


JPA @EntityGraph 애너테이션과 데이터 중복 제거 현상
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
JPA N+1 Problem 글을 작성할 때 @EntityGraph 애너테이션을 사용하면 추가적인 처리 없이도 자동적으로 중복된 엔티티(entity)들이 제거되는 현상을 발견했다. 당시에 이 현상에 대해 궁금하여 깃허브(GitHub)와 스택 오버플로우(StackOverflow)에 동일한 문의를 남겼는데, 최근 스택 오버플로우를 통해 얻은 답변을 이번 글에서 공유한다.
1. 중복 제거 현상
스택 오버플로우 답변을 보기 전에 @EntityGraph 애너테이션 사용 시 중복이 제거되는 현상에 대해 자세히 살펴보자. 다음과 같은 데이터가 존재한다고 가정한다. 아래는 Post 테이블이다.
| post.id | post.content | post.title |
|---|---|---|
| 1 | this is the first post. | first post |
Reply 테이블은 다음과 같이 생겼다.
| reply.id | reply.content | reply.post_id |
|---|---|---|
| 1 | first-reply-1 | 1 |
| 2 | first-reply-2 | 1 |
| 3 | first-reply-3 | 1 |
| 4 | first-reply-4 | 1 |
| 5 | first-reply-5 | 1 |
| 6 | first-reply-6 | 1 |
| 7 | first-reply-7 | 1 |
| 8 | first-reply-8 | 1 |
| 9 | first-reply-9 | 1 |
| 10 | first-reply-10 | 1 |
Post 테이블과 Reply 테이블은 1-N 관계이며 이너 조인(inner join) 쿼리를 수행하면 다음과 같은 결과를 얻을 수 있다.
- Post 테이블을 기준으로 Reply 테이블을 조인(join)하여 쿼리를 수행한다.
- Reply 테이블로부터 얻은 데이터는 모두 다르지만, Post 테이블로부터 얻는 데이터는 모두 중복이다.
- Post 테이블의 아이디가
1인 데이터를 기준으로 10건의 데이터가 조회된다.
select *
from test.post inner join test.reply on test.post.id = test.reply.post_id;
| post.id | post.content | post.title | reply.id | reply.content | reply.post_id |
|---|---|---|---|---|---|
| 1 | this is the first post. | first post | 1 | first-reply-1 | 1 |
| 1 | this is the first post. | first post | 2 | first-reply-2 | 1 |
| 1 | this is the first post. | first post | 3 | first-reply-3 | 1 |
| 1 | this is the first post. | first post | 4 | first-reply-4 | 1 |
| 1 | this is the first post. | first post | 5 | first-reply-5 | 1 |
| 1 | this is the first post. | first post | 6 | first-reply-6 | 1 |
| 1 | this is the first post. | first post | 7 | first-reply-7 | 1 |
| 1 | this is the first post. | first post | 8 | first-reply-8 | 1 |
| 1 | this is the first post. | first post | 9 | first-reply-9 | 1 |
| 1 | this is the first post. | first post | 10 | first-reply-10 | 1 |
이런 현상은 JPA를 사용하더라도 똑같이 발생한다. JPA에서 발생하는 N+1 문제를 해결하기 위해 사용하는 JOIN FETCH 쿼리를 수행하면 다음과 같은 결과를 얻는다. 코드는 아래와 같다.
- Post 엔티티를 기준으로 FETCH JOIN 쿼리를 수행한다.
@Query(value = "SELECT p FROM Post p JOIN FETCH p.replies WHERE p.title = :title")
List<Post> findByTitleFetchJoinWithoutDistinct(String title);
위 코드가 실행되면 Post 테이블을 기준으로 INNER JOIN 쿼리를 수행한다.
