


스프링 MVC Quartz 클러스터링(Clustering)
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
쿼츠(Quartz) 스케줄러를 처음 접했을 때 '동일한 소스 코드를 다중 서버 환경으로 배포한다면 같은 시간에 같은 기능이 여러 곳에서 실행되니 위험하고 불합리하지 않은가?'라는 의문이 있었다.
처음에는 스케줄러 애플리케이션을 별도로 구현해야 한다고 생각했는데, 정답이 아니었다. 스프링 MVC Quartz 사용하기 글에서 쿼츠 스케줄러의 장점 중 하나로 클러스터링(clustering)을 언급했었다. 쿼츠 클러스터링(Quartz Clustering)을 이용하면 고민했던 문제를 해결할 수 있다. 이번 글에서는 클러스터링 사용 시 얻는 이점을 정리하고, 간단한 구현 예제를 소개하겠다.
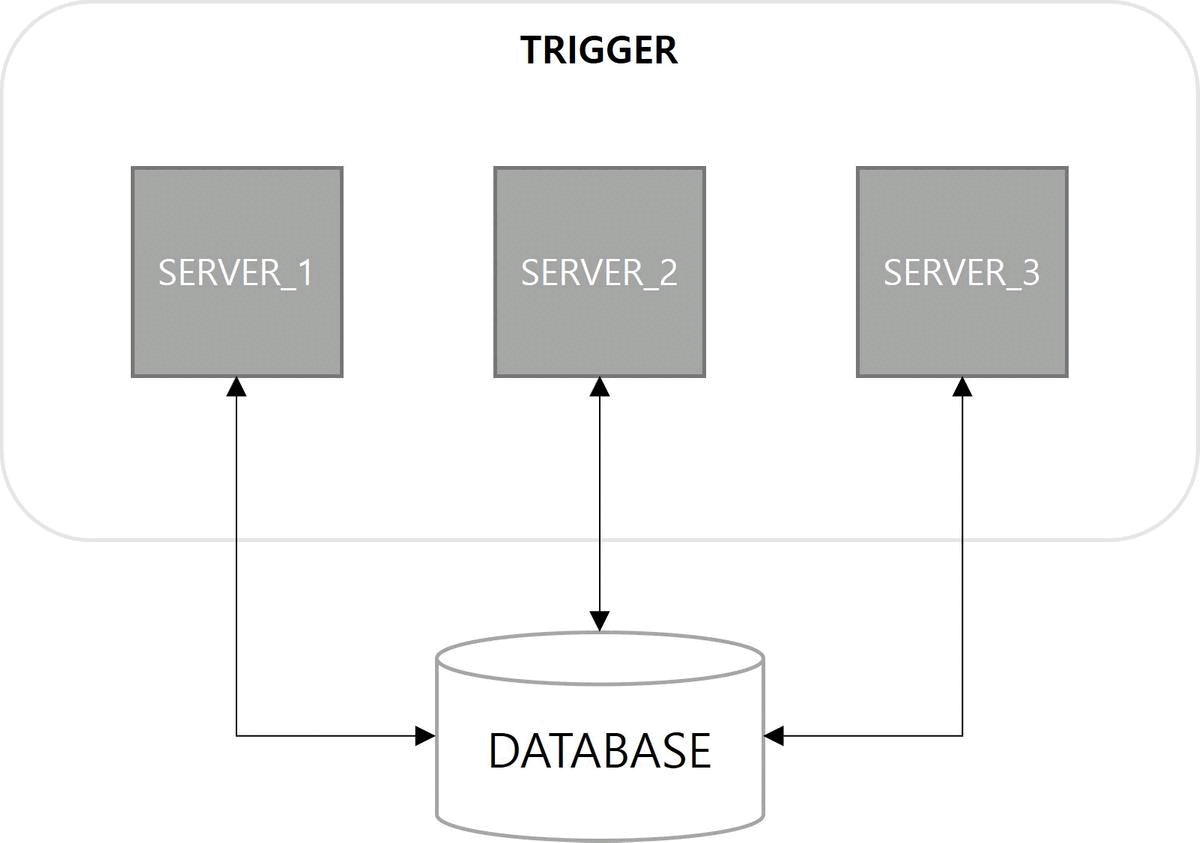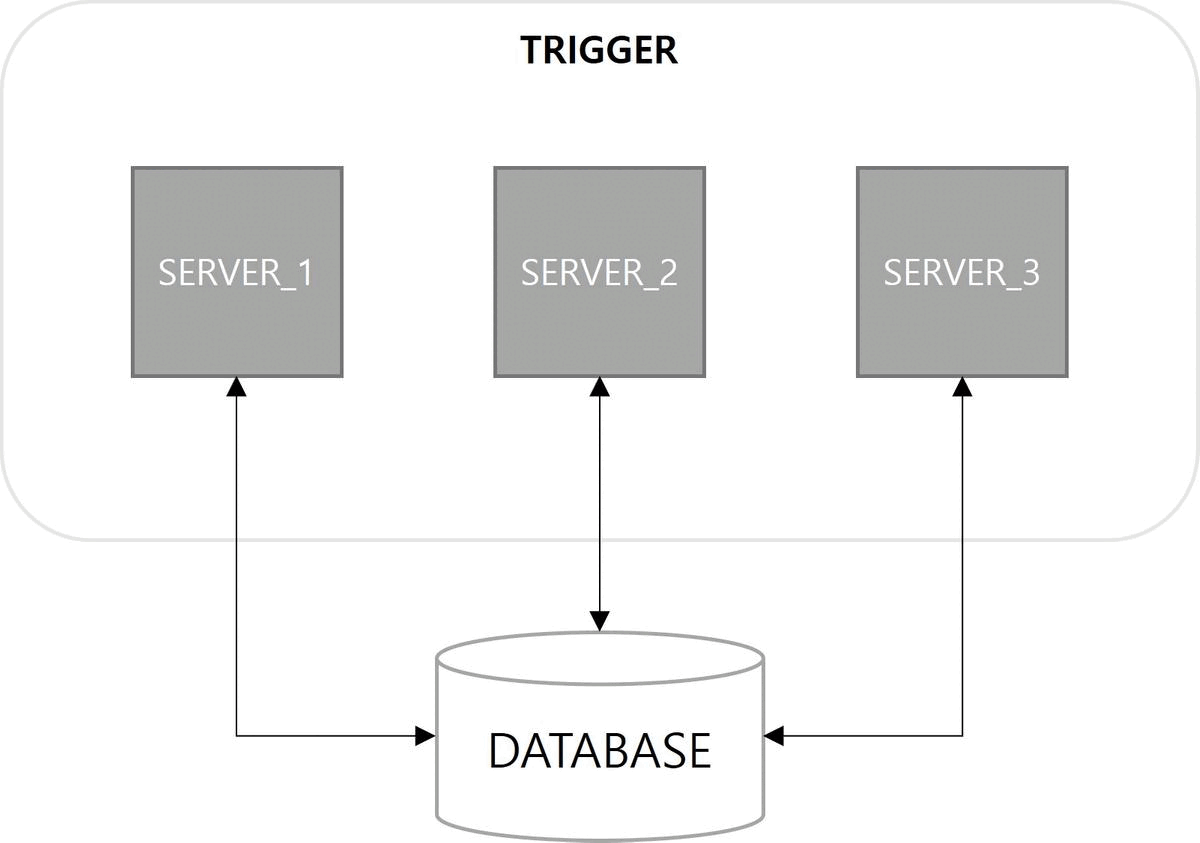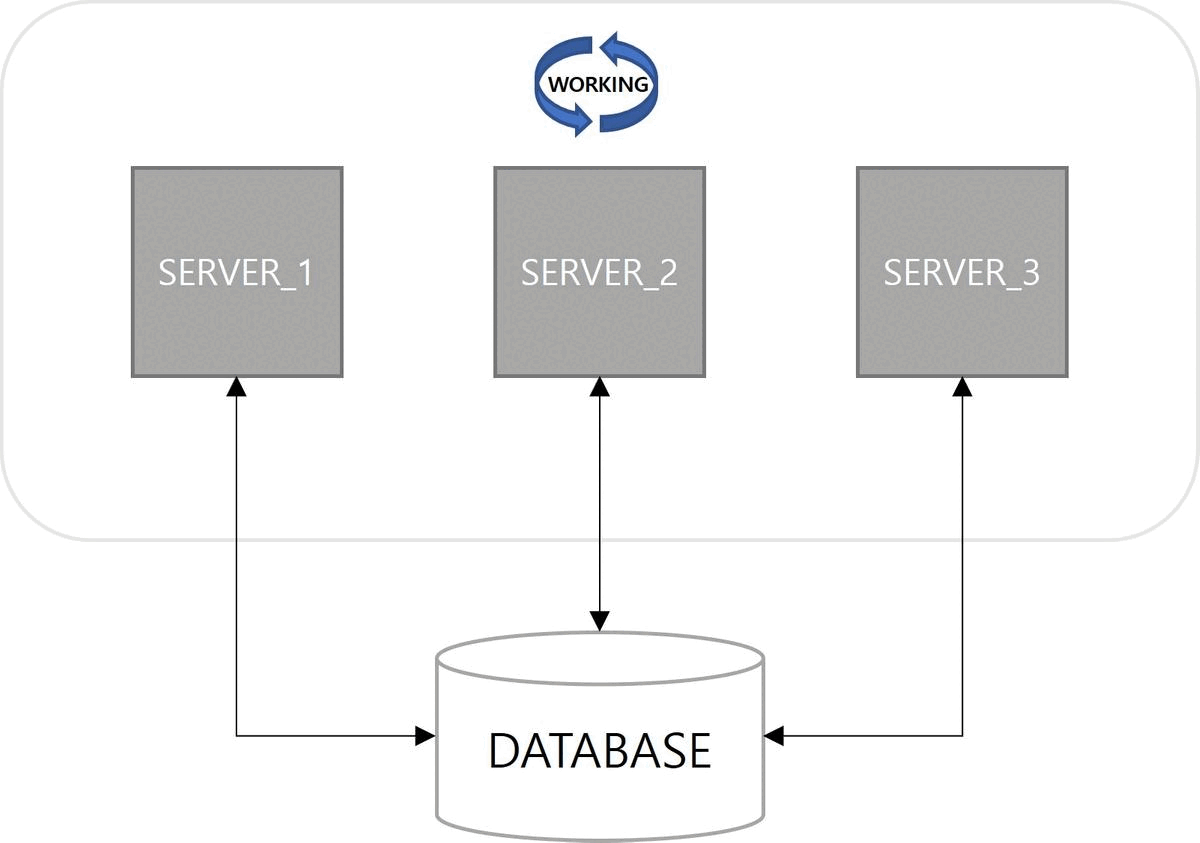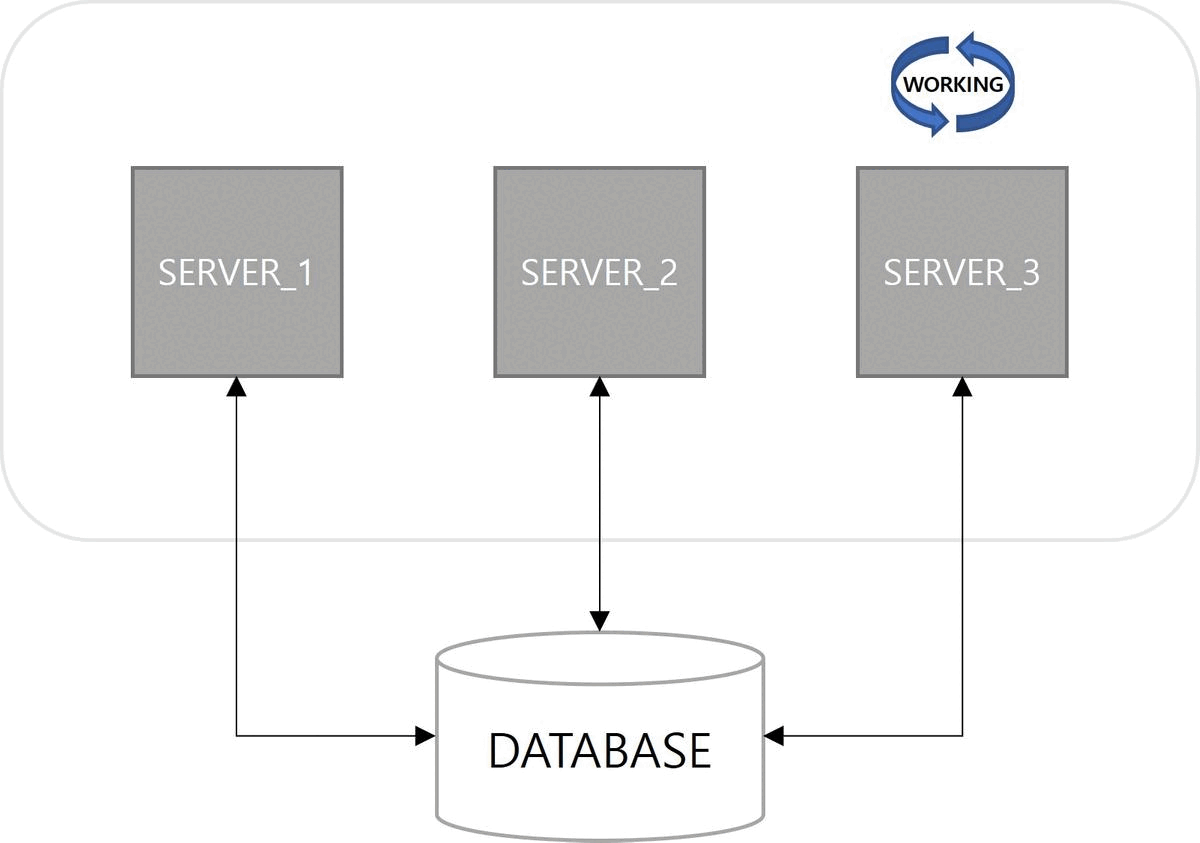
