


JPA N+1 문제
RECOMMEND NEXT POSTS
0. 들어가면서
클린 코드를 읽다 보니 이런 문구가 있었다.
우리 모두는 자신이 짠 쓰레기 코드를 쳐다보며 나중에 손보겠다고 생각한 경험이 있다. 우리 모두는 대충 짠 프로그램이 돌아간다는 사실에 안도감을 느끼며 그래도 안 돌아가는 프로그램보다 돌아가는 쓰레기가 좋다고 스스로를 위로한 경험이 있다. 다시 돌아와 나중에 정리하겠다고 다짐했었다. 물론 그 시절 우리는 르블랑의 법칙(leblanc’s law)을 몰랐다.
나중은 결코 오지 않는다.
책을 읽고 나니 이전 프로젝트에서 JPA N+1 현상 때문에 성능 문제가 있었던 코드가 떠올랐다. 갑자기 이를 개선하고 싶어졌다.
문제가 있는 코드에 대한 테스트를 작성해 나가면서 관련 기능을 천천히 고쳐 나가는 일은 생각보다 재미있었다. 성능을 개선하는 과정을 통해 몇 가지를 배웠는데, JPA N+1 현상과 관련된 내용을 정리해 놓지 않았기 때문에 공부할 겸 글로 정리하였다. 이번 포스트에서는 @OneToMany, @ManyToOne 애너테이션을 기준으로 이야기를 진행한다.
1. JPA N+1 문제
@OneToOne, @OneToMany, @ManyToOne 같은 애너테이션으로 엔티티 사이에 관계가 형성되어 있을 때 불필요한 쿼리가 추가로 수행되는 현상을 의미한다. 아래 이미지를 보면 Post 엔티티와 Reply 엔티티는 1 대 N 관계이다.
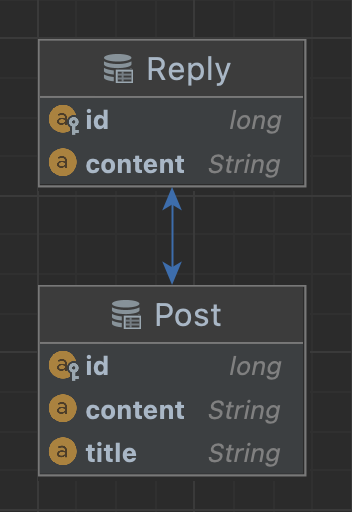
JPA findBy- 메서드를 사용하여 1개의 Post 엔티티를 조회하면 쿼리가 총 2회 수행된다. 지연 로딩(lazy loading)인 경우에는 해당 객체를 사용했다고 가정한다.
- Post 엔티티를 조회하는 쿼리 1회
- Reply 엔티티를 조회하는 쿼리 1회
Hibernate: select post0_.id as id1_0_, post0_.content as content2_0_, post0_.title as title3_0_ from post post0_ where post0_.title=? limit ?
Hibernate: select replies0_.post_id as post_id3_1_0_, replies0_.id as id1_1_0_, replies0_.id as id1_1_1_, replies0_.content as content2_1_1_, replies0_.post_id as post_id3_1_1_ from reply replies0_ where replies0_.post_id=?
만약 2개의 Post 엔티티를 조회하면 쿼리는 총 3회 수행된다.
- 2개의 Post 엔티티를 조회하는 쿼리 1회
- (각 Post 엔티티별로 Reply 엔티티를 조회하는 쿼리 1회) * (Post 엔티티 개수 2개) = 2회
Hibernate: select post0_.id as id1_0_, post0_.content as content2_0_, post0_.title as title3_0_ from post post0_
Hibernate: select replies0_.post_id as post_id3_1_0_, replies0_.id as id1_1_0_, replies0_.id as id1_1_1_, replies0_.content as content2_1_1_, replies0_.post_id as post_id3_1_1_ from reply replies0_ where replies0_.post_id=?
Hibernate: select replies0_.post_id as post_id3_1_0_, replies0_.id as id1_1_0_, replies0_.id as id1_1_1_, replies0_.content as content2_1_1_, replies0_.post_id as post_id3_1_1_ from reply replies0_ where replies0_.post_id=?
만약 N개의 Post 엔티티를 조회하면 쿼리는 총 N+1회 수행된다.
