


Database Sharding
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
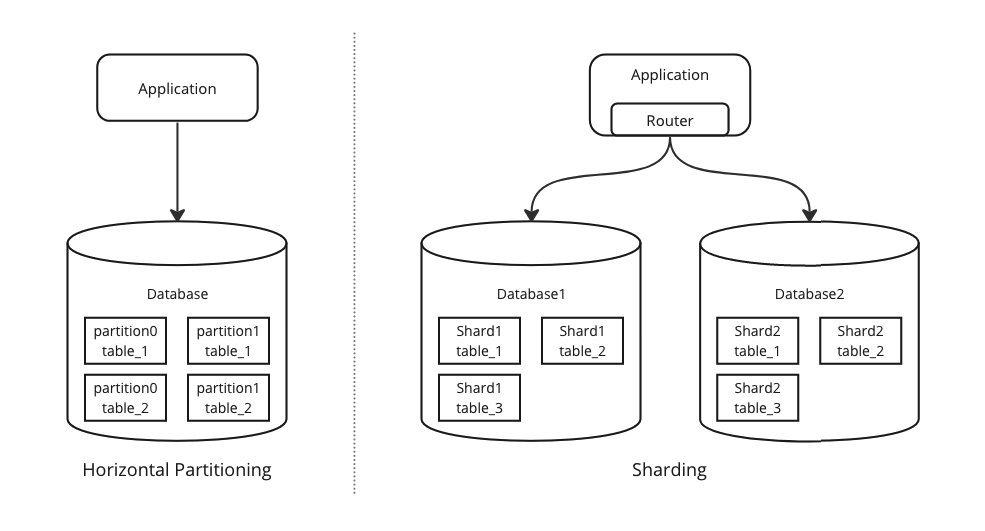
수평 파티셔닝(horizontal partitioning)을 샤딩(sharding)과 혼동하여 사용하는 경우가 많은 것 같습니다. 둘은 비슷한 개념이지만, 다른 의미를 가집니다. 이번 포스트에선 샤딩에 대해 정리하였습니다.
1. Sharding
데이터베이스 수평 파티셔닝의 일종으로 여러 데이터베이스 인스턴스(instance)에 분산 저장하는 것을 의미
수평 파티셔닝은 샤딩이다.는 정확한 표현이 아닙니다.
일반적으로 수평 파티셔닝은 하나의 데이터베이스 인스턴스에서 데이터를 분할하는 기법을 의미합니다.
샤딩은 수평 파티셔닝을 넘어서 여러 개의 독립된 데이터베이스 인스턴스(혹은 노드, 서버)에 데이터를 저장하는 것이 특징입니다.
이때 각 데이터베이스 인스턴스에 저장된 작은 데이터 단위를 샤드(shard)라고 합니다.
샤딩 기법은 데이터를 분산 저장하기 위해 샤드 키(shard key)를 사용합니다. 샤드 키는 특정 필드나 컬럼을 사용합니다. 이를 기준으로 어떤 샤드에 데이터가 저장될지 결정되므로 적절한 샤드 키를 만드는 것이 중요합니다.
- 샤딩은 분산 처리와 확장성을 고려한 데이터베이스 아키텍처입니다.
- 일반적으로 대규모 시스템에서 활용됩니다.
- 데이터베이스 차원의 수평 확장(scale-out)을 의미합니다.
- 예전엔 데이터베이스 수준이 아닌 애플리케이션 수준에서 샤드를 구분하여 사용하기 위한 구현이 필요했습니다.
- 최근엔 플랫폼 차원에서 샤드를 구분하여 사용하기 위한 기능을 제공합니다.
- 애플리케이션 서버에서 제공 -
Hibernate Shards - 미들 티어(middle tier)에서 제공 -
Spock Proxy,Gizzard - 데이터베이스에서 제공 -
MongoDB
- 애플리케이션 서버에서 제공 -
1.1. Pros and Cons
샤딩 기법은 다음과 같은 장점들을 제공합니다.
