


스탠포드 STORM 프레임워크의 RAG 확장하기
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
예전에 스탠포드 STORM(Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking)을 사용해 논문을 작성하고 싶다는 요구사항이 있었다. 기존에 보유하고 있는 논문 데이터들을 활용하고 싶다는 내용이었다. 이번 글에선 벡터 데이터베이스를 구성하고 STORM에서 제공하는 RAG(Retrieval-Augmented Generation) API를 확장해서 데이터 조회 후 논문을 작성할 때 활용하는 내용에 대해 정리했다.
1. What is Stanford STORM and Co-STORM?
스탠포드 STORM은 인터넷 검색을 기반으로 위키피디아 같은 문서를 처음부터 작성해주는 LLM(대규모 언어 모델) 시스템이다. Co-STORM은 사용자가 LLM 시스템과 협업할 수 있는 기능을 추가하여, 사용자의 의도에 더 부합하고 선호하는 정보를 탐색하며 지식을 큐레이션할 수 있도록 발전된 기능을 제공한다. 이 시스템은 발행 가능한 수준의 완성된 문서를 바로 만들어내지는 못한다.
아래 설명은 STORM 깃허브에 적힌 내용을 번역한 것이다. LLM에게 직접 프롬프트를 전달하는 것만으로는 잘 동작하지 않는다. 깊이와 넓이가 있는 질문을 만들기 위해 STORM은 다음과 같은 전략을 취한다.
- 관점 가이드 질문 제기(Perspective-Guided Question Asking): STORM은 입력된 주제에 대해 유사한 주제의 기존 문서들을 조사하여 다양한 관점을 발견하고, 이를 활용해 질문 제기 과정을 제어한다.
- 시뮬레이션 대화(Simulated Conversation): STORM은 인터넷 소스에 근거하여 위키피디아 작성자와 주제 전문가 사이의 대화를 시뮬레이션한다. 이를 통해 언어 모델이 주제에 대한 이해를 업데이트하고 후속 질문을 던질 수 있도록 한다.
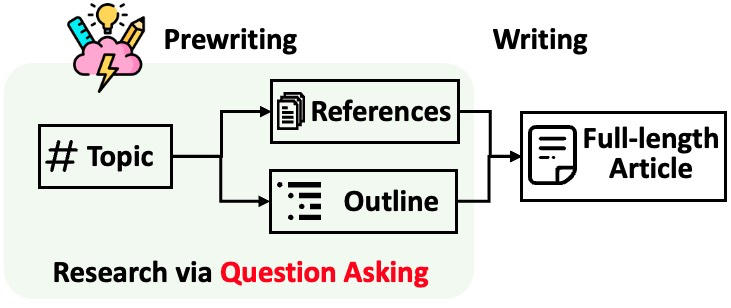
STORM은 글을 쓰기 전에 철저한 사전 조사를 수행하도록 설계되어 있다. 다음과 같은 과정을 따라 동작한다.
- 사전 작성 단계: 레퍼런스를 수집하기 위한 인터넷 기반 리서치를 수행하고 개요(outline)를 생성한다. 멀티턴 검색(multi-turn retrieval)을 통해 정보를 수집하고, 출처를 확보한다.
- 작성 단계: 시스템은 개요와 레퍼런스를 사용해 인용과 함께 논문을 작성한다.
