


Database Partitioning
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
데이터베이스는 볼륨이 커질수록 읽기/쓰기 성능이 감소합니다. 성능 향상을 위해 데이터를 분할하여 저장하는 파티셔닝(partitioning) 혹은 샤딩(sharding)이라는 기법을 사용합니다. 이번 포스트는 파티셔닝 컨셉에 대해서 정리하였습니다.
1. Partitioning
파티션(partition)은 테이블을 논리적으로는 하나이지만, 물리적으로는 여러 개로 분리하여 관리하는 데이터베이스의 기능
데이터를 여러 개의 테이블로 분리하여 관리하는 파티션 기법을 적용하는 것을 파티셔닝(partitioning)이라고 합니다. 대용량의 테이블을 물리적으로 여러 개의 소규모 테이블들로 분산하는 목적으로 주로 사용합니다. 물리적인 데이터 분할이 있더라도 데이터베이스에 접근하는 애플리케이션 입장에선 이를 인지하지 못 합니다.
파티션을 사용하는 이유는 다음과 같습니다.
- 테이블이 너무 커서 인덱스의 크기가 물리적인 메모리보다 훨씬 큰 경우
- 인덱스가 커지면
INSERT,UPDATE,DELETE,SELECT작업도 함께 느려집니다. - 인덱스 크기가 물리적으로 데이터베이스가 사용 가능한 메모리 공간보다 크면 영향을 더 크게 받습니다.
- 인덱스가 커지면
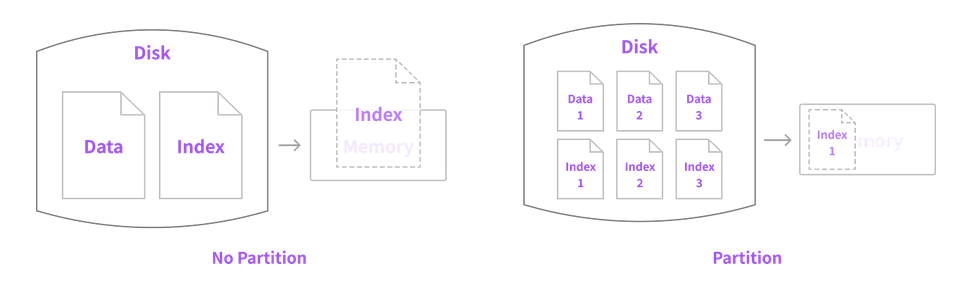
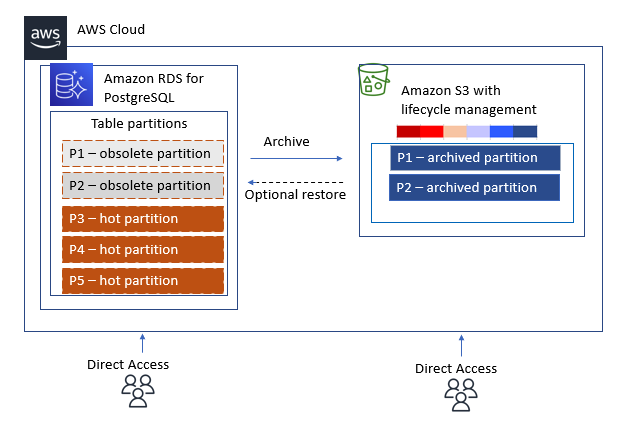
- 데이터 특성상 주기적으로 삭제 작업이 필요한 경우
- 로그 성격의 이력 데이터는 단기간에 대량으로 누적되고 일정 기간이 지나면 쓸모가 없어집니다.
- 시간이 지나면 별도로 아카이빙(archiving)하거나 백업한 후 삭제합니다.
- 불필요해진 데이터를 백업하거나 삭제하는 작업은 일반 테이블에서는 상당히 고부하 작업입니다.
- 파티셔닝을 통해 파티션을 추가하거나 삭제하는 방식으로 간단하게 해결할 수 있습니다.
1.1. Pros and Cons
파티션 기법은 다음과 같은 장점들을 제공합니다.
- 데이터베이스 확장성을 향상시킵니다.
- 새로운 데이터가 추가될 때마다 새로운 파티션을 생성하여 데이터를 분산시킬 수 있습니다.
- 데이터 관리를 용이하게 만들어줍니다.
- 각 파티션 별로 독립적으로 관리될 수 있으며 백업, 복구, 인덱스 생성 등의 작업을 개별적으로 수행할 수 있습니다.