- 데이터베이스의 확장성을 향상시킵니다.
- 데이터가 여러 개의 노드에 분산되므로 각 노드는 독립적으로 작동할 수 있습니다.
- 데이터베이스의 용량과 처리량을 필요에 따라 비교적 쉽게 확장할 수 있습니다.
- 데이터를 분산하여 병렬 처리를 가능하게 합니다.
- 각 샤드는 독립적으로 동작하므로 여러 샤드에서 작업을 동시에 처리할 수 있습니다.
- 데이터를 여러 개의 노드에 분산하였기 때문에 부하가 분산됩니다.
- 트래픽이 집중되는 단일 노드로 인한 병목 현상을 줄일 수 있습니다.
다음과 같은 단점들이 존재합니다.
- 여러 샤드 간의 데이터 이동이 필요한 조인 연산은 복잡성이 증가합니다.
- 샤드 키(shard key)를 사용하지 않은 조인은 모든 샤드를 스캔해야 할 수 있습니다.
- 데이터가 여러 샤드에 분산되어 있으므로 데이터의 일관성을 유지하기 위해 추가적인 동기화 작업이 필요할 수 있습니다.
- 데이터를 여러 샤드에 복제하여 데이터의 가용성(availability)을 보장해야 할 수 있습니다.
- 데이터가 하나의 샤드에 몰리는 경우 부하가 집중될 수 있습니다.
- 적절하지 않은 샤딩 키가 사용되면 데이터가 오히려 집중될 수 있습니다.