2. N+1 문제 해결하기
N+1 문제를 살펴보았으니 이를 해결할 수 있는 방법을 찾아보자. 우선 테스트에 사용할 엔티티를 살펴보고, 다음으로 해결 방법을 알아본다. Post 엔티티는 다음과 같이 구현했다.
package blog.in.action.post;
import blog.in.action.reply.Reply;
import lombok.*;
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Builder
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column
private String title;
@Column
private String content;
@OneToMany(mappedBy = "post")
private List<Reply> replies;
public void addReply(Reply reply) {
if (replies == null) {
replies = new ArrayList<>();
}
replies.add(reply);
}
}
Reply 엔티티 클래스는 다음과 같이 구현했다.
package blog.in.action.reply;
import blog.in.action.post.Post;
import lombok.*;
import javax.persistence.*;
@Builder
@Getter
@Setter
@AllArgsConstructor
@NoArgsConstructor
@Entity
public class Reply {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column
private String content;
@ManyToOne
@JoinColumn(name = "post_id")
private Post post;
}
2.1. join fetch 키워드 사용하기
@Query 애너테이션과 JPQL(Java Persistence Query Language)을 사용하여 fetch 조인(join) 쿼리를 작성한다. fetch 조인은 inner join으로 처리된다. 테스트 코드를 살펴보자.
package blog.in.action.post;
import blog.in.action.reply.Reply;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import javax.persistence.EntityManager;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import static org.assertj.core.api.AssertionsForClassTypes.assertThat;
@DataJpaTest
public class PostRepositoryTest {
@Autowired
private EntityManager em;
@Autowired
private PostRepository postRepository;
Post getPost(String title, String content) {
return Post.builder()
.title(title)
.content(content)
.build();
}
void insertReply(Post post, String content) {
for (int index = 0; index < 10; index++) {
Reply reply = Reply.builder()
.content(content + index)
.post(post)
.build();
post.addReply(reply);
em.persist(reply);
}
}
@BeforeEach
public void setup() {
Post post = getPost("first post", "this is the first post.");
Post secondPost = getPost("second post", "this is the second post.");
postRepository.save(post);
postRepository.save(secondPost);
insertReply(post, "first-reply-");
insertReply(secondPost, "second-reply-");
em.flush();
em.clear();
}
@Test
public void whenFindDistinctByTitleFetchJoin_thenJustOneQuery() {
List<Post> posts = postRepository.findDistinctByTitleFetchJoin("first post");
List<String> replyContents = posts
.stream()
.map(post -> post.getReplies())
.flatMap(replies -> replies.stream())
.map(reply -> reply.getContent())
.collect(Collectors.toList());
assertThat(replyContents.size()).isEqualTo(10);
}
@Test
public void whenFindByTitleFetchJoin_thenJustOneQuery() {
Set<Post> posts = postRepository.findByTitleFetchJoin("first post");
List<String> replyContents = posts
.stream()
.map(post -> post.getReplies())
.flatMap(replies -> replies.stream())
.map(reply -> reply.getContent())
.collect(Collectors.toList());
assertThat(replyContents.size()).isEqualTo(10);
}
}
위 테스트 코드와 관련된 구현 코드를 살펴보자.
findDistinctByTitleFetchJoin메서드- 반환 타입이
List - 쿼리 결과 DISTINCT 처리
- 반환 타입이
findByTitleFetchJoin메서드- 반환 타입이
Set
- 반환 타입이
package blog.in.action.post;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import java.util.List;
import java.util.Set;
public interface PostRepository extends JpaRepository<Post, Long> {
@Query(value = "SELECT DISTINCT p FROM Post p JOIN FETCH p.replies WHERE p.title = :title")
List<Post> findDistinctByTitleFetchJoin(String title);
@Query(value = "SELECT p FROM Post p JOIN FETCH p.replies WHERE p.title = :title")
Set<Post> findByTitleFetchJoin(String title);
}
테스트를 실행했을 때 로그가 어떻게 출력되는지 살펴보자. 먼저 whenFindDistinctByTitleFetchJoin_thenJustOneQuery 테스트를 실행했을 때 쿼리를 살펴보자.
- inner join 쿼리가 수행되면서 한 번에 Reply 엔티티 정보를 조회한다.
select distinct post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
inner join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
다음 whenFindByTitleFetchJoin_thenJustOneQuery 테스트를 실행했을 때 쿼리는 다음과 같다.