1. Spring Quartz Clustering
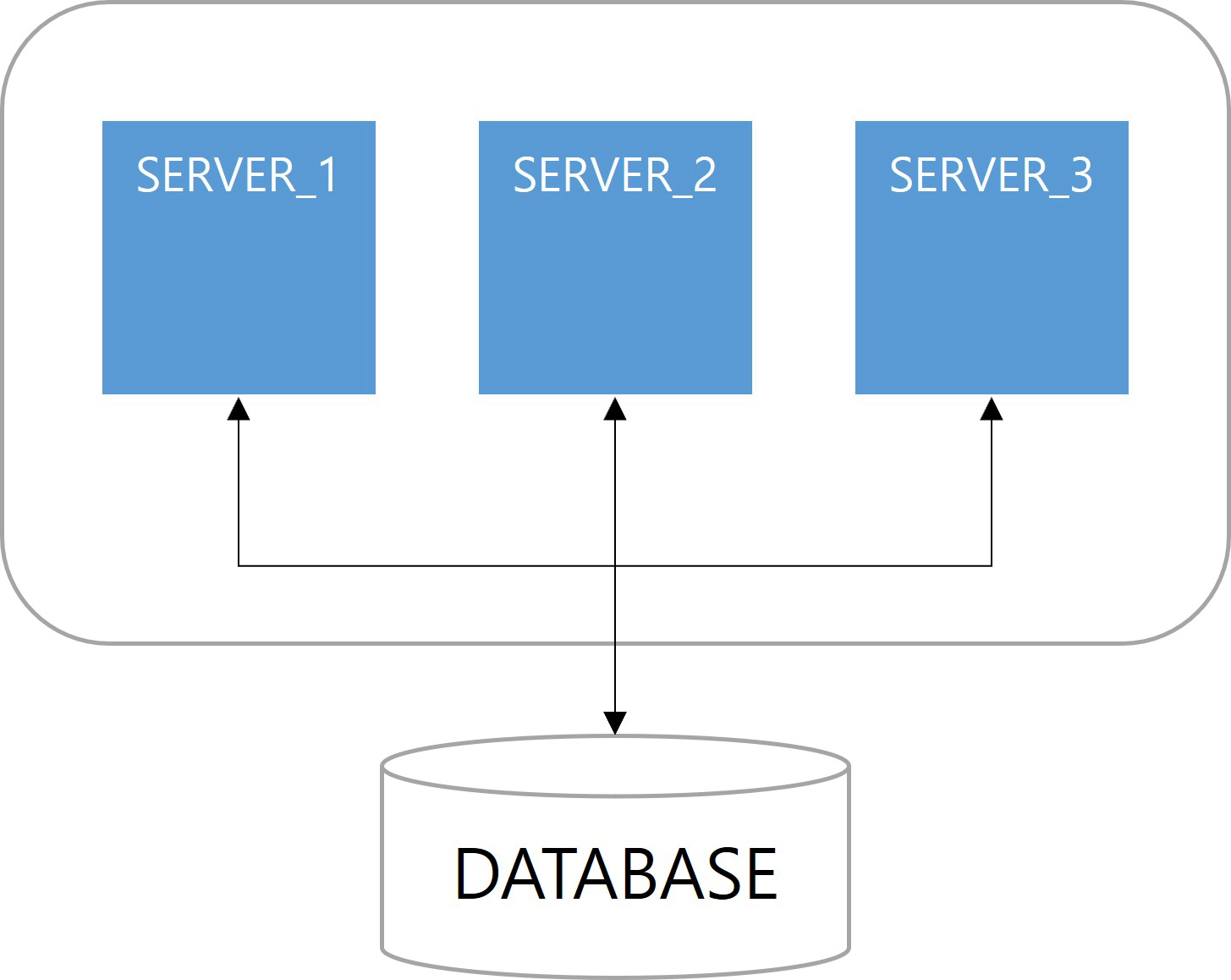
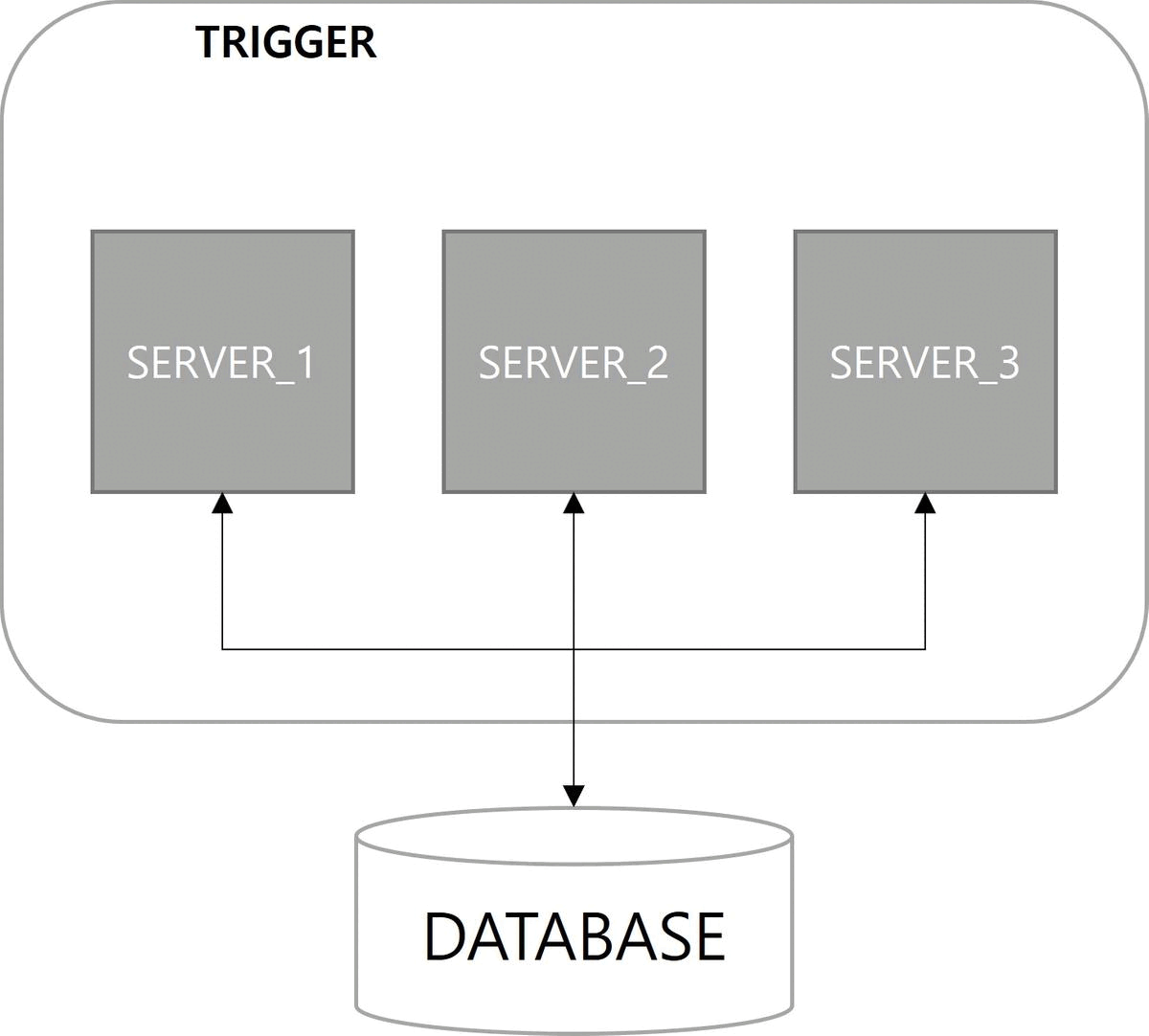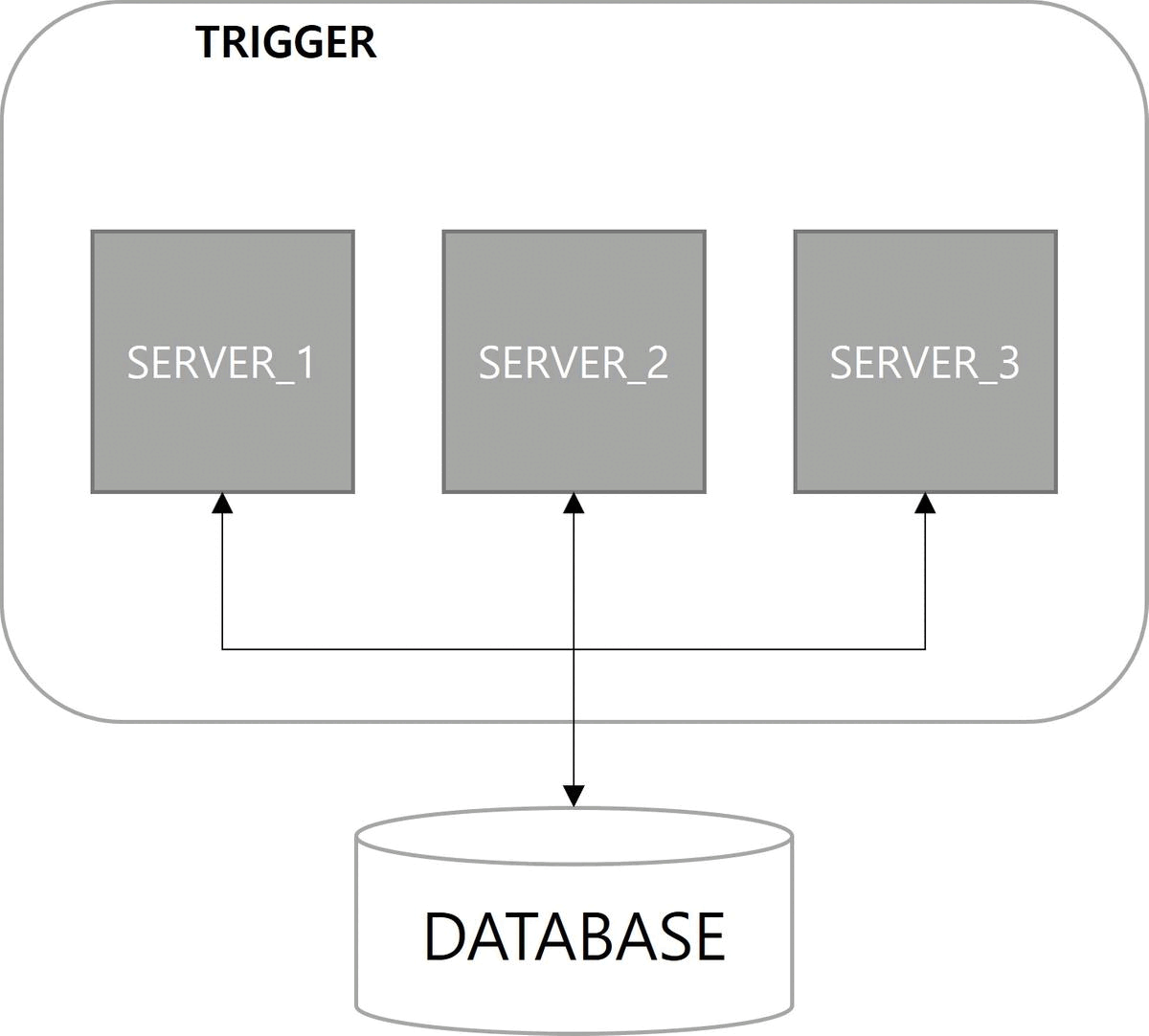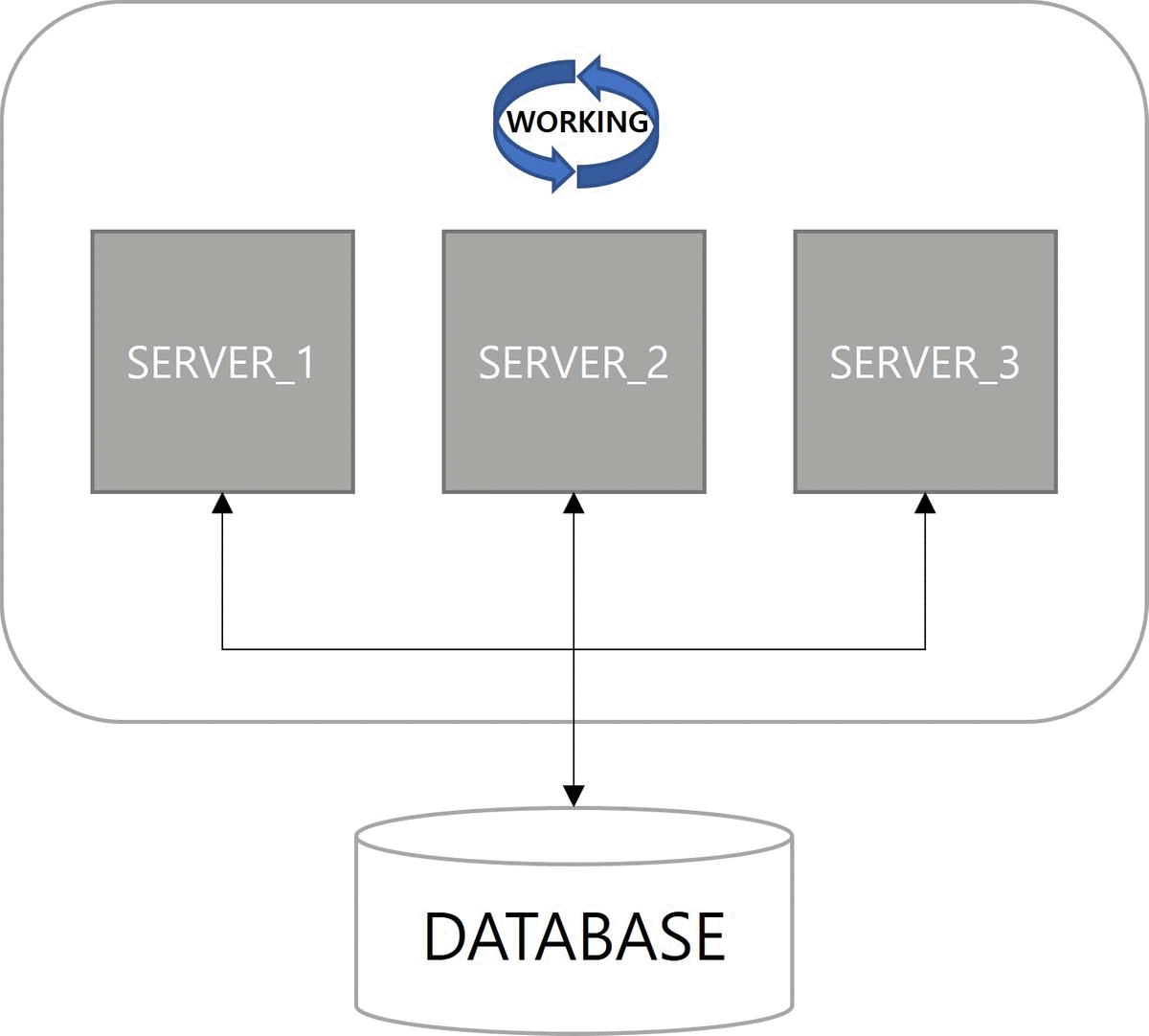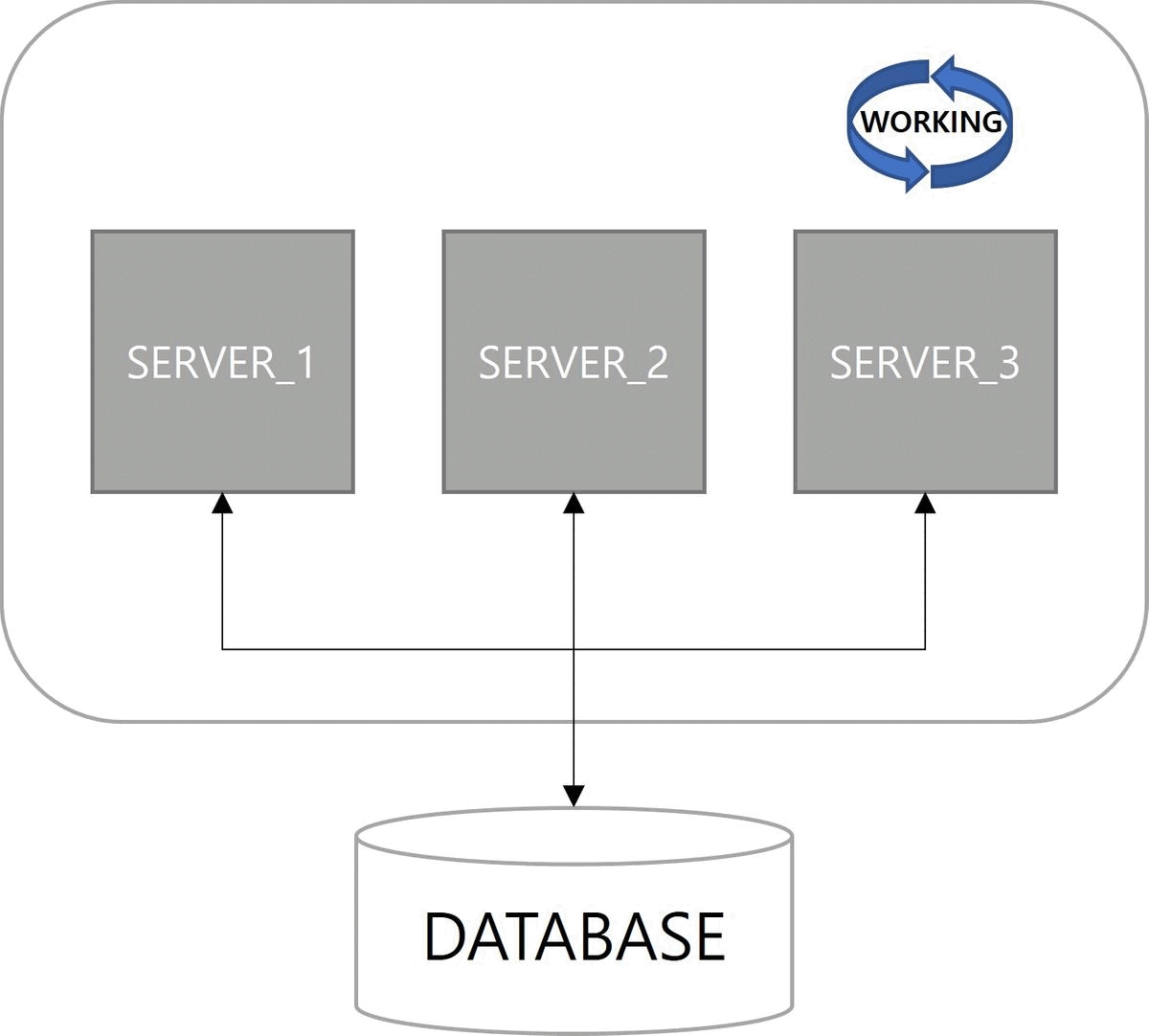
쿼츠 구조를 살펴보면 JobStore 기능이 존재한다. 