- 데이터 보안과 격리를 향상시킵니다.
- 민감한 데이터를 별도의 파티션으로 분리하여 액세스 제어 및 보안 정책을 적용할 수 있습니다.
다음과 같은 단점들이 존재합니다.
- 파티셔닝 된 테이블 사이의 조인(join) 연산의 복잡성이 증가할 수 있습니다.
- 파티션 키를 사용하지 않는 조인은 전체 파티션을 스캔해야 할 수 있습니다.
- 데이터가 균등하게 파티셔닝되지 않는 경우 특정 파티션에 부하가 집중될 수 있습니다.
- 데이터 분산 전략과 로드 밸런싱 메커니즘을 고려해야 합니다.
- 파티셔닝 된 테이블의 특정 행의 데이터 변경은 해당 행이 위치한 파티션을 식별해야 합니다.
- 데이터 변경 관리의 복잡성이 증가됩니다.
2. Partitioning Method
파티셔닝 방법은 크게 두 가지로 구분됩니다.
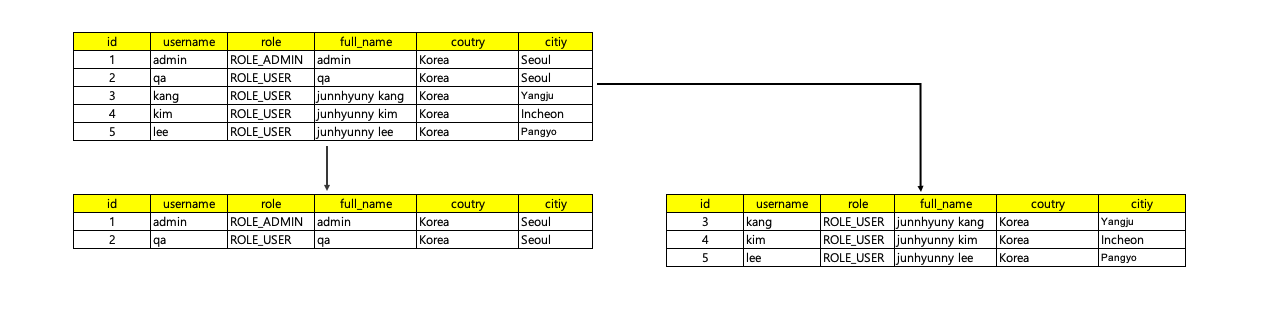
2.1. Horizontal Partitioning
수평 파티셔닝(Horizontal Partitioning)을 먼저 살펴보겠습니다.
- 데이터를 행 단위로 분할하는 방법입니다.
- 일반적으로 분산 저장 기술에서 파티셔닝은 수평 분할을 의미합니다.
- 데이터의 특정 열 값을 기준으로 데이터를 분할합니다.
- 각 파티션에는 특정 범위 또는 조건에 해당하는 행들이 포함됩니다.
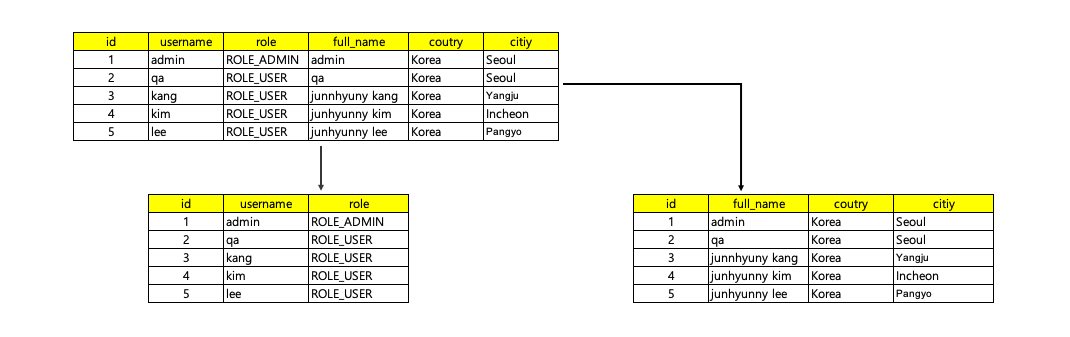
2.1. Vertical Partitioning
- 수직 파티셔닝(Vertical Partitioning)은 데이터를 열 단위로 분할합니다.
- 테이블의 열들이 논리적 혹은 물리적으로 분할되어 각 파티션에는 특정 열 또는 열 그룹으로 포함됩니다.
