":
coroutine = fetch_data()
print(type(coroutine)) # <class 'coroutine'>
async def fetch_data():는 코루틴 함수가 된다. fetch_data()처럼 함수를 호출하면 바로 실행되는 게 아니라 코루틴 객체가 만들어진다. 나중에 실행될 비동기 작업을 만든 것이다. 위 코드를 실행하면 다음과 같은 로그가 보인다.
- “run fetch data” 로그는 출력되지 않는다.
<class 'coroutine'>
<sys>:0: RuntimeWarning: coroutine 'fetch_data' was never awaited
코루틴은 그대로 실행되지 않는다. asyncio 라이브러리가 필요하다. asyncio의 run 함수를 통해 코루틴을 실행할 수 있다.
import asyncio
async def fetch_data():
print("run fetch data")
await asyncio.sleep(1) # 1초 대기
return "fetched data"
if __name__ == "__main__":
coroutine = fetch_data()
print(type(coroutine))
result = asyncio.run(coroutine) # 코루틴 실행
print(result)
위 코드를 실행하면 다음과 같은 로그를 볼 수 있다.
- “run fetch data” 로그와 “fetched data” 로그 사이에 1초 정도 시간 간격이 존재한다.
<class 'coroutine'>
run fetch data
fetched data
asyncio는 async/await 문법을 사용하여 동시성(concurrency) 코드를 작성할 수 있게 해주는 파이썬의 표준 내장 라이브러리이다. 네트워크 통신, 웹 서버, 데이터베이스 연결 등 대기 시간이 긴 I/O 바운드 작업을 효율적으로 처리하기 위해 고안되었다.
asyncio 중심에는 이벤트 루프가 존재한다. 이벤트 루프는 여러 작업들의 실행 순서를 조율하는 관리자 역할을 수행한다. 멀티 스레드처럼 운영체제가 강제로 스레드를 전환하는 방식이 아니라, 단일 스레드 내에서 코루틴들이 제어권을 주고받는 협력적인 멀티태스킹(cooperative multitasking) 방식을 사용한다.
- 실행 중인 코루틴이 I/O 작업을 만나 await 키워드를 호출하면, 실행을 일시 정지하고 제어권을 이벤트 루프에게 자발적으로 양보한다. 비동기 작업은 OS에 의해 처리된다.
- 제어권을 넘겨받은 이벤트 루프는 OS의 셀렉터(epoll, kqueue 등)를 이용해 I/O 상태를 모니터링한다. I/O 작업이 끝나는 것을 기다리지 않고 실행 준비가 된 다른 작업을 찾아서 즉시 실행한다.
- 완료되지 않은 작업이나 신규 작업들은 작업 큐(task queue)에 들어가서 실행되길 기다린다. 이벤트 루프에 의해 실행 스택으로 올라온 작업은 완료되거나 I/O 처리를 기다릴 필요가 생길 때까지 실행된다.