- inner join 쿼리가 수행되면서 한 번에 Reply 엔티티 정보를 조회한다.
select post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
inner join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
2.2. @EntityGraph 애너테이션 사용
@EntityGraph 애너테이션을 사용하여 조인할 대상 필드를 지정한다. 해당 애너테이션에 포함된 필드는 쿼리 시 left outer join 대상이 된다. 다음과 같이 테스트 코드를 작성했다.
package blog.in.action.post;
import blog.in.action.reply.Reply;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.orm.jpa.DataJpaTest;
import javax.persistence.EntityManager;
import java.util.List;
import java.util.Set;
import java.util.stream.Collectors;
import static org.assertj.core.api.AssertionsForClassTypes.assertThat;
@DataJpaTest
public class PostRepositoryTest {
@Autowired
private EntityManager em;
@Autowired
private PostRepository postRepository;
Post getPost(String title, String content) {
return Post.builder()
.title(title)
.content(content)
.build();
}
void insertReply(Post post, String content) {
for (int index = 0; index < 10; index++) {
Reply reply = Reply.builder()
.content(content + index)
.post(post)
.build();
post.addReply(reply);
em.persist(reply);
}
}
@BeforeEach
public void setup() {
Post post = getPost("first post", "this is the first post.");
Post secondPost = getPost("second post", "this is the second post.");
postRepository.save(post);
postRepository.save(secondPost);
insertReply(post, "first-reply-");
insertReply(secondPost, "second-reply-");
em.flush();
em.clear();
}
@Test
public void whenFindDistinctByTitleEntityGraph_thenJustOneQuery() {
List<Post> posts = postRepository.findDistinctByTitleEntityGraph("first post");
List<String> replyContents = posts
.stream()
.map(post -> post.getReplies())
.flatMap(replies -> replies.stream())
.map(reply -> reply.getContent())
.collect(Collectors.toList());
assertThat(posts.size()).isEqualTo(1);
assertThat(replyContents.size()).isEqualTo(10);
}
@Test
public void whenFindByTitleEntityGraph_thenJustOneQuery() {
Set<Post> posts = postRepository.findByTitleEntityGraph("first post");
List<String> replyContents = posts
.stream()
.map(post -> post.getReplies())
.flatMap(replies -> replies.stream())
.map(reply -> reply.getContent())
.collect(Collectors.toList());
assertThat(posts.size()).isEqualTo(1);
assertThat(replyContents.size()).isEqualTo(10);
}
}
위 테스트 코드와 관련된 구현 코드를 살펴보자.
findDistinctByTitleEntityGraph메서드- 반환 타입이
List - 쿼리 결과 DISTINCT 처리
@EntityGraph애너테이션에 함께 조회할 엔티티 정보 표시
- 반환 타입이
findByTitleEntityGraph메서드- 반환 타입이
Set @EntityGraph애너테이션에 함께 조회할 엔티티 정보 표시
- 반환 타입이
public interface PostRepository extends JpaRepository<Post, Long> {
@EntityGraph(attributePaths = {"replies"})
@Query(value = "SELECT DISTINCT p FROM Post p WHERE p.title = :title")
List<Post> findDistinctByTitleEntityGraph(String title);
@EntityGraph(attributePaths = {"replies"})
@Query(value = "SELECT p FROM Post p WHERE p.title = :title")
Set<Post> findByTitleEntityGraph(String title);
}
이제 테스트 실행 결과를 살펴보자. whenFindDistinctByTitleEntityGraph_thenJustOneQuery 테스트 메서드를 실행하면 다음과 같은 쿼리 로그를 볼 수 있다.
- left outer join 쿼리가 수행되면서 한 번에 Reply 엔티티 정보를 조회한다.
select distinct post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
left outer join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
whenFindByTitleEntityGraph_thenJustOneQuery 테스트 메서드를 실행하면 다음과 같은 쿼리 로그를 볼 수 있다.
- left outer join 쿼리가 수행되면서 한 번에 Reply 엔티티 정보를 조회한다.
select post0_.id as id1_0_0_,
replies1_.id as id1_1_1_,
post0_.content as content2_0_0_,
post0_.title as title3_0_0_,
replies1_.content as content2_1_1_,
replies1_.post_id as post_id3_1_1_,
replies1_.post_id as post_id3_1_0__,
replies1_.id as id1_1_0__
from post post0_
left outer join reply replies1_ on post0_.id = replies1_.post_id
where post0_.title = ?
3. 주의사항
테스트를 보면 fetch 조인과 @EntityGraph 애너테이션을 사용하면 inner join과 left outer join 방식을 사용한 쿼리로 데이터를 조회한다. 두 조인 방식 모두 일대다 관계에서 "일"인 테이블을 기준으로 데이터를 조회하면 중복 데이터가 발생한다. 예를 들어, Post 테이블 조회 쿼리와 결과는 다음과 같다.
select * from test.post;
| post.id | post.content | post.title |
|---|---|---|
| 1 | this is the first post. | first post |
Reply 테이블 조회 쿼리와 결과는 다음과 같다.