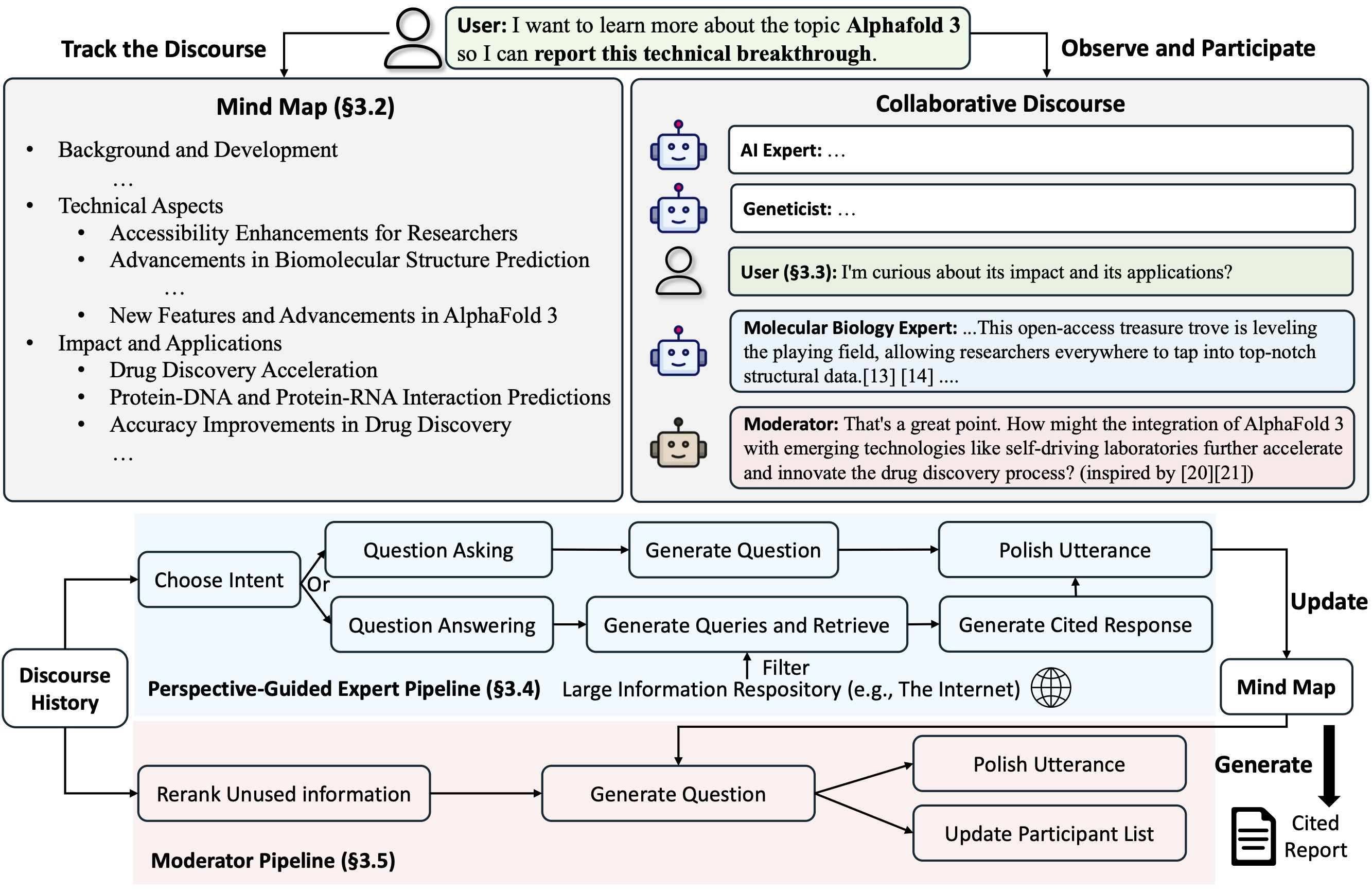
STORM은 아티클 작성을 AI가 혼자 다 수행하지만, Co-STORM은 인간이 글을 쓸 때 AI가 실시간으로 개입하여 도와주는 것이다. 인간이 지식의 구조를 잡는 것을 AI가 돕는 협업(collaboration)에 초점을 맞춘다. 인간 주도(HITL, Human in the Loop) 방식으로 사용자가 먼저 주제를 제시하거나 글을 쓰기 시작한다.
사용자가 작성하는 내용을 바탕으로 AI는 백그라운드에서 검색을 수행한다. 수집한 정보를 기반으로 AI는 능동적으로 개입한다. 계층적인 개념 구조로 조직화되고, 동적으로 업데이트되는 마인드맵을 유지하며, 이를 통해 인간 사용자와 시스템 사이에 공유된 개념 공간을 구축하는 것을 목표로 한다. Co-STORM은 다음과 같은 주체들 간의 원활한 협업을 지원하기 위해 턴 관리 정책(turn management policy)을 구현한 협업 담화 프로토콜을 제안하고 있다.
- Co-STORM LLM 전문가(Co-STORM LLM experts): 외부 지식 소스에 근거하여 답변을 생성하거나, 이전 담화 기록을 바탕으로 후속 질문을 제기하는 에이전트다.
- 중재자(Moderator): 검색기(Retriever)에 의해 발견되었으나 이전 턴에서 직접 사용되지 않은 정보에서 영감을 얻어, 사고를 자극하는 질문을 생성하는 에이전트다. 질문 생성 과정 또한 근거(gounded)를 바탕으로 이루어질 수 있다.
- 인간 사용자(Human user): 사용자는 주도권을 가지고 담화를 관찰하며 주제에 대한 더 깊은 이해를 얻거나, 대화에 직접 참여하여 발화를 입력함으로써 토론의 초점을 유도할 수 있다.