해야 할 일인 Job과 이를 실행할 조건인 Trigger에 대한 정보를 어떤 방식으로 저장할지 정의한 기능이다. 정보를 저장하는 방법으로 메모리 방식과 데이터베이스 방식이 사용된다. 다중 서버 환경에서 데이터베이스 방식을 사용하면 서버 간에 Job, Trigger 정보를 공유할 수 있으므로 클러스터링이 가능하다.
2. Benefits of Spring Quartz Clustering
첫 번째 이점은 고가용성(High Availability)이다. 서버 중 하나가 다운(down)되더라도 다른 서버에 의해 Job이 실행된다. 쿼츠 Job 실행에 대한 다운타임(downtime)이 없다.
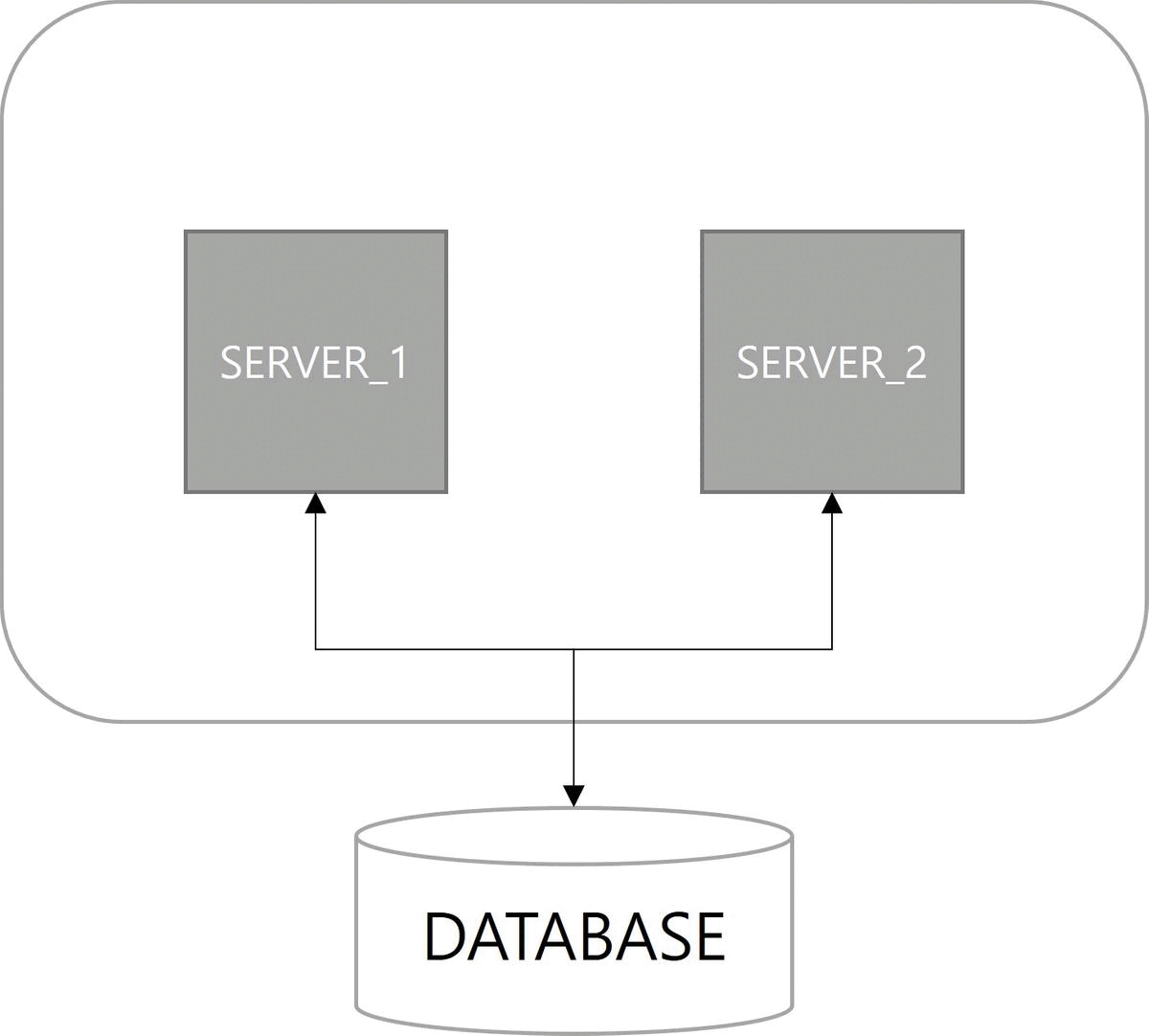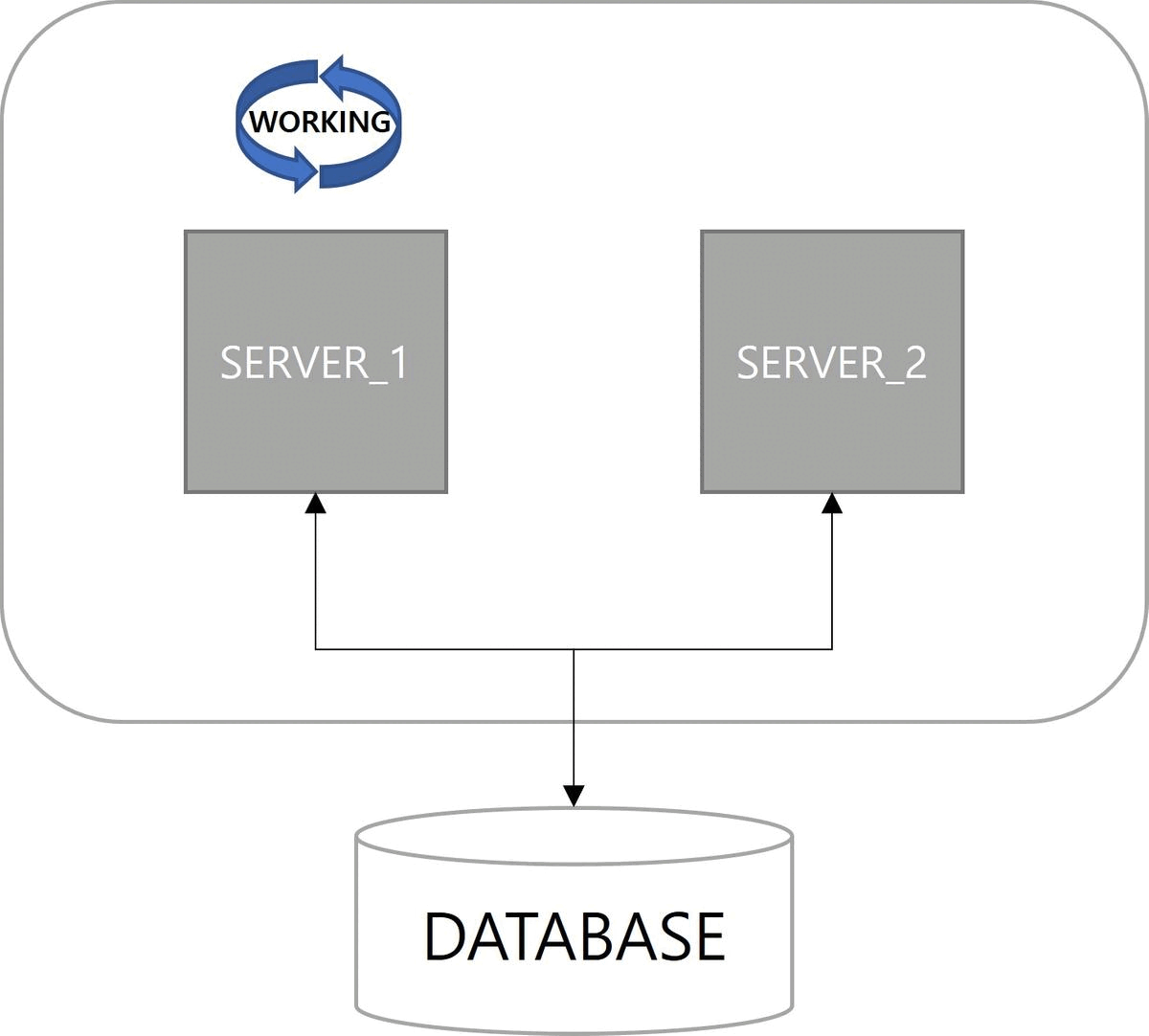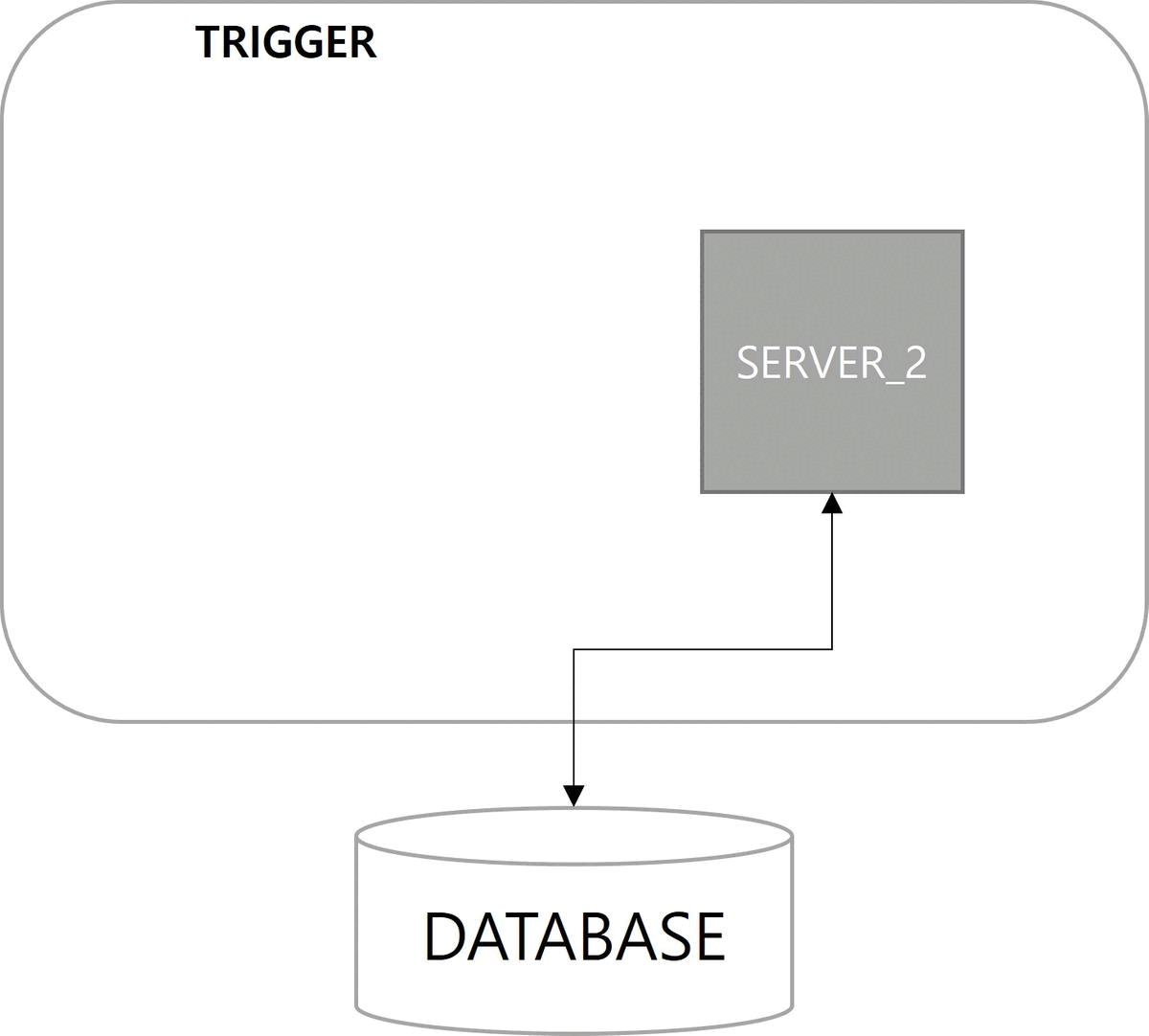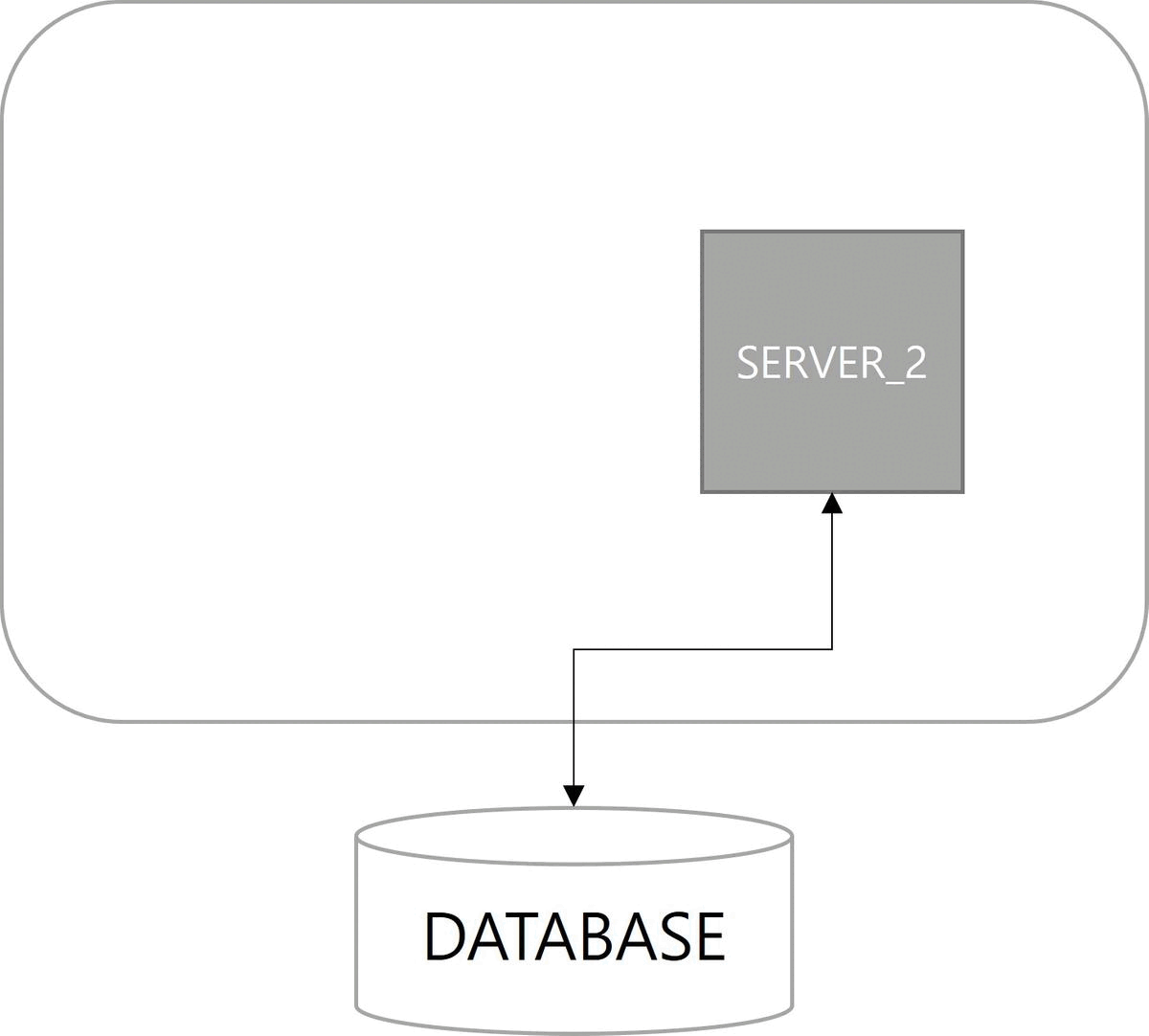
다음은 확장성(Scalability)이다. 쿼츠 설정이 적용된 서버를 구동하면 자동으로 데이터베이스에 스케줄 서버로 등록된다. 스케일아웃(scale-out)으로 서버가 늘어나더라도 함께 클러스터로 관리된다.