- 주로 데이터베이스에서 자주 사용하지 않는 열이나 크기가 큰 열을 분리하여 저장 공간을 절약하고 액세스 성능을 개선하는데 사용합니다.
3. Partitioning Types
MySQL을 기준으로 4가지 기본 파티션 기법에 대해 정리하였습니다.
- 레인지 파티션(Range Partition)
- 리스트 파티션(List Partition)
- 해시 파티션(Hash Partition)
- 키 파티션(Key Partition)
3.1. Range Partition
레인지 파티션은 다음과 같은 용도에 사용하는 것이 적합합니다.
- 날짜를 기준으로 데이터거 누적되고 연도나 월 또는 일 단위로 분석하고 삭제해야 하는 경우
- 범위 기반으로 데이터를 여러 파티션에 균등하게 나눌 수 있는 경우
- 파티션 키 위주로 검색이 자주 실행되는 경우
mysql> CREATE TABLE employees (
id INT NOT NULL AUTO_INCREMENT,
first_name VARCHAR(30),
last_name VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
primary key (id, hired)
) PARTITION BY RANGE(YEAR(hired)) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (2001),
PARTITION p2 VALUES LESS THAN MAXVALUE
);
mysql> insert employees (first_name, last_name, hired)
values ('junhyunny', 'kang', '1990-08-15'),
('junhyunny', 'kim', '1995-06-06'),
('junhyunny', 'lee', '2005-06-06');
mysql> SELECT * FROM employees PARTITION (p0);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 1 | junhyunny | kang | 1990-08-15 |
+----+------------+-----------+------------+
mysql> SELECT * FROM employees PARTITION (p1);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 2 | junhyunny | kim | 1995-06-06 |
+----+------------+-----------+------------+
mysql> SELECT * FROM employees PARTITION (p2);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 3 | junhyunny | lee | 2005-06-06 |
+----+------------+-----------+------------+
3.2. List Partition
리스트 파티션은 다음과 같은 용도에 사용하는 것이 적합합니다.
- 파티션 키 값이 코드 값이나 카테고리와 같이 고정적인 경우
- 키 값이 연속되지 않고 정렬 순서와 관계없이 파티션을 해야하는 경우
- 파티션 키 값을 기준으로 레코드의 건수가 균일하고 검색 조건에 파티션 키가 자주 사용되는 경우
mysql> CREATE TABLE product (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(30),
category_id VARCHAR(30) NOT NULL,
primary key (id, category_id)
) PARTITION BY LIST COLUMNS (category_id) (
PARTITION p_appliance VALUES IN ('TV'),
PARTITION p_computer VALUES IN ('Labtop', 'Desktop'),
PARTITION p_sports VALUES IN ('Tennis', 'Soccer', NULL)
);
mysql> insert product (name, category_id)
values ('LG TV', 'TV'),
('MacBook Pro', 'Labtop'),
('Dell Desktop', 'Desktop'),
('Fila Shoes', 'Tennis'),
('Nike Shoes', 'Soccer');
mysql> SELECT * FROM product PARTITION (p_appliance);
+----+-------+-------------+
| id | name | category_id |
+----+-------+-------------+
| 6 | LG TV | TV |
+----+-------+-------------+
mysql> SELECT * FROM product PARTITION (p_computer);
+----+--------------+-------------+
| id | name | category_id |
+----+--------------+-------------+
| 7 | MacBook Pro | Labtop |
| 8 | Dell Desktop | Desktop |
+----+--------------+-------------+
mysql> SELECT * FROM product PARTITION (p_sports);
+----+------------+-------------+
| id | name | category_id |
+----+------------+-------------+
| 9 | Fila Shoes | Tennis |
| 10 | Nike Shoes | Soccer |
+----+------------+-------------+
3.3. Hash Partition
MySQL에서 정의한 해시 함수에 의해 레코드(record)가 저장될 때 파티션을 결정하는 방법입니다.
파티션 표현식의 결과 값을 파티션 개수로 나눈 나머지로 저장될 파티션을 결정합니다.
해시 파티션의 파티션 키는 항상 정수 타입이거나 정수 타입을 반환하는 표현식만 사용 가능합니다.
해시 파티션은 다음과 같은 용도에 사용하는 것이 적합합니다.