select post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
inner join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
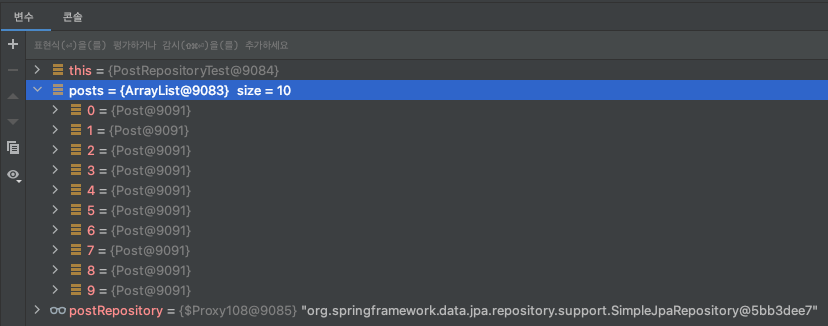
위 메서드가 실행된 후 반환된 결과를 디버깅 모드로 살펴보면 다음과 같다.
- Post 테이블과 Reply 테이블이 조인하면서 동일한 Post 엔티티 객체가 리스트에 10개 저장된다.
위와 같은 현상을 방지하기 위한 두 가지 방법이 있다.
- DISTINCT 키워드 사용
- Java Set 자료구조 사용
JPQL(Java Persistence Query Language) 쿼리에 DISTINCT 키워드 추가하여 중복된 결과를 제거한다.
@Query(value = "SELECT DISTINCT p FROM Post p JOIN FETCH p.replies WHERE p.title = :title")
List<Post> findDistinctByTitleFetchJoin(String title);
중복되는 객체가 담기지 않도록 결과 값에 Set 자료구조를 사용한다.
@Query(value = "SELECT p FROM Post p JOIN FETCH p.replies WHERE p.title = :title")
Set<Post> findByTitleFetchJoin(String title);
이번엔 N+1 문제의 또 다른 해결책인 @EntityGraph 애너테이션을 살펴보자. @EntityGraph 애너테이션을 추가한 코드는 다음과 같다.
@EntityGraph애너테이션의attributePaths속성을 통해 Post 엔티티와 함께 조회할 필드를 지정한다.
@EntityGraph(attributePaths = {"replies"})
@Query(value = "SELECT p FROM Post p WHERE p.title = :title")
List<Post> findByTitleEntityGraphWithoutDistinct(String title);
위 메소드가 실행되면 다음과 같은 쿼리가 실행된다.
- Post 테이블을 기준으로
LEFT OUTER JOIN쿼리를 수행한다.
select post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
left outer join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
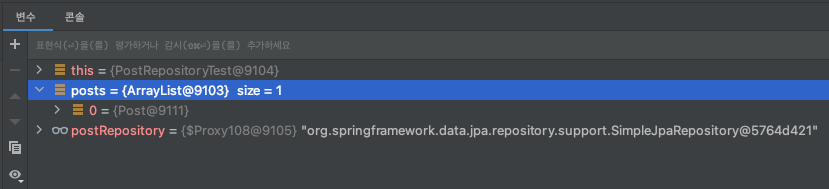
중복 제거를 위한 DISTINCT 키워드 혹은 Set 자료구조 사용하지 않았음에도 자동으로 중복이 제거되어 있다. 위 메서드가 실행된 후 반환된 결과를 디버깅 모드로 살펴보면 다음과 같다.
LEFT OUTER JOIN을 수행하였고, 별도의 중복 처리를 하지 않았음에도 Post 엔티티 객체가 리스트에 1개 저장된다.
2. StackOverflow 답변
@EntityGraph 사용 시 중복 객체들이 제거되는 현상의 원인이 궁금하여 스택 오버플로우에 질문을 올리고 약 7개월만에 답변을 얻었다. 영원히 묻힐뻔한 질문이었지만, 나와 동일한 의문을 가진 사용자가 대신 바운티(bounty)를 걸어줬다. 바운티가 걸리니 2일만에 답변이 달렸다.
- 엔티티 그래프는 하이버네이트(hibernate) 프레임워크 내부에서 기본적으로 중복 처리를 수행한다.
- 5.2.10 version HHH-11569에서 추가되었다.
- HQL(Hibernate Query Language)나 JPQL 사용 시
PASS_DISTINCT_THROUGH힌트를 사용하면 동일한 효과를 얻을 수 있다.