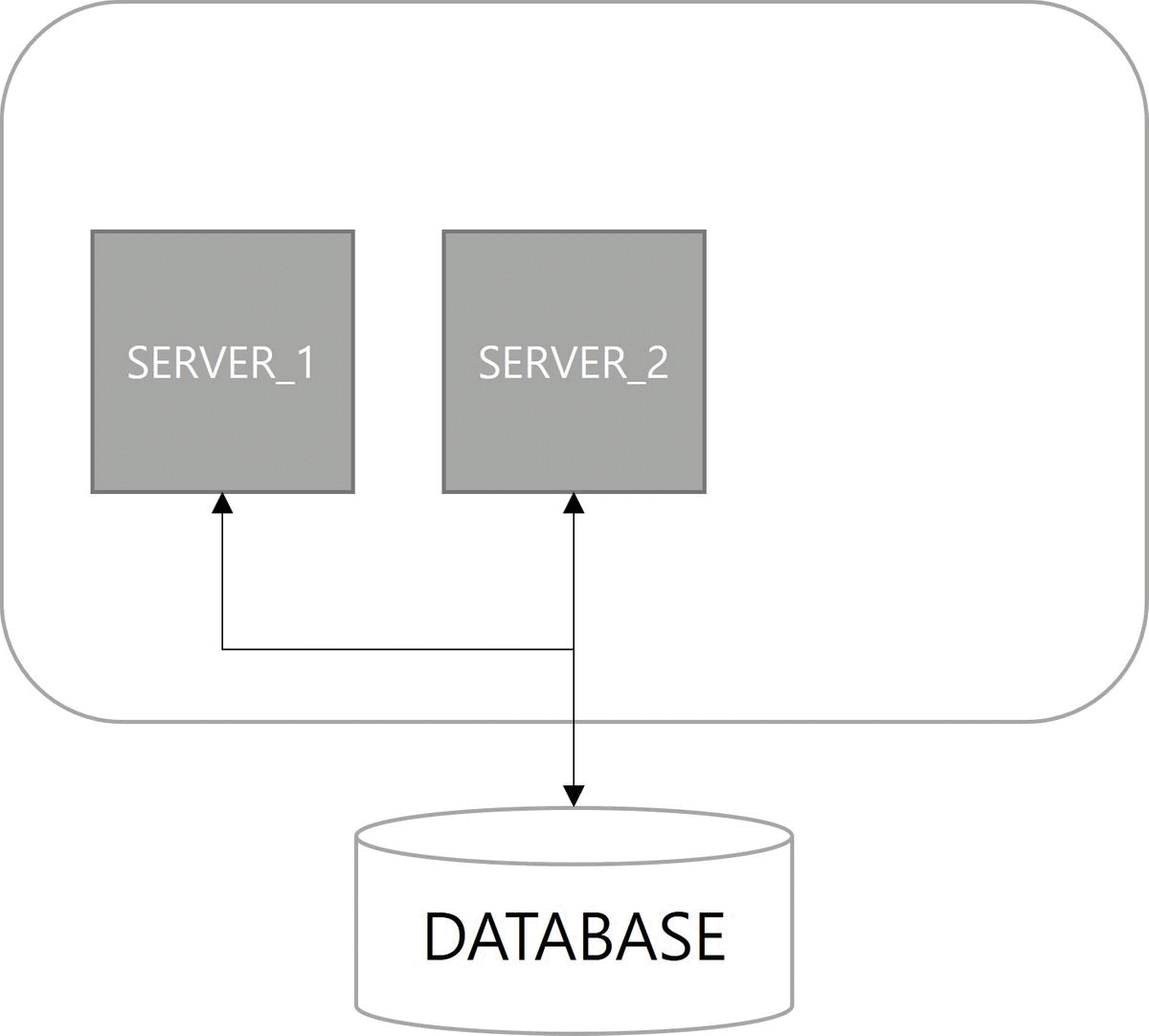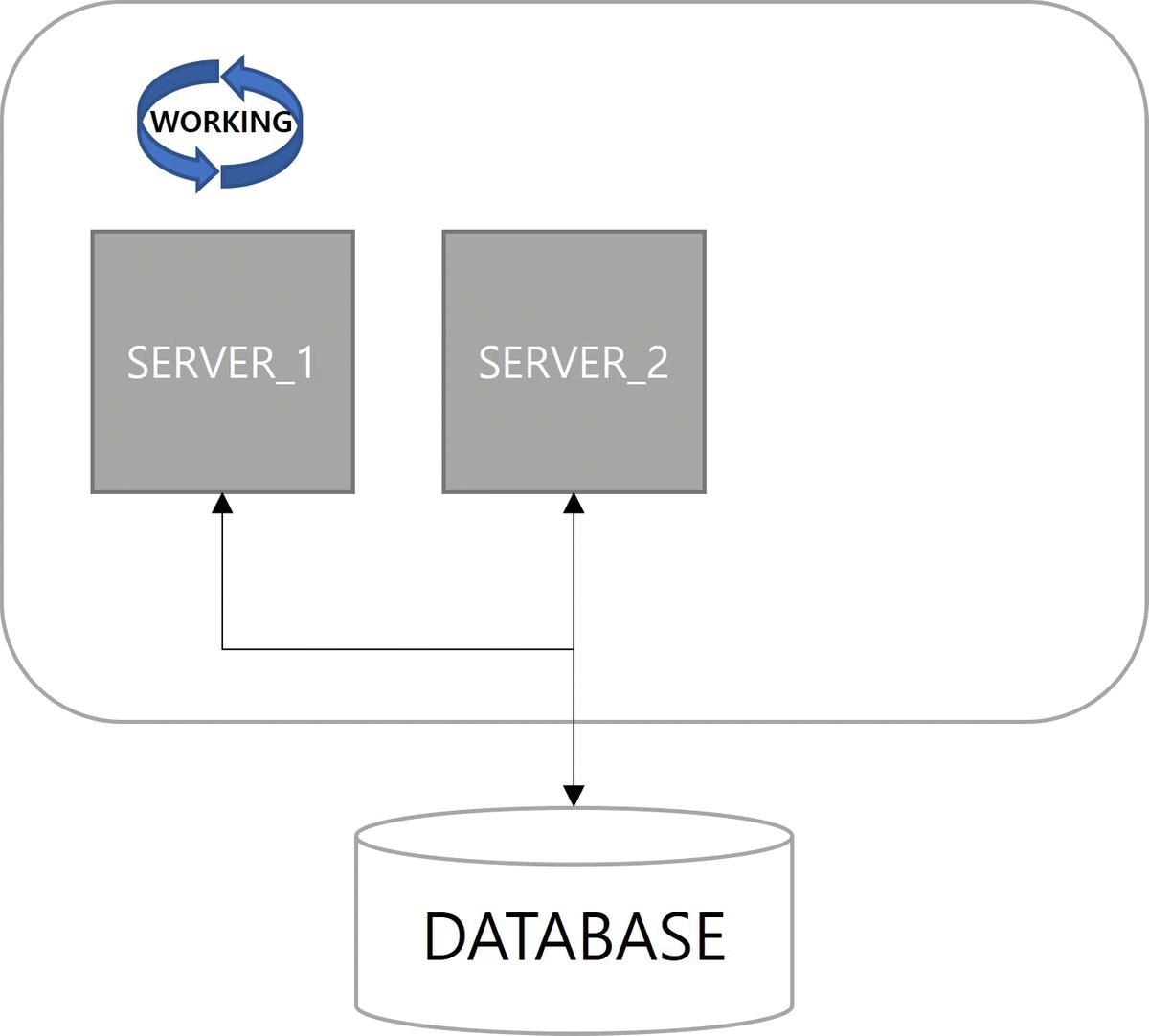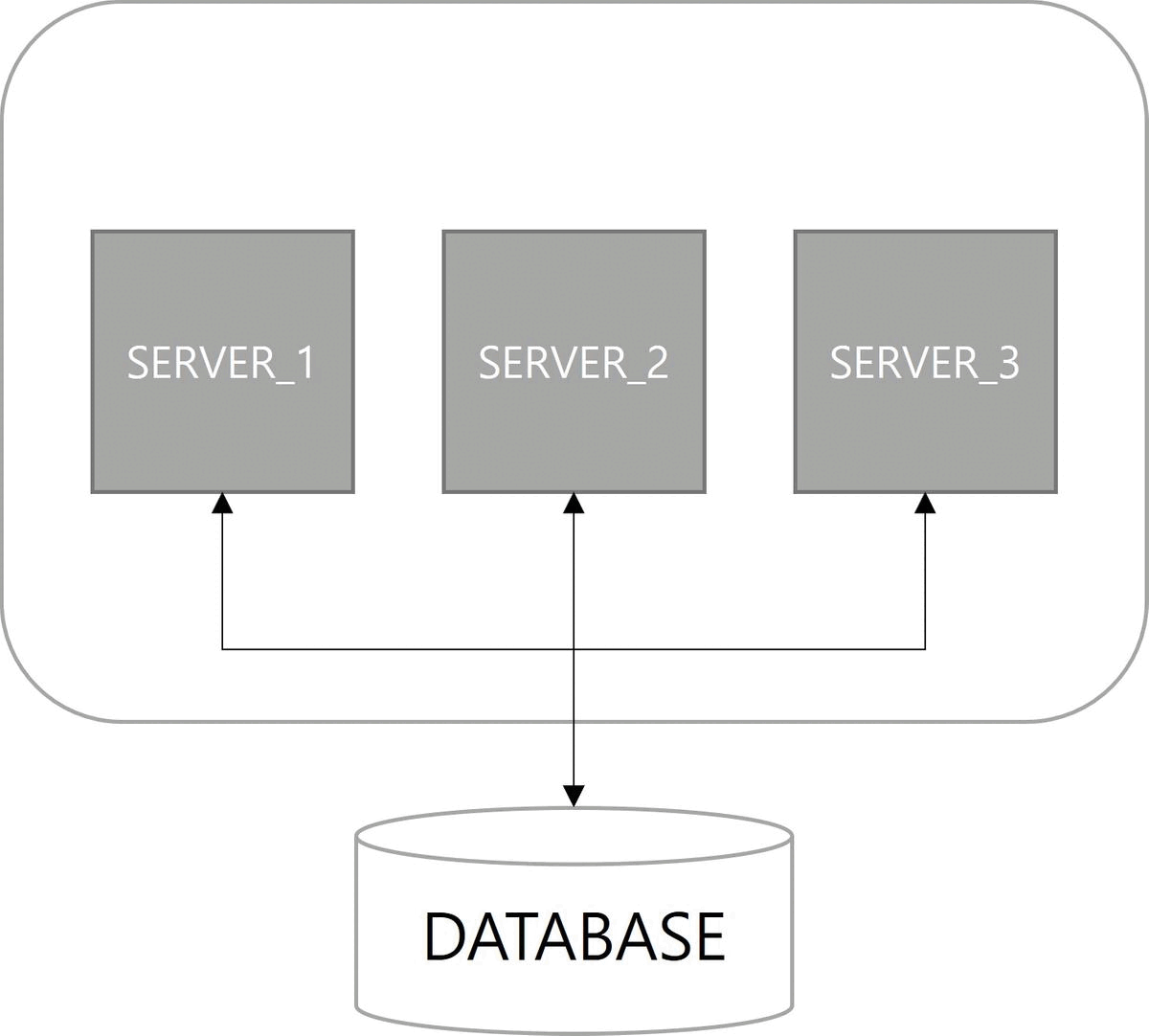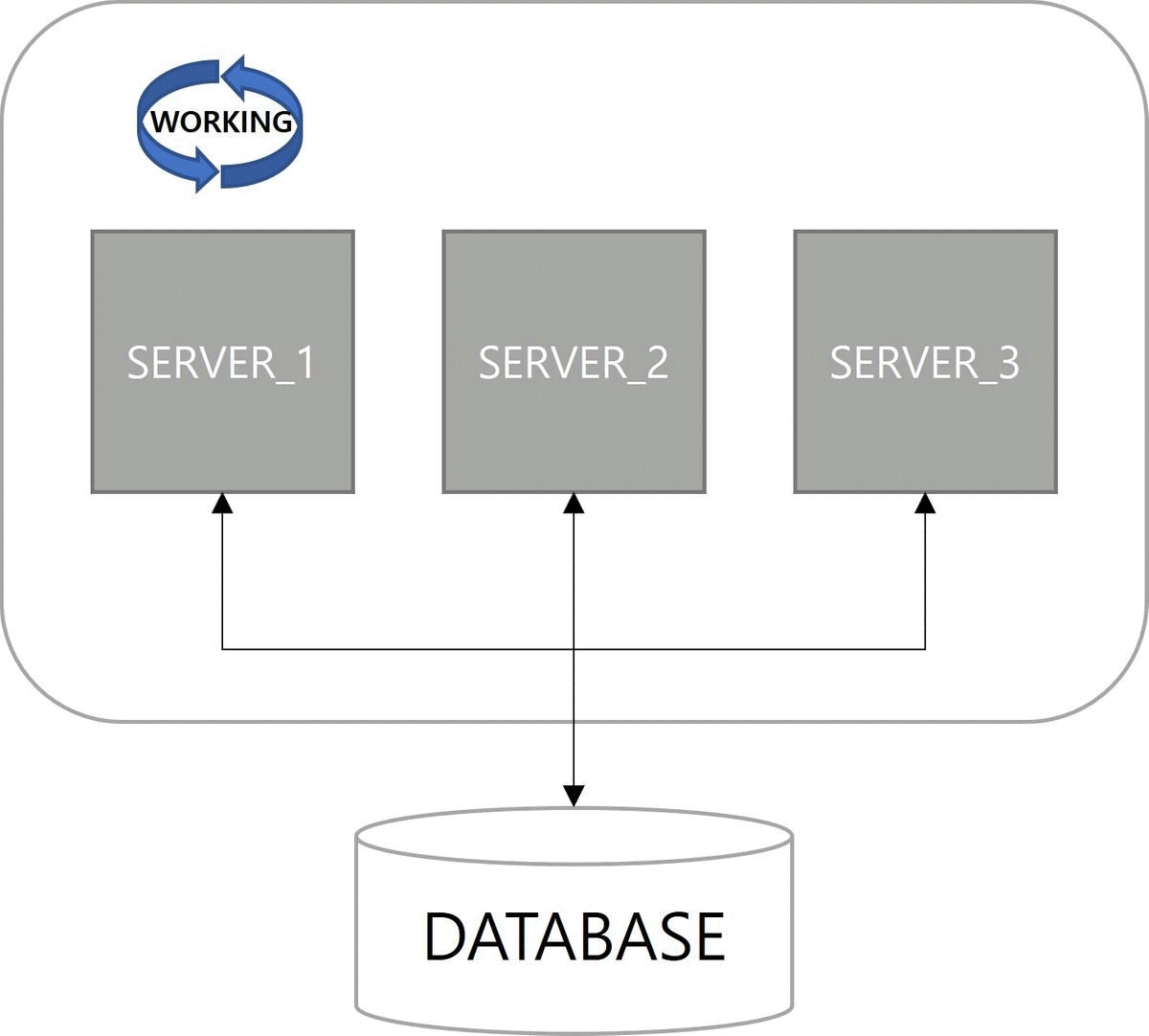
마지막으로 부하 분산(Load Balancing)이 장점이다. 클러스터 구성으로 Job이 여러 서버에 분산되어 실행된다. 쿼츠에서는 랜덤 알고리즘(random algorithm)만 구현되어 있다.
3. How to implement Spring Quartz Clustering
지금부터 스프링 쿼츠 클러스터링을 구현하는 방법을 알아보자. pom.xml 파일에 쿼츠 관련 의존성을 추가한다.
...
<dependencies>
...
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${org.springframework-version}</version>
</dependency>
</dependencies>
클러스터링을 위해 데이터베이스에 테이블을 생성한다. 쿼츠 관련 의존성을 추가하면 tables_mysql_innodb.sql 파일이 검색된다. tables_mysql_innodb.sql 파일에 있는 쿼리를 수행한다. 데이터베이스에 맞춰 SQL을 조정한다.
CREATE TABLE QRTZ_JOB_DETAILS(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(190) NOT NULL,
JOB_GROUP VARCHAR(190) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP))
ENGINE=InnoDB;
...