2. STORM APIs
STORM에서 제공하는 API는 다음과 같다.
- 언어 모델 컴포넌트
- 임베딩 모델 컴포넌트
- 검색 모듈 컴포넌트
- YouRM, BingSearch, VectorRM, SerperRM, BraveRM, SearXNG, DuckDuckGoSearchRM, TavilySearchRM, GoogleSearch, and AzureAISearch as
STORM, Co-STORM 모두 정보 큐레이션(curation) 계층에서 동작한다. 각각의 Runner 클래스를 생성하기 위해서는 정보 검색 모듈과 언어 모델 모듈을 설정해야 한다.
3. Setup project
STORM은 파이썬 3.14 버전을 지원하지 않는다. 이번 글에선 파이썬 3.13 버전을 사용한다. 다음과 같이 가상 환경을 구축한다.
$ python3.13 -m venv .venv
$ source .venv/bin/activate
(.venv) $
STORM을 라이브러리 용도로 사용하고 싶기 때문에 패키지로 설치한다.
$ pip install knowledge-storm
3. Indexing for vector database
간단하게 커스텀 검색 모듈을 위한 벡터 데이터 임베딩을 만들어보자. 벡터 데이터베이스는 FAISS(Facebook AI Similarity Search)를 사용한다. 이번 글에선 CPU를 사용하기 때문에 faiss-cpu 패키지를 설치한다.
$ pip install faiss-cpu
의미론적(semantic)으로 유사한 데이터를 찾을 때는 벡터 데이터베이스를 사용하지만, 이에 연관된 실제 논문 제목, 내용, DOI 등을 찾기 위해 보조로 SQLite 데이터베이스를 사용한다.
이번 글에선 실제 데이터를 사용하지 않고 페이크 데이터 1000건 정도를 사용한다. 실제로는 정제된 논문 데이터를 MySQL에서 불러오도록 구현하였지만, 이 글에선 faker 라이브러리를 사용한다.
$ pip install faker
다음과 같은 로직을 통해 페이크 논문을 생성한다.
import random
from typing import List
from faker import Faker
fake = Faker('en_US')
class Article:
def __init__(self, id: int, title: str, content: str, url: str):
self.id = id
self.title = title
self.content = content
self.url = url
def fake_articles(num_records=1000) -> List[Article]:
data: List[Article] = []
for i in range(1, num_records + 1):
doc_id = i
title = fake.sentence(nb_words=random.randint(5, 12)).replace('.', '')
content = ""
while len(content) < 1000:
paragraphs = fake.paragraphs(nb=random.randint(5, 10))
new_text = "\n\n".join(paragraphs)
content += new_text + "\n\n"
doi_prefix = "10." + str(random.randint(1000, 9999))
doi_suffix = fake.uuid4().split('-')[0]
url = f"https://doi.org/{doi_prefix}/{doi_suffix}"
data.append(Article(doc_id, title.title(), content.strip(), url))
return data
다음 페이크 데이터를 기반으로 FAISS에 인덱싱 작업을 수행한다. 인덱싱 작업을 수행할 때 원본 데이터를 찾기 위한 피클(pickle)과 SQLite 데이터베이스를 함께 만든다. 임베딩 모델은 오픈 소스인 sentence-transformers를 사용한다.
- create_faiss_index 함수
- FAISS 벡터 데이터베이스에 논문 내용들을 임베딩한 후 인덱싱한다.
- create_sqlite_database 함수
- 논문 데이터를 SQLite 데이터베이스 articles 테이블에 저장한다.
- create_pickle 함수
- FAISS 데이터베이스로부터 검색한 벡터의 원본을 찾기 위해 논문 아이디를 함께 저장한다.