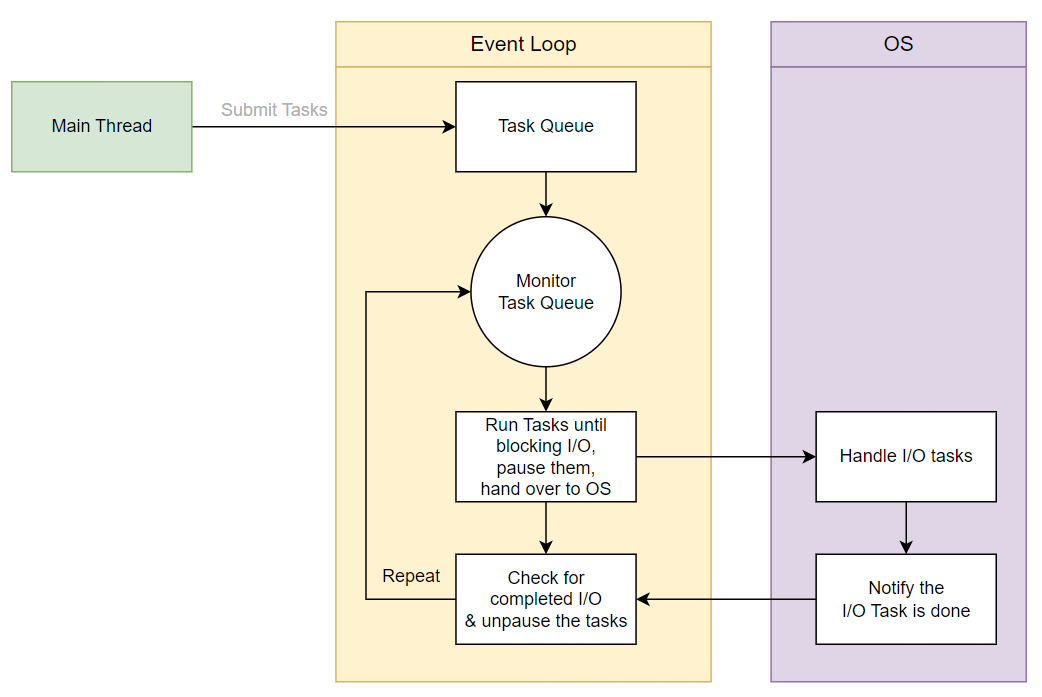
asyncio 라이브러리를 사용하면 멀티 스레드처럼 스레드 생성 비용이 들지 않는다. OS 차원에서 스레드를 강제로 전환하는 것이 아니기 때문에 컨텍스트 스위칭(context switching) 같은 비용도 필요 없다. 스택도 스레드마다 생성하는 것이 아니기 때문에 메모리 소모도 작다. asyncio는 매우 적은 비용만으로 수만 개의 네트워크 소켓 연결을 가볍게 동시에 처리할 수 있는 높은 확장성(scalability)을 갖고 있다.
위에서도 언급했지만, 단일 스레드로 수많은 작업을 쪼개어 처리하기 때문에 코루틴 내부에 무거운 CPU 연산(수많은 반복문 등)을 직접 수행하거나 비동기를 지원하지 않는 블로킹 함수를 호출하면 이벤트 루프 전체가 멈춰버리는 치명적인 문제가 발생한다. 이런 CPU 바운드 작업이나 블로킹 코드는 해당 작업만 수행하는 별도 스레드 풀(thread pool)이나 프로세스 풀(process pool)에 위임해야 한다.
위에서 살펴본 asyncio.run() 함수는 호출하면 이벤트 루프가 자동으로 생성된다. 파이썬 3.7부터 도입되었으며 주어진 메인 코루틴을 모두 실행한 뒤 루프를 깔끔하게 종료해 주는 역할을 하는 진입점(entrypoint) 함수다. 전달받은 메인 코루틴 객체를 태스크(Task) 객체로 감싸서 실행 대기 큐(ready queue)에 삽입한 후, 메인 코루틴이 최종 완료될 때까지 이벤트 루프를 돌린다. 메인 코루틴의 실행이 끝나면, 돌고 있던 이벤트 루프를 닫고 깔끔하게 정리(cleanup)한 뒤 결과값을 반환한다.
4. Difference between coroutine and task
asyncio 라이브러리의 태스크와 코루틴 차이점을 구분할 줄 알아야 한다. 우선 asyncio를 구성하는 주요 컴포넌트는 어떤 것들이 있는지 살펴보자.
- 이벤트 루프(event loop)
- 전체 비동기 작업을 지휘한다. 실행할 작업(콜백이나 태스크)들의 큐를 순환하며, 큐에서 작업을 꺼내 코루틴이 await 키워드를 만나 제어권을 양보할 때까지 실행을 진행시킨다.
- 코루틴이 I/O 작업 대기를 위해 일시 중단되면, 이벤트 루프는 운영체제의 이벤트(epoll, kqueue, IOCP 등)를 폴링하여 준비가 완료된 작업들을 다시 큐에 추가하는 작업을 무한히 반복한다.
- 코루틴(coroutine)
async def키워드를 통해 정의되며, 실행 도중 스스로 일시 중단(suspend)하고 나중에 그 지점부터 다시 재개할 수 있는 특별한 형태의 함수다.- 스레드처럼 OS에 의해 강제로 컨텍스트 스위칭이 되는게 아니라 await 키워드를 만나면 이벤트 루프에 제어권을 돌려주어 동시성(concurrent) 처리를 가능하게 한다.