- 레인지 파티션이나 리스트 파티션으로 데이터를 균등하게 나누는 것이 어려운 경우
- 테이블의 모든 레코드가 비슷한 사용 빈도를 보이지만 테이블이 너무 커서 파티션을 적용해야하는 경우
-- 파티션 개수를 지정하면 각 파티션의 이름은 기본적으로 p0, p1, p2 ... 같은 규칙으로 생성됩니다.
mysql> CREATE TABLE employees (
id INT NOT NULL AUTO_INCREMENT,
first_name VARCHAR(30),
last_name VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
primary key (id)
) PARTITION BY HASH(id) PARTITIONS 4;
mysql> insert employees (first_name, last_name, hired)
values ('junhyunny', 'kang', '1990-08-15'),
('junhyunny', 'kim', '1995-06-06'),
('junhyunny', 'lee', '2005-06-06');
mysql> SELECT * FROM employees PARTITION (p0);
mysql> SELECT * FROM employees PARTITION (p1);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 1 | junhyunny | kang | 1990-08-15 |
+----+------------+-----------+------------+
1 row in set (0.00 sec)
mysql> SELECT * FROM employees PARTITION (p2);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 2 | junhyunny | kim | 1995-06-06 |
+----+------------+-----------+------------+
mysql> SELECT * FROM employees PARTITION (p3);
+----+------------+-----------+------------+
| id | first_name | last_name | hired |
+----+------------+-----------+------------+
| 3 | junhyunny | lee | 2005-06-06 |
+----+------------+-----------+------------+
3.4. Key Partition
키 파티션은 해시 파티션과 사용법과 특성이 같습니다.
해시 파티션은 해시 값을 계산하여 사용하지만, 키 파티션은 사용자가 명시합니다.
최종적으로 MySQL 서버가 그 값을 MOD 연산을 수행하여 파티션을 결정합니다.
해시 파티션과 다음과 같은 다른 점들이 있습니다.
MySQL서버가 내부적으로 MD5() 함수를 이용해 파티션하기 때문에 파티션 키가 반드시 정수 타입이 아니어도 됩니다.- 해시 파티션에 비해 파티션 간의 레코드를 더 균등하게 분할할 수 있으므로 더 효율적입니다.
mysql> CREATE TABLE department_employees(
department_no CHAR(4) NOT NULL,
employee_no INT NOT NULL,
department_name VARCHAR(30),
employee_name VARCHAR(30),
PRIMARY KEY (department_no, employee_no)
) PARTITION BY KEY(department_no) PARTITIONS 2;
mysql> insert department_employees (department_no, employee_no, department_name, employee_name)
values (1, 1, 'Marketing', 'Junhyunny Kang'),
(2, 2, 'Development', 'Junhyunny Kim'),
(3, 3, 'Design', 'Junhyunny Lee'),
(4, 4, 'Plan', 'Junhyunny Jung'),
(1, 5, 'Marketing', 'Junhyunny Bang'),
(2, 6, 'Development', 'Junhyunny Oh'),
(3, 7, 'Design', 'Junhyunny Choen');
mysql> SELECT * FROM department_employees PARTITION (p0);
+---------------+-------------+-----------------+----------------+
| department_no | employee_no | department_name | employee_name |
+---------------+-------------+-----------------+----------------+
| 2 | 2 | Development | Junhyunny Kim |
| 2 | 6 | Development | Junhyunny Oh |
| 4 | 4 | Plan | Junhyunny Jung |
+---------------+-------------+-----------------+----------------+
mysql> SELECT * FROM department_employees PARTITION (p1);
+---------------+-------------+-----------------+-----------------+
| department_no | employee_no | department_name | employee_name |
+---------------+-------------+-----------------+-----------------+
| 1 | 1 | Marketing | Junhyunny Kang |
| 1 | 5 | Marketing | Junhyunny Bang |
| 3 | 3 | Design | Junhyunny Lee |
| 3 | 7 | Design | Junhyunny Choen |
+---------------+-------------+-----------------+-----------------+
RECOMMEND NEXT POSTS
REFERENCE
- Real MySQL 8.0 (2권)
- https://gngsn.tistory.com/203
- https://aws.amazon.com/blogs/database/archive-and-purge-data-for-amazon-rds-for-postgresql-and-amazon-aurora-with-postgresql-compatibility-using-pg_partman-and-amazon-s3/
- https://dev.mysql.com/doc/refman/8.0/en/partitioning-selection.html
- https://dba.stackexchange.com/questions/23138/unable-to-select-the-records-from-specific-partition-in-mysql
- https://stackoverflow.com/questions/42438157/when-creating-partition-it-shows-error
댓글남기기