import os
import pickle
import sqlite3
from typing import List
import faiss
from sentence_transformers import SentenceTransformer
from faker_articles import fake_articles, Article
def indexing():
articles = fake_articles()
create_faiss_index(list([article.content for article in articles]))
create_pickle(list([article.id for article in articles]))
create_sqlite_database(articles)
def create_faiss_index(
texts: List[str],
model_name: str = "sentence-transformers/paraphrase-multilingual-mpnet-base-v2",
index_path: str = "db/faiss_index.bin",
):
os.makedirs(os.path.dirname("db/"), exist_ok=True)
model = SentenceTransformer(model_name)
embeddings = model.encode(texts, normalize_embeddings=True, show_progress_bar=True)
embeddings = embeddings.astype("float32")
dimension = embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(embeddings)
faiss.write_index(index, index_path)
def create_sqlite_database(
articles: List[Article], sqlite_path: str = "db/articles.db"
):
os.makedirs(os.path.dirname("db/"), exist_ok=True)
conn = sqlite3.connect(sqlite_path)
cursor = conn.cursor()
cursor.execute(
"create table if not exists articles (id integer primary key autoincrement, article_id integer, title TEXT, content TEXT, url TEXT)"
)
rows = []
for article in articles:
rows.append((article.id, article.title, article.content, article.url))
cursor.executemany(
"insert into articles (article_id, title, content, url) values (?, ?, ?, ?)", rows
)
conn.commit()
conn.close()
def create_pickle(
article_id_list: List[int], pickle_path: str = "db/article_id_list.pkl"
):
os.makedirs(os.path.dirname("db/"), exist_ok=True)
with open(pickle_path, "wb") as f:
pickle.dump(article_id_list, f)
if __name__ == "__main__":
indexing()
위 인덱싱 스크립트를 실행한다.
$ python indexing/main.py
Batches: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 32/32 [00:04<00:00, 6.62it/s]
인덱싱이 완료되면 db 경로에 SQLite 데이터베이스, FAISS 인덱싱, 논문 아이디 리스트 피클이 생성된다.
$ ls -al db/
total 9768
drwxr-xr-x@ 5 junhyunny staff 160 Dec 26 11:16 .
drwxr-xr-x 11 junhyunny staff 352 Dec 26 11:10 ..
-rw-r--r--@ 1 junhyunny staff 2761 Dec 26 11:16 article_id_list.pkl
-rw-r--r--@ 1 junhyunny staff 1921024 Dec 26 11:16 articles.db
-rw-r--r--@ 1 junhyunny staff 3072045 Dec 26 11:16 faiss_index.bin
3. Make custom retrieval module
회사에 누적된 데이터를 활용해 벡터 데이터베이스를 구축한 후 RAG 검색을 수행하고 싶은 것이기 때문에 커스텀 검색 모듈을 만들 필요가 있었다. 지금부터 프로젝트 내에서 활용하는 커스텀 검색 모듈을 만들어보자. 커스텀 모듈에서 사용할 벡터 데이터베이스 클래스를 정의한다. 인덱싱할 때와 동일한 임베딩 모델을 사용한다.
- _load_index 메서드
- 사전 인덱싱한 파일을 기반으로 인덱스 객체를 생성한다.
- _load_pickle 메서드
- 사전 인덱싱 작업에서 생성한 피클 파일을 로드한다.
- search 메서드
- 외부에서 전달받은 쿼리와 연관된 문장을 FAISS 인덱스 객체를 통해 조회한다.
- 인덱싱 시 사용했던 모델과 동일한 모델을 사용한다.
- 조회한 벡터의 식별자(indices)를 통해 해당 벡터가 원본의 어느 위치에 있었는지 확인할 수 있다. 이를 통해 원본 논문의 아이디를 획득하고 이를 반환한다.
import pickle
import faiss
from sentence_transformers import SentenceTransformer
class VectorStore:
def __init__(
self,
pickle_path: str = "db/article_id_list.pkl",
index_path: str = "db/faiss_index.bin",
model_name: str = "sentence-transformers/paraphrase-multilingual-mpnet-base-v2",
):
self.embedding_model = SentenceTransformer(model_name)
self._load_index(index_path)
self._load_pickle(pickle_path)
def _load_index(self, index_path: str):
try:
self.index = faiss.read_index(index_path)
except Exception as e:
raise Exception("Index not found. Please run indexing first.")
def _load_pickle(self, pickle_path: str):
try:
with open(pickle_path, "rb") as f:
self.article_id_list = pickle.load(f)
except Exception as e:
raise Exception("Pickle not found. Please run indexing first.")
def search(self, query: str, top_k: int = 10):
if self.index is None or self.article_id_list is None:
raise Exception("Index or pickle not loaded properly.")
query_embedding = self.embedding_model.encode([query], normalize_embeddings=True)
distances, indices = self.index.search(query_embedding, top_k)
results = []
for distance, id_index in zip(distances[0], indices[0]):
results.append((self.article_id_list[id_index], distance))
return results
이제 커스텀 조회 모듈을 만든다. dspy 패키지의 Retrieve 모듈을 상속받은 후 forward 함수를 재정의한다. STORM은 28개 정도의 검색 모듈을 제공한다.