- 태스크(task)
- 퓨쳐(Future) 클래스의 서브 클래스로 코루틴을 감싸서 이벤트 루프를 통해 백그라운드에서 자동으로 구동되도록 책임지는 관리 객체다.
- 태스크 객체를 통해 PENDING(대기 중)이나 FINISHED(완료됨) 같은 상태 정보를 추적할 수 있다.
asyncio.create_task(coroutine)함수를 사용하여 코루틴을 태스크로 변환할 수 있다. 해당 코루틴은 이벤트 루프의 실행 대기열에 등록되고, 동시에 실행될 준비를 마친다. 이벤트 루프는 태스크를 스케줄링한다.- 태스크는 자신이 래핑한 내부 코루틴의 send() 함수를 호출해서 해당 코루틴을 실행시킨다. 실행된 코루틴은 await 키워드를 만나 멈추거나 종료될 때까지 계속 실행된다.
- 코루틴이 완료되면 그 반환 값을 태스크 객체 자신의 내부에 결과값으로 저장한다.
태스크는 단순히 코루틴의 실행 완료 상태를 확인할 수 있는 객체일까? 코루틴이 태스크로 만들어지면 이벤트 루프에 의해 스케줄링 된다는 점이 중요하다. 간단한 예제 코드를 통해 개념을 이해해보자. 아래처럼 코루틴 객체를 만들어서 send() 함수를 호출하면 코루틴이 실행은 되지만, StopIteration 에러가 발생한다. StopIteration 에러에는 코루틴에서 반환한 값이 담겨있다.
async def fetch_data():
print("run fetch_data")
return "returned fetched data"
if __name__ == "__main__":
coroutine = fetch_data()
try:
coroutine.send(None)
except StopIteration as e:
print(f"StopIteration: {e.value}")
위 코드를 실행하면 다음과 같은 로그를 볼 수 있다.
run fetch_data
StopIteration: returned fetched data
코루틴 중간에 await 키워드가 있다면 어떨까?
import asyncio
async def fetch_data():
print("begin fetch data")
await asyncio.sleep(1)
print("end fetch data")
return "fetched data"
if __name__ == "__main__":
coroutine = fetch_data()
try:
coroutine.send(None)
except StopIteration as e:
print(f"StopIteration: {e.value}")
except Exception as e:
print(f"Exception: {e}")
이벤트 루프가 없는 상태에서 코루틴을 실행하면 await 키워드를 만나기 전까지 실행되는 것을 확인할 수 있다. await 키워드를 만나는 시점에 에러가 발생한다. 위 예제와 다르게 StopIteration 객체에 반환 값이 담기지 않고, Exception 에러를 처리하는 블록으로 이동한다. 코루틴 내부에 await 키워드가 있는 경우 이벤트 루프 내부에서 동작해야 한다.
begin fetch data
Exception: no running event loop
해당 코루틴을 태스크로 만들어 실행해보자. 다음과 같은 순서에 의해 실행된다.
- asyncio.run(main_coroutine) 함수에 의해 main 코루틴이 먼저 실행된다.
- 실행 중 task 객체가 await 키워드를 만나면 main 코루틴은 대기 상태로 들어간다.
- 대기 큐에서 스케줄링 대기 중인 fetch_data 코루틴이 실행된다.
- 실행 중 await 키워드를 만나면 fetch_data 코루틴은 대기 상태로 들어간다.
- task 객체의 작업이 완료되지 않았기 때문에 main 코루틴은 진행되지 않는다.
- 1초 뒤 asyncio.sleep() 완료되면 fetch_data 코루틴이 return 키워드에 의해 완료된다.
- main 코루틴이 스케줄링 되고, task 객체의 작업이 완료되었기 때문에 main 코루틴이 완료된다.
import asyncio
async def fetch_data():
print("begin fetch data")
await asyncio.sleep(1)
print("end fetch data")
return "fetched data"
async def main():
coroutine = fetch_data()
task = asyncio.create_task(coroutine)
print("task created: ", task)
print("task done: ", task.done())
result = await task
print("await result: ", result)
print("task done: ", task.done())
print("task.result(): ", task.result())
if __name__ == "__main__":
main_coroutine = main()
asyncio.run(main_coroutine)
위 코드를 실행하면 다음과 같은 로그를 볼 수 있다.