실제 코드를 살펴보자. QueryTranslatorImpl 클래스의 list 메서드에서 엔티티 중복이 제거된다.
getEntityGraphQueryHint메서드 수행 시 결과가null이 아닌 경우 중복을 제거한다.hasLimit값이나query.getSelectClause().isDistinct()메서드 수행 결과와 상관 없이 중복이 제거된다.
IdentitySet클래스를 통해 중복을 제거한다.
package org.hibernate.hql.internal.ast;
// ... import dependencies
public class QueryTranslatorImpl implements FilterTranslator {
// ...
public List list(SharedSessionContractImplementor session, QueryParameters queryParameters) throws HibernateException {
// ...
final boolean needsDistincting = (
query.getSelectClause().isDistinct() ||
getEntityGraphQueryHint() != null || //In case query has Entity Graph HINT applies distincting of result records
hasLimit )
&& containsCollectionFetches();
// ...
List results = queryLoader.list( session, queryParametersToUse );
if ( needsDistincting ) {
int includedCount = -1;
// NOTE : firstRow is zero-based
int first = !hasLimit || queryParameters.getRowSelection().getFirstRow() == null
? 0
: queryParameters.getRowSelection().getFirstRow();
int max = !hasLimit || queryParameters.getRowSelection().getMaxRows() == null
? -1
: queryParameters.getRowSelection().getMaxRows();
List tmp = new ArrayList();
IdentitySet distinction = new IdentitySet();
for ( final Object result : results ) {
if ( !distinction.add( result ) ) {
continue;
}
includedCount++;
if ( includedCount < first ) {
continue;
}
tmp.add( result );
// NOTE : ( max - 1 ) because first is zero-based while max is not...
if ( max >= 0 && ( includedCount - first ) >= ( max - 1 ) ) {
break;
}
}
results = tmp;
}
return results;
}
}
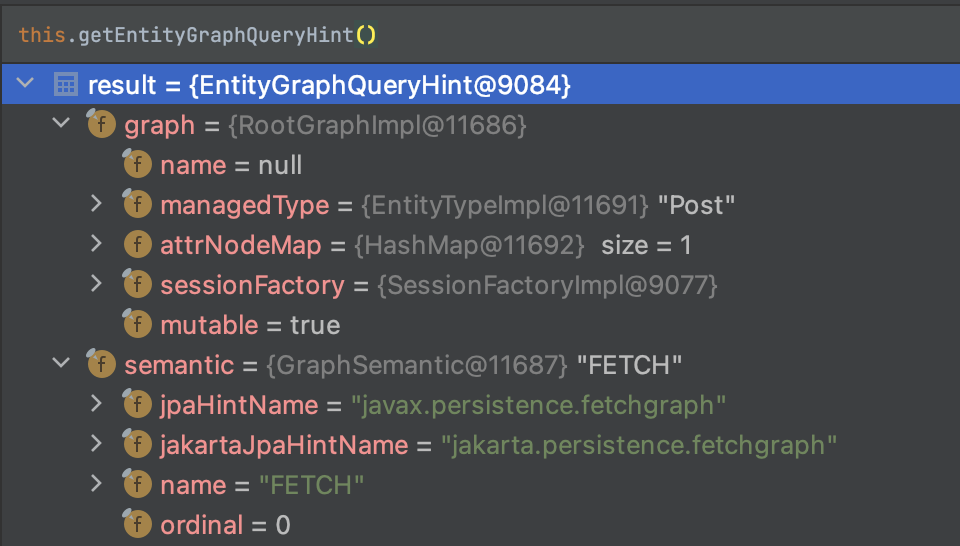
해당 코드 위치를 디버깅 모드로 살펴봤다. 아래 그림은 getEntityGraphQueryHint 메서드 수행 결과다.
@EntityGraph애너테이션을 사용하면"javax.persistence.fetchgraph"라는 힌트가 적용되면서EntityGraphQueryHint객체를 생성한다.- 디버깅 추적을 통해 확인한 힌트 생성과 연관된 클래스들은 다음과 같다.
- org.hibernate.query.internal.AbstractProducedQuery
- org.hibernate.engine.query.spi.EntityGraphQueryHint
- org.hibernate.hql.internal.ast.QueryTranslatorImpl
댓글남기기