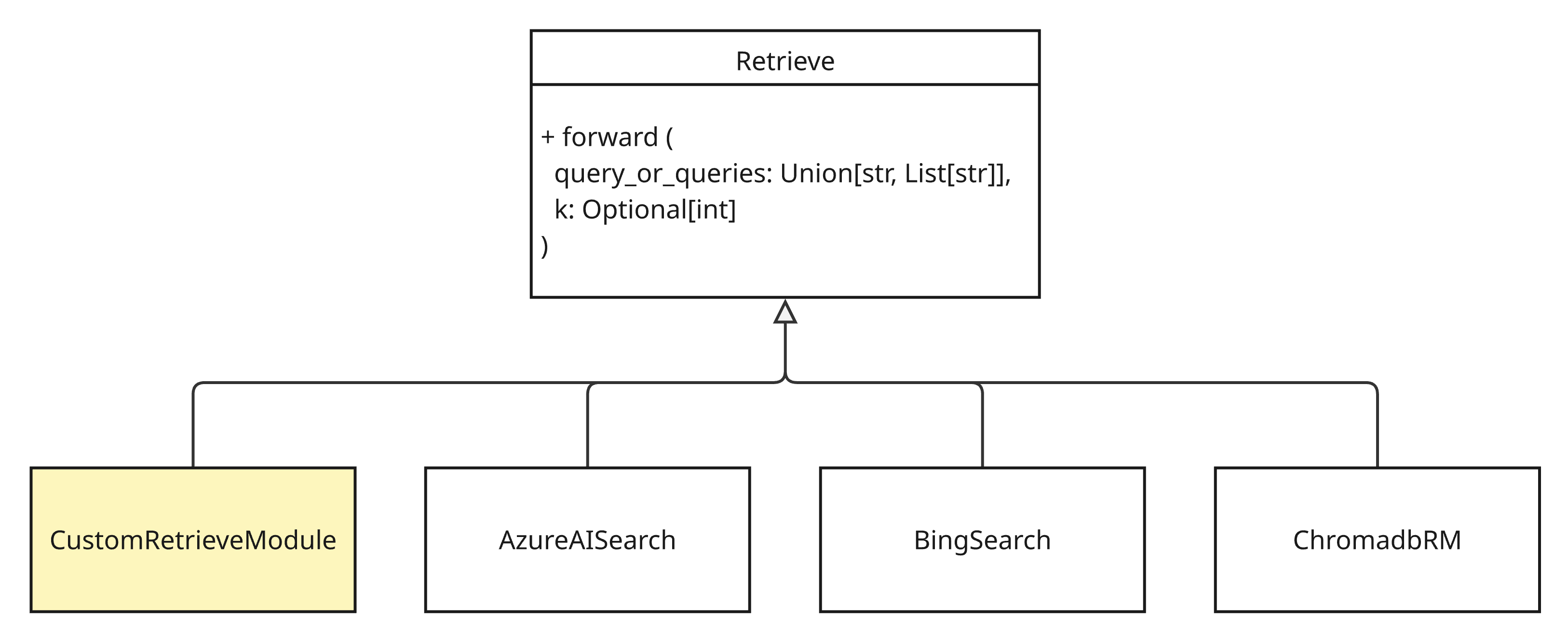
아래와 같은 커스텀 검색 모듈을 생성한다. 벡터 데이터베이스를 통해 논문 아이디 리스트를 획득한다. 획득한 논문 아이디는 SQLite 데이터베이스로부터 원본 논문 정보를 검색할 때 사용한다.
- forward 메서드
- STORM 프레임워크에서 AI가 필요한 정보를 검색할 때 해당 메서드가 호출된다. 멀티 스레드를 통해 비동기적으로 조회된다.
- fetch_articles_by_article_id 메서드
- 벡터 데이터베이스로부터 조회한 논문 아이디 리스트를 사용해 SQLite 데이터베이스로부터 논문 정보를 조회한다.