- 코루틴의 반환 값이 태스크 객체의 result 값으로 저장된 것을 볼 수 있다.
task created: <Task pending name='Task-2' coro=<fetch_data() running at /Users/junhyunny/Desktop/action-in-blog/example-03.py:4>>
task done: False
begin fetch data
end fetch data
await result: fetched data
task done: True
task.result(): fetched data
생성한 task 객체가 작업을 완료하기 전에 main 코루틴이 정말 대기 상태(suspend)에 진입했을까? main 코루틴 중간에 await asyncio.sleep(0) 함수를 추가하면 알 수 있다.
import asyncio
async def fetch_data():
print("begin fetch data")
await asyncio.sleep(1)
print("end fetch data")
return "fetched data"
async def main():
coroutine = fetch_data()
task = asyncio.create_task(coroutine)
print("before await sleep 0 second")
await asyncio.sleep(0)
print("after await sleep 0 second")
print("before await task")
await task
print("after await task")
if __name__ == "__main__":
main_coroutine = main()
asyncio.run(main_coroutine)
fetch_data 코루틴을 태스크 객체로 만들었기 때문에 이벤트 루프에서 스케줄링 중이다. 그렇기 때문에 main 코루틴이 await asyncio.sleep(0)에 의해 중단되면 즉시 fetch_data 코루틴이 실행된다. 위 코드를 실행하면 아래와 같은 로그를 볼 수 있다.
- “before await sleep 0 second” 로그와 “after await sleep 0 second” 로그 사이에 잠시 fetch_data 코루틴이 실행된 것을 확인할 수 있다.
before await sleep 0 second
begin fetch data
after await sleep 0 second
before await task
end fetch data
after await task
이번엔 태스크로 만들지 않고 코루틴 그대로 사용해보면 어떨까?
import asyncio
async def fetch_data():
print("begin fetch data")
await asyncio.sleep(1)
print("end fetch data")
return "fetched data"
async def main():
coroutine = fetch_data()
print("before await sleep 0 second")
await asyncio.sleep(0)
print("after await sleep 0 second")
print("before await coroutine")
await coroutine
print("after await coroutine")
if __name__ == "__main__":
main_coroutine = main()
asyncio.run(main_coroutine)