- 데이터베이스 인스턴스 성능을 비대칭적으로 설계하는 방법으로 부하 집중을 대응할 수 있습니다.
- 여러 개의 데이터베이스 인스턴스들과 샤드가 존재하기 때문에 관리가 복잡합니다.
2. Sharding Types
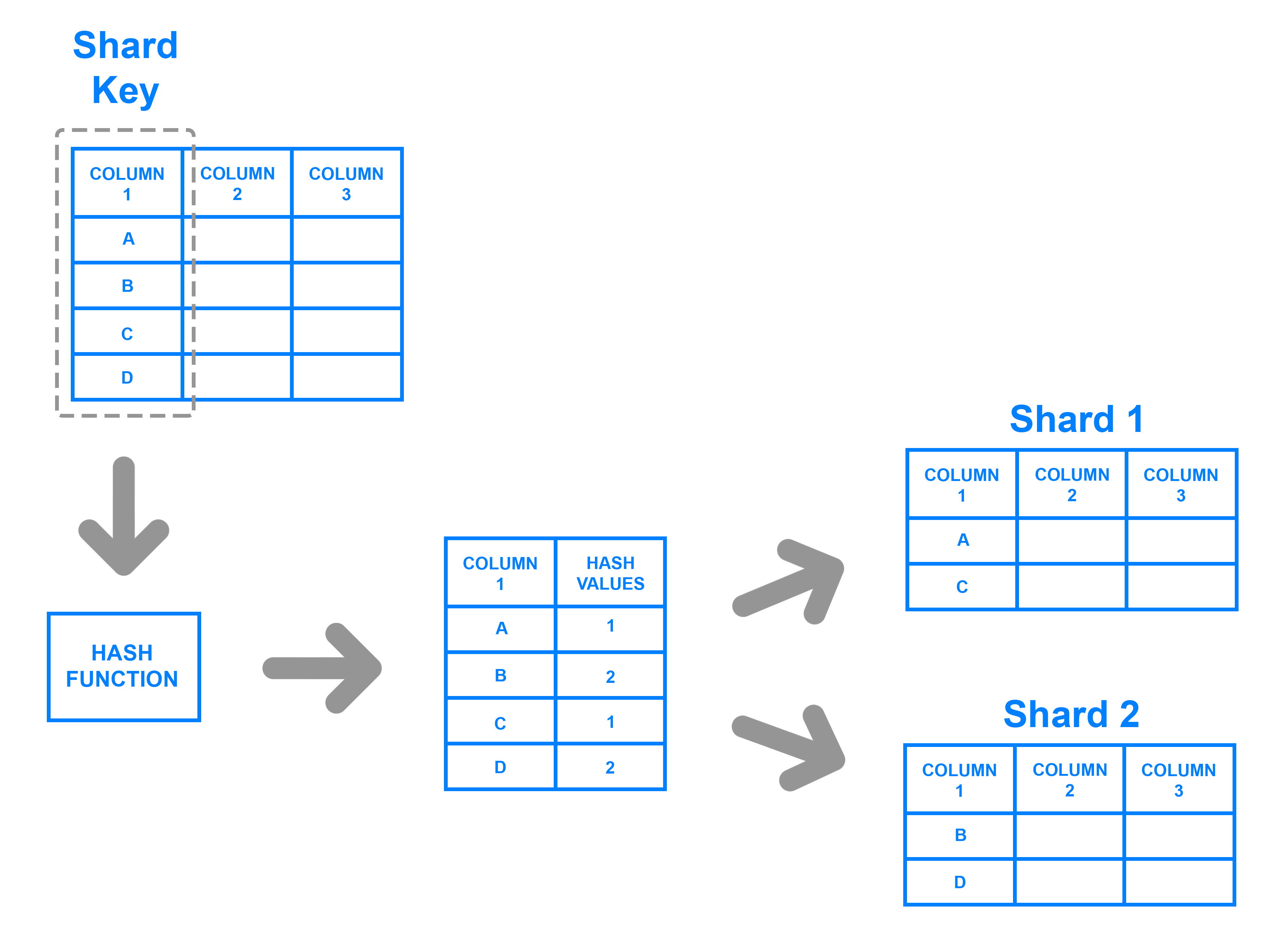
2.1. Hash Sharding
엔티티의 특정 컬럼 데이터와 해시 함수를 사용해 샤드를 구분합니다. 해시 함수로 모듈라(modular) 연산을 사용할 수 있습니다. 해시 크기는 데이터베이스 개수로 정합니다.
다음과 같은 사항들을 유의해야합니다.
- 해시 값을 사용하기 때문에 샤드에 고르게 데이터가 분산됩니다.
- 특정 데이터를 기준으로 연속적인 데이터를 조회하는 범위 쿼리의 성능은 저하될 수 있습니다.
- 데이터베이스가 추가되거나 삭제되는 경우 해시 함수의 변경과 저장된 데이터 재정렬이 필요합니다.
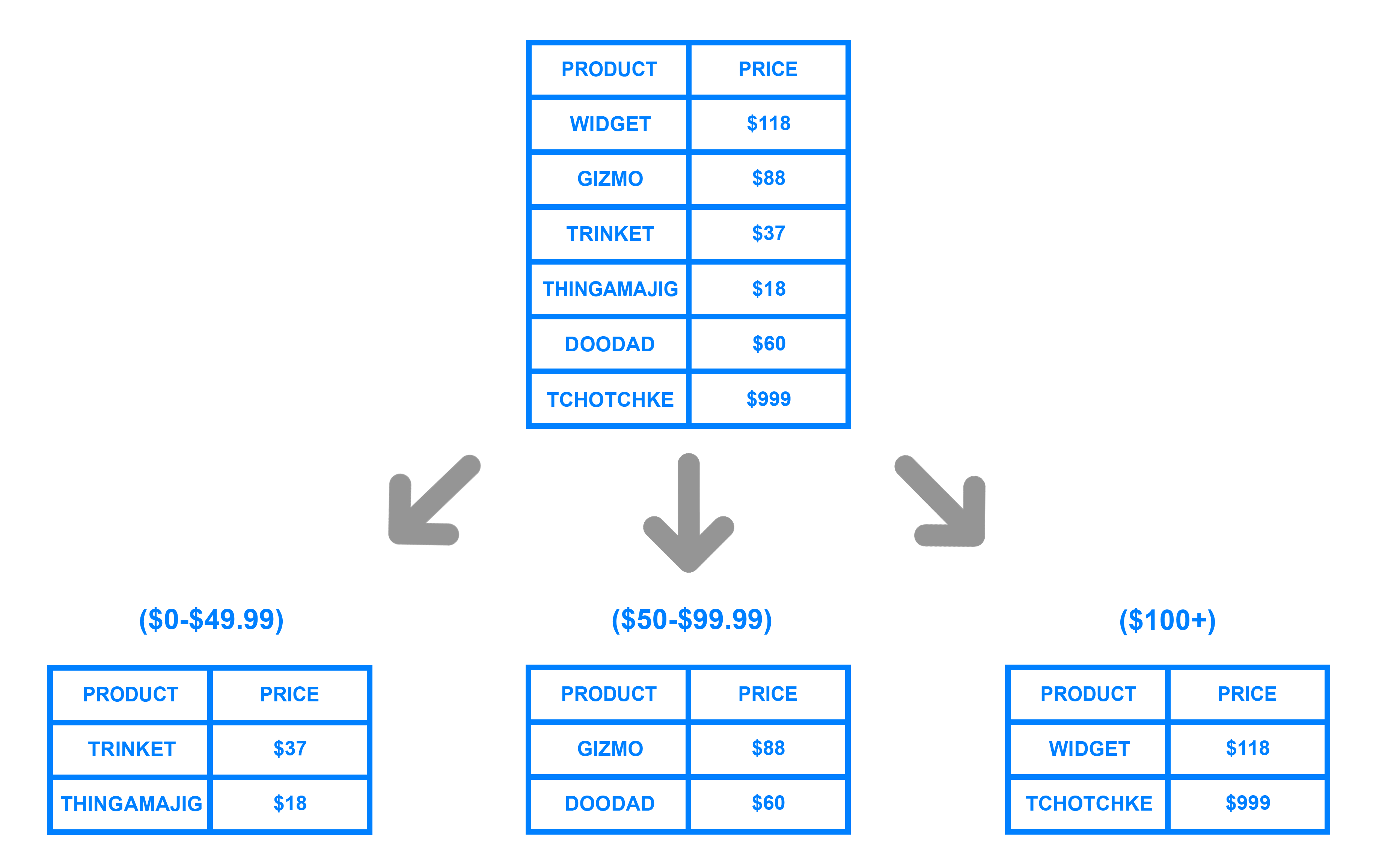
2.2. Range Sharding
엔티티의 특정 컬럼 데이터가 속하는 범위를 기준으로 샤드를 구분합니다. 예를 들면 날짜, 숫자 등을 기준으로 데이터를 분할하는 방식입니다.
다음과 같은 사항들을 유의해야합니다.
- 연속적인 범위에 따라 데이터를 분산하므로 연속적인 데이터를 접근할 때 성능이 좋습니다.
- 데이터베이스가 추가되거나 삭제될 때 범위 조정과 데이터 재정렬이 필요하지만, 해시 샤딩에 비해 비교적 비용이 낮습니다.
- 데이터가 고르게 분산되어 저장되지 않을 수 있습니다.
REFERENCE
- https://en.wikipedia.org/wiki/Shard_%28database_architecture%29
- https://aws.amazon.com/ko/what-is/database-sharding/
- https://d2.naver.com/helloworld/14822
- https://www.digitalocean.com/community/tutorials/understanding-database-sharding
- https://bcho.tistory.com/670
- https://techblog.woowahan.com/2687/
- https://hudi.blog/db-partitioning-and-sharding/
- https://code-lab1.tistory.com/202
- https://cinema4dr12.tistory.com/508
댓글남기기