- to_result 함수
- 조회한 논문 정보를 AI가 사용할 수 있는 포맷의 데이터로 변경한다.
import sqlite3
from typing import Union, List, Optional
import dspy
from indexing.faker_articles import Article
from rag.vector_store import VectorStore
def to_result(articles: List[Article]):
result = []
for article in articles:
item = {
"title": article[0],
"description": article[1],
"snippets": [article[1]],
"url": article[2],
}
print(f"fetched article: {item}")
result.append(item)
return result
class CustomRetrieveModule(dspy.Retrieve):
def __init__(
self,
vector_store: VectorStore,
sqlite_article_db_path: str = "db/articles.db",
default_k: int = 5,
):
super().__init__()
self.vector_store = vector_store
self.sqlite_article_db_path = sqlite_article_db_path
self.k = default_k
def fetch_articles_by_article_id(self, article_id_list: List[int]):
conn = sqlite3.connect(self.sqlite_article_db_path)
cur = conn.cursor()
placeholders = ", ".join(["?"] * len(article_id_list))
query = f"SELECT title, content, url FROM articles WHERE id IN ({placeholders})"
cur.execute(query, article_id_list)
return cur.fetchall()
def forward(
self, query_or_queries: Union[str, List[str]], k: Optional[int] = None, **kwargs
):
try:
queries = (
query_or_queries if isinstance(query_or_queries, list) else [query_or_queries]
)
result = []
for query in queries:
print(f"retrieving query: {query}")
search_results = self.vector_store.search(query, top_k=k if k else self.k)
article_id_list, distance = zip(*search_results)
articles = self.fetch_articles_by_article_id(article_id_list)
result = to_result(articles)
return result
except Exception as e:
raise e
4. Write an article
커스텀 모듈까지 생성하였으면 이를 STORM의 논문 생성 프로세스에서 사용해보자. STORM 프레임워크를 실행하는 예제 코드는 공식 사이트를 참조했다. 공식 예제는 OpenAI의 chat-gpt 모델을 사용했지만, 여기선 AWS 베드록(bedrock)을 사용했다. boto3 패키지 설치가 필요하다.
$ pip install boto3
STORM을 실행하는 코드는 다음과 같다.
- create_retriever 함수
- 커스텀 검색 모듈을 생성 후 반환한다.
- create_llm 함수
- 사용할 LLM 객체를 생성 후 반환한다.
- create_runner 함수
- STORM runner 객체를 생성 후 반환한다.
- main 함수
- STORM runner 객체를 통해 “artificial intelligence” 이라는 토픽으로 글을 작성한다.
from dsp import LM, AWSAnthropic, Bedrock
from knowledge_storm import (
STORMWikiRunnerArguments,
STORMWikiRunner,
STORMWikiLMConfigs,
)
from rag.custom_rm import CustomRetrieveModule
from rag.vector_store import VectorStore
def create_retriever():
return CustomRetrieveModule(vector_store=VectorStore())
def create_llm() -> LM:
provider = Bedrock(region_name="ap-northeast-1")
return AWSAnthropic(provider, "apac.anthropic.claude-sonnet-4-20250514-v1:0")
def create_runner():
lm_configs = STORMWikiLMConfigs()
asker_model = create_llm()
lm_configs.set_conv_simulator_lm(asker_model)
lm_configs.set_question_asker_lm(asker_model)
generator_model = create_llm()
lm_configs.set_outline_gen_lm(generator_model)
lm_configs.set_article_gen_lm(generator_model)
lm_configs.set_article_polish_lm(generator_model)
retriever = create_retriever()
return STORMWikiRunner(
args=STORMWikiRunnerArguments(output_dir="output"),
lm_configs=lm_configs,
rm=retriever,
)
def main():
runner = create_runner()
runner.run(topic="artificial intelligence")
if __name__ == "__main__":
main()
위 메서드를 실행하면 “output/artificial_intelligence” 경로에 LLM 대화 로그, LLM 호출 히스토리, 아티클 개요, 아티클, 출처 URL 정보 등에 대한 결과가 생성된다.
$ ls -al output/artificial_intelligence
total 1376
drwxr-xr-x@ 9 junhyunny staff 288 Dec 27 21:39 .
drwxr-xr-x@ 3 junhyunny staff 96 Dec 27 09:20 ..
-rw-r--r--@ 1 junhyunny staff 430038 Dec 27 21:38 conversation_log.json
-rw-r--r--@ 1 junhyunny staff 661 Dec 27 21:38 direct_gen_outline.txt
-rw-r--r--@ 1 junhyunny staff 213654 Dec 27 21:38 raw_search_results.json
-rw-r--r--@ 1 junhyunny staff 2907 Dec 27 21:39 storm_gen_article.txt
-rw-r--r--@ 1 junhyunny staff 3758 Dec 27 21:39 storm_gen_article_polished.txt
-rw-r--r--@ 1 junhyunny staff 661 Dec 27 21:38 storm_gen_outline.txt
-rw-r--r--@ 1 junhyunny staff 40429 Dec 27 21:39 url_to_info.json
댓글남기기