select * from test.reply;
| reply.id | reply.content | reply.post_id |
|---|---|---|
| 1 | first-reply-1 | 1 |
| 2 | first-reply-2 | 1 |
| 3 | first-reply-3 | 1 |
| 4 | first-reply-4 | 1 |
| 5 | first-reply-5 | 1 |
| 6 | first-reply-6 | 1 |
| 7 | first-reply-7 | 1 |
| 8 | first-reply-8 | 1 |
| 9 | first-reply-9 | 1 |
| 10 | first-reply-10 | 1 |
두 테이블을 inner join으로 조회하면 다음과 같이 데이터가 조회된다.
select *
from test.post inner join test.reply on test.post.id = test.reply.post_id;
| post.id | post.content | post.title | reply.id | reply.content | reply.post_id |
|---|---|---|---|---|---|
| 1 | this is the first post. | first post | 1 | first-reply-1 | 1 |
| 1 | this is the first post. | first post | 2 | first-reply-2 | 1 |
| 1 | this is the first post. | first post | 3 | first-reply-3 | 1 |
| 1 | this is the first post. | first post | 4 | first-reply-4 | 1 |
| 1 | this is the first post. | first post | 5 | first-reply-5 | 1 |
| 1 | this is the first post. | first post | 6 | first-reply-6 | 1 |
| 1 | this is the first post. | first post | 7 | first-reply-7 | 1 |
| 1 | this is the first post. | first post | 8 | first-reply-8 | 1 |
| 1 | this is the first post. | first post | 9 | first-reply-9 | 1 |
| 1 | this is the first post. | first post | 10 | first-reply-10 | 1 |
위처럼 중복되는 데이터 행(row)은 JPA를 이용한 엔티티 조회에도 반영된다. 이런 중복 현상을 없애기 위해서는 메서드의 반환 타입을 Set으로 지정하거나 쿼리 내부에 DISTINCT 키워드를 붙여야 한다. 중복을 없애기 위한 처리를 하지 않으면 아래와 같은 결과를 확인할 수 있다.
- 반환 타입은
List이며, 쿼리 내부에DISTINCT키워드를 붙이지 않은 경우이다. - 결과 리스트에 주소가 같은 엔티티 객체가 10개 담겨서 반환된다.
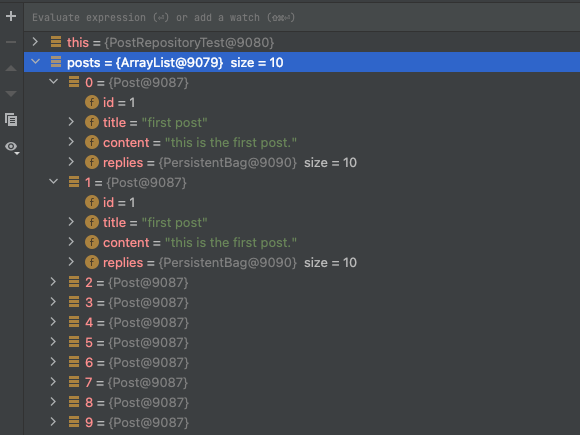
CLOSING
@NamedEntityGraphs 애너테이션을 이용한 해결 방법도 있지만, 참고한 이동욱 님의 블로그를 보면 다음과 같은 내용을 볼 수 있다.
NamedEntityGraphs의 경우 Entity에 관련해서 모든 설정 코드를 추가해야하는데, 개인적으론 Entity가 해야하는 책임에 포함되지 않는다고 생각합니다. A 로직에서는 Fetch전략을 어떻게 가져가야 한다는 것은 해당 로직의 책임이지, Entity의 책임이 아니라고 생각합니다. Entity에선 실제 도메인에 관련 된 코드만 작성하고, 상황에 따라 유동적인 Fetch 전략을 가져가는 것은 전적으로 서비스/레파지토리에서 결정해야하는 일이라고 생각됩니다.
나도 같은 의견이기 때문에 추가로 정리하지 않았다. 혹시 나중에 사용할 일이 생긴다면 그때 관련된 내용을 정리해 보려고 한다.
추가로 @EntityGraph 애너테이션을 사용하면 데이터 중복 현상을 없애기 위한 처리 없이도 정상적으로 엔티티가 조회된다. 반환 타입을 Set으로 지정하지 않아도, 쿼리 내부에 DISTINCT 키워드가 없어도 중복되지 않은 엔티티 리스트가 반환된다. GitHub spring-data-jpa 리포지토리 이슈와 StackOverflow 질문으로 @EntityGraph 애너테이션을 사용할 때 왜 중복 현상이 발생하지 않는지 문의하였다.
- GitHub 이슈 - Why does not @EntityGraph annotation in JPA need to use “distinct” keyword or “Set” data structure?
- StackOverflow 질문 - Why does not @EntityGraph annotation in JPA need to use “distinct” keyword or “Set” data structure?
댓글남기기