CREATE TABLE QRTZ_CRON_TRIGGERS (
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(190) NOT NULL,
TRIGGER_GROUP VARCHAR(190) NOT NULL,
CRON_EXPRESSION VARCHAR(120) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP))
ENGINE=InnoDB;
...
다음과 같은 테이블들이 생성된다.
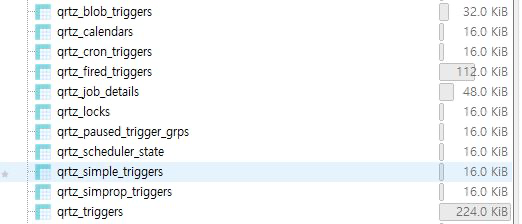
applicationContext.xml 파일에 클러스터링을 위한 스프링 빈(bean) 객체들을 정의한다.
JobDetailFactoryBean정의Job Class를 지정한다.BLOG_GROUP이름으로 그룹을 지정한다.
CronTriggerFactoryBean정의Job Detail은 위에서 생성한blogJob빈(bean)으로 지정한다.cronExpression을 지정한다. 1초 간격으로 지속적으로 실행한다.
SchedulerFactoryBean정의trigger는 위에서 생성한cronTrigger를 사용한다.dataSource는 위에서 생성한dataSource를 사용한다.applicationContextSchedulerContextKey를 스케줄러에서applicationContext를 꺼낼 수 있는 키로 지정한다.autoStartup설정은 스케줄러 초기화 후 자동 실행 여부를 지정한다.overwriteExistingJobs설정은 존재하는 Job 정의들을 덮어쓴다.waitForJobsToCompleteOnShutdown설정은 서버 셧다운(shutdown) 시 실행 중인 Job 종료를 기다릴지 여부를 결정한다.quartzProperties설정을 추가로 지정한다.
<bean name="blogJob" class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="blog.in.action.job.BlogJob"/>
<property name="durability" value="true"/>
<property name="group" value="BLOG_GROUP"/>
</bean>
<bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="blogJob"/>
<property name="cronExpression" value="0/1 * * * * ?"/>
</bean>
<bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger"/>
</list>
</property>
<property name="dataSource" ref="dataSource"/>
<property name="applicationContextSchedulerContextKey" value="applicationContext"/>
<property name="autoStartup" value="true"/>
<property name="overwriteExistingJobs" value="true"/>
<property name="waitForJobsToCompleteOnShutdown" value="true"/>
<property name="quartzProperties">
<props>
...
</props>
</property>
</bean>
SchedulerFactoryBean 객체를 정의할 때 quartzProperties 속성을 설정해야 한다. 다음과 같은 속성들이 필요하다.
org.quartz.jobStore.classJobStore클래스를 지정한다.
org.quartz.jobStore.driverDelegateClass- 데이터베이스별로 다른 SQL을 이해할 수 있는 클래스를 지정한다.
org.quartz.jobStore.dataSourceJobStore가 사용할 데이터소스를 지정한다.
org.quartz.jobStore.tablePrefix- 데이터베이스에 생성된 쿼츠 테이블에 주어진 접두사를 지정한다.
org.quartz.jobStore.isClustered- 클러스터링 기능을 사용하려면 true로 설정한다.
org.quartz.jobStore.clusterCheckinInterval- 클러스터의 다른 인스턴스에 체크인하는 빈도를 설정한다.
- 실패한 인스턴스를 감지하는 속도에 영향을 준다. (ms 단위)
org.quartz.jobStore.misfireThreshold- 스케줄러가 실패한 것으로 간주되기 전에 다음 실행 시간을 지난 트리거를 허용하는 시간이다. (ms 단위)
org.quartz.scheduler.instanceId- 모든 스케줄러들 중 유일해야 한다.
AUTO인 경우 인스턴스 ID를 임의로 생성한다.SYS_PROP인 경우 시스템 속성에서 사용한다.
<bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
...
<property name="quartzProperties">
<props>
<prop key="org.quartz.jobStore.class">org.quartz.impl.jdbcjobstore.JobStoreTX</prop>
<prop key="org.quartz.jobStore.driverDelegateClass">org.quartz.impl.jdbcjobstore.StdJDBCDelegate</prop>
<prop key="org.quartz.jobStore.dataSource">dataSource</prop>
<prop key="org.quartz.jobStore.tablePrefix">QRTZ_</prop>
<prop key="org.quartz.jobStore.isClustered">true</prop>
<prop key="org.quartz.jobStore.clusterCheckinInterval">1000</prop>
<prop key="org.quartz.jobStore.misfireThreshold">1000</prop>
<prop key="org.quartz.scheduler.instanceId">AUTO</prop>
</props>
</property>
</bean>
스프링 컨텍스트 관련 설정은 끝났으니 실제 코드를 살펴보자. 먼저 BlogJob 클래스 코드를 살펴보자. jobExecutionContext의 스케줄러에서 applicationContext를 이용해 BlogService 스프링 빈 객체를 찾아서 사용한다.
package blog.in.action.job;
import blog.in.action.service.BlogService;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.context.ApplicationContext;
import org.springframework.scheduling.quartz.QuartzJobBean;
public class BlogJob extends QuartzJobBean {
private BlogService blogService;
@Override
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
try {
blogService = ((ApplicationContext) jobExecutionContext.getScheduler().getContext().get("applicationContext")).getBean(BlogService.class);
blogService.updateTest();
} catch (Exception e) {
e.printStackTrace();
}
}
}
BlogServiceImpl 클래스에는 실제 비즈니스 로직을 정의한다. 이번 예제에서는 “update test table” 로그를 출력한다.
package blog.in.action.service.impl;
import blog.in.action.dao.BlogDao;
import blog.in.action.service.BlogService;
import java.util.List;
import java.util.Map;
import java.util.logging.Logger;
import org.springframework.stereotype.Service;
@Service("blobService")
public class BlogServiceImpl implements BlogService {
private Logger logger = Logger.getLogger(BlogServiceImpl.class.getName());
private final BlogDao blogDao;
public BlogServiceImpl(BlogDao blogDao) {
this.blogDao = blogDao;
}
@Override
public void updateTest() {
logger.info("update test table");
List<Map<String, Object>> itemList = blogDao.selectTest();
for (Map<String, Object> item : itemList) {
blogDao.updateTest(item);
}
}
}
4. Spring Quartz Clustering Test
고가용성(HA, High Availability) 테스트를 수행한다. 쿼츠 수행 주기는 1초 간격이므로 1초마다 로그가 출력된다.
- 8080, 8081 포트(port)를 사용하는 두 개의 Tomcat 서버가 동작한다.
- 8081 포트 서버에서 쿼츠 Job이 실행되고 있다.
- 8081 포트 서버를 다운시키면 8080 포트 서버의 쿼츠 Job이 실행된다.
- 8081 포트 서버를 다시 시작시킨다.
- 8080 포트 서버를 다운시키면 8081 포트 서버의 쿼츠 Job이 실행된다.
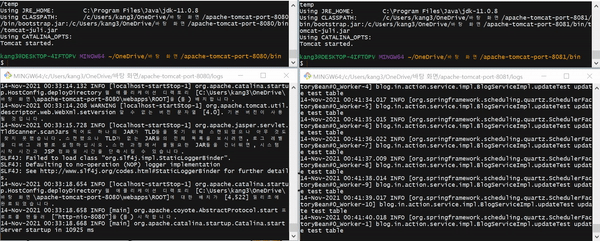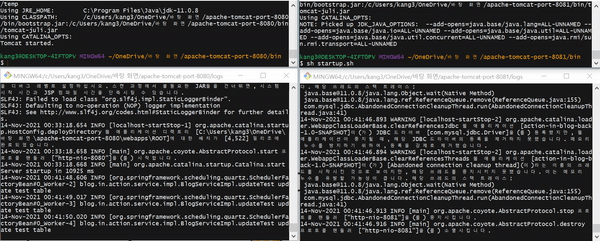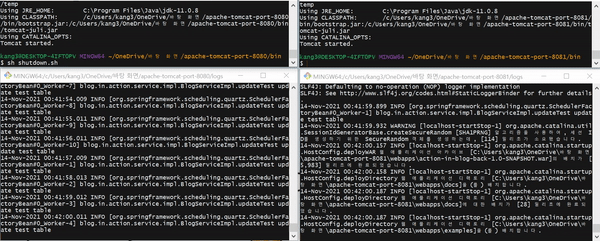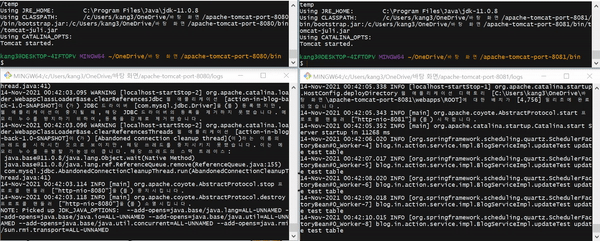
TEST CODE REPOSITORY
REFERENCE
- https://junhyunny.github.io/spring-mvc/quartz-in-spring-mvc/
- https://www.baeldung.com/spring-quartz-schedule
- https://advenoh.tistory.com/56
- https://uchupura.tistory.com/113
- https://developyo.tistory.com/251
- https://webprogrammer.tistory.com/2362
- [Quartz-3] Multi WAS 환경을 위한 Cluster 환경의 Quartz Job Scheduler 구현
- https://github.com/quartz-scheduler/quartz/blob/master/docs/configuration.adoc
- https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/scheduling/quartz/SchedulerFactoryBean.html
댓글남기기