fetch_data 코루틴을 태스크로 만들지 않으면 이벤트 루프에 의해 스케줄링 되고 있지 않기 때문에 main 코루틴이 대기 상태로 빠진다고 해서 실행되지 않는다. main 코루틴의 서브 코루틴으로써 순차적으로 실행된다.
before await sleep 0 second
after await sleep 0 second
before await coroutine
begin fetch data
end fetch data
after await coroutine
5. How to restart at the same position?
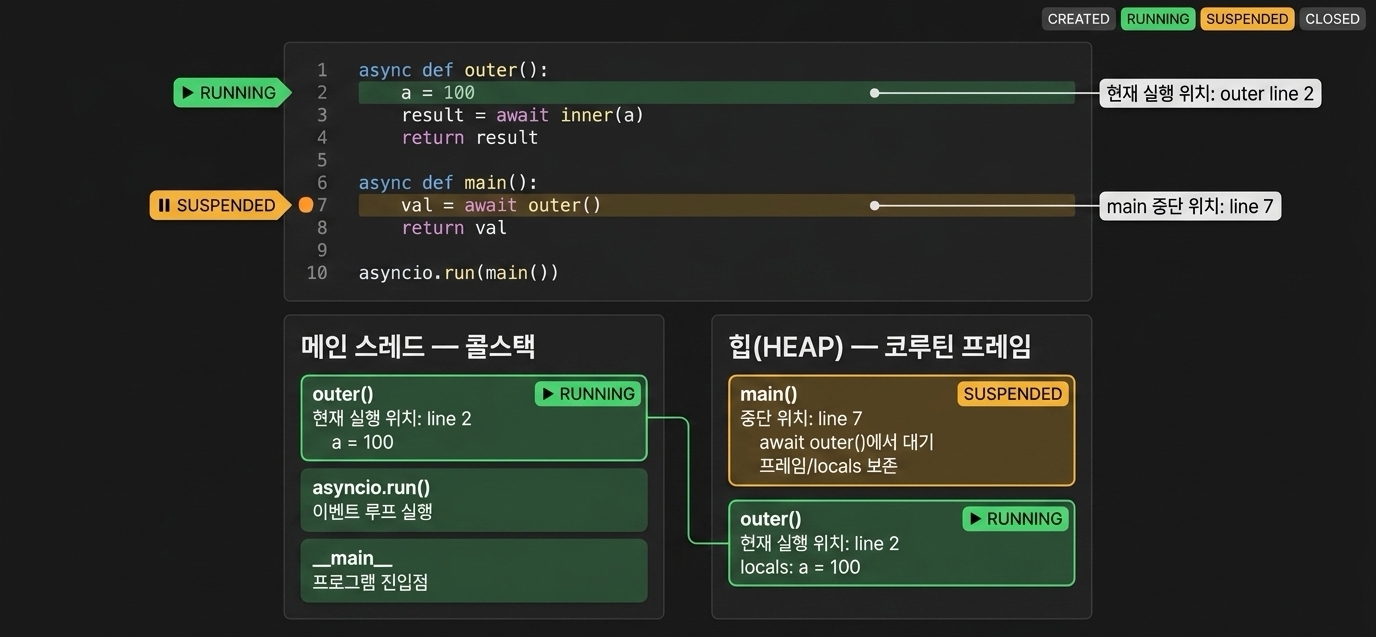
코루틴이나 태스크나 await 키워드를 만났을 때 어떻게 중간에 멈추고 다시 그 자리로 복귀해서 실행될 수 있을까? 이전 파이썬 제너레이터(Python Generator) 글에서 다뤘던 개념과 동일하다. 파이썬 컴파일러는 함수 내부에 yield 키워드가 있을 때 제너레이터 객체를 힙(heap) 메모리에 생성한다. 힙 메모리에 생성된 제너레이터 객체 구조체(PyGenObject) 내부에는 실행 프레임(_PyInterpreterFrame) 객체가 내장되어 로컬 변수, 글로벌 변수, 평가 스택, 명령어 포인터(instruction pointer) 등을 저장하고 관리한다.
코루틴이 await 키워드를 만났을 때 스스로 제어권을 이벤트 루프에 반환하고, 다시 실행되었을 때 이전 위치부터 시작할 수 있는 핵심적인 이유는 await 키워드가 내부적으로 제네레이터의 yield from 메커니즘을 기반으로 동작하며, 실행 중이던 프레임(상태)을 힙 메모리에 보존하기 때문이다. 코루틴 내부에서 await 키워드를 만나면 내부적으로 yield 문을 만나게 된다.
yield 문이 실행되면 코루틴은 자신의 로컬 변수, 내부 평가 스택, 그리고 다음에 실행할 바이트코드의 위치를 기억하는 명령어 포인터 등의 실행 상태를 콜 스택에서 제거하는 대신 힙 메모리의 프레임 객체(PyFrameObject)에 보존한다. 실행 상태가 안전하게 동결(freeze)되면서 코루틴의 실행이 일시 중지되고, yield 문이 발생시킨 값이 호출 체인을 타고 바깥으로 전파되어 최종 호출자인 이벤트 루프로 제어권이 넘어간다.
제어권을 넘겨받은 이벤트 루프는 다른 코루틴을 스케줄링하여 실행하다가, 기다리던 작업이나 I/O가 완료되면 멈춰있던 코루틴의 send() 함수를 호출한다. 그러면 힙에 보존되어 있던 프레임을 다시 가져와, 기록해둔 명령어 포인터의 위치부터 실행을 재개한다.
TEST CODE REPOSITORY
REFERENCE
- https://docs.python.org/3/reference/datamodel.html
- https://peps.python.org/pep-0492/
- https://semfionetworks.com/blog/multi-threading-vs-multi-processing-programming-in-python/
- https://medium.com/@yashwanthnandam/a-beginners-guide-to-python-s-asyncio-lets-get-async-ing-b2c9c81557cd
- https://medium.com/delivus/understanding-pythons-asyncio-a-deep-dive-into-the-event-loop-89a6c5acbc84?
- https://probehub.tistory.com/82
- https://ks1171-park.tistory.com/119
- https://realpython.com/introduction-to-python-generators/
댓글남기기