


Skeleton detection in Python with mediapipe
0. 들어가면서
최근 프로젝트에서 달리는 사람의 스켈레톤(skeleton) 형상을 추출하는 애플리케이션을 개발했다. 회고 글에서도 이야기했지만, 구현 코드를 ChatGPT가 순식간에 만들어줬기 때문에 개발하는 시간이 매우 짧았다. 코드를 이해하고 데이터의 의미를 파악하는 데 시간을 더 소비했다. ChatGPT가 만들어준 코드를 이해하기 위해 공부한 내용을 글로 정리했다. 예제에선 이 샘플 비디오를 사용했다.
1. mediapipe package
스켈레톤 감지, 포즈 감지 관련된 예시를 찾아보면 다음과 같은 패키지들이 검색된다.
필자는 ChatGPT가 추천한 mediapipe 패키지를 사용했다. 필자는 머신 러닝이나 AI 전문가가 아니기 때문에 mediapipe 패키지가 어떤 모델 혹은 어떤 알고리즘을 사용하는지 자세히 파고 들진 않았다. 먼저 사용 가능한지 라이센스를 살펴봤다.
- 상업 용도 가능
- 사적 용도 가능
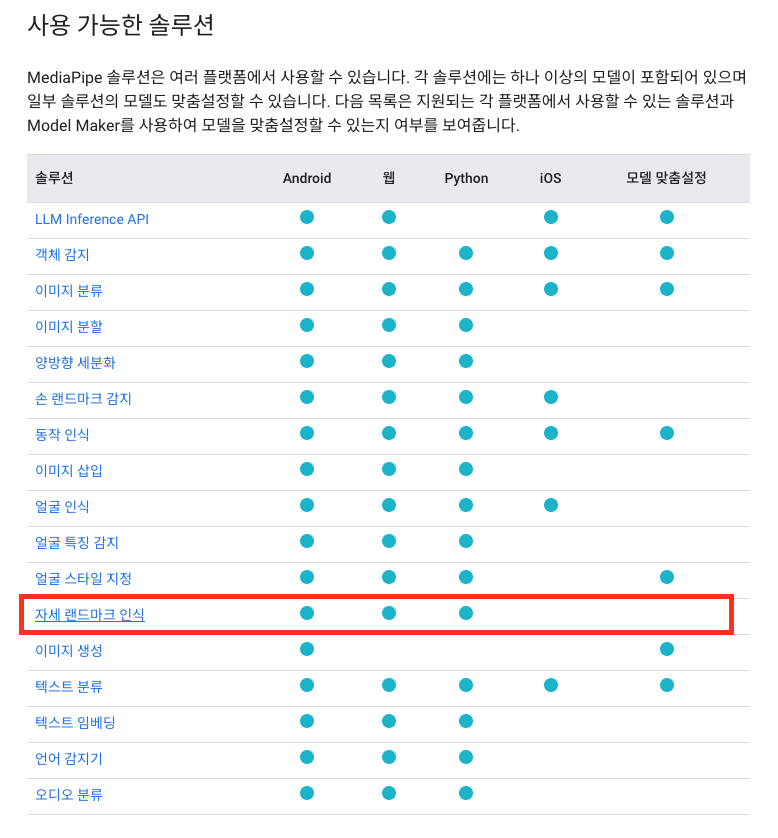
mediapipe 패키지는 여러 플랫폼에서 다양한 솔루션을 지원한다.
- 안드로이드, iOS, 웹, 파이썬 환경을 지원한다.
- 자세 랜드마크(스켈레톤 감지) 외에도 다양한 솔루션을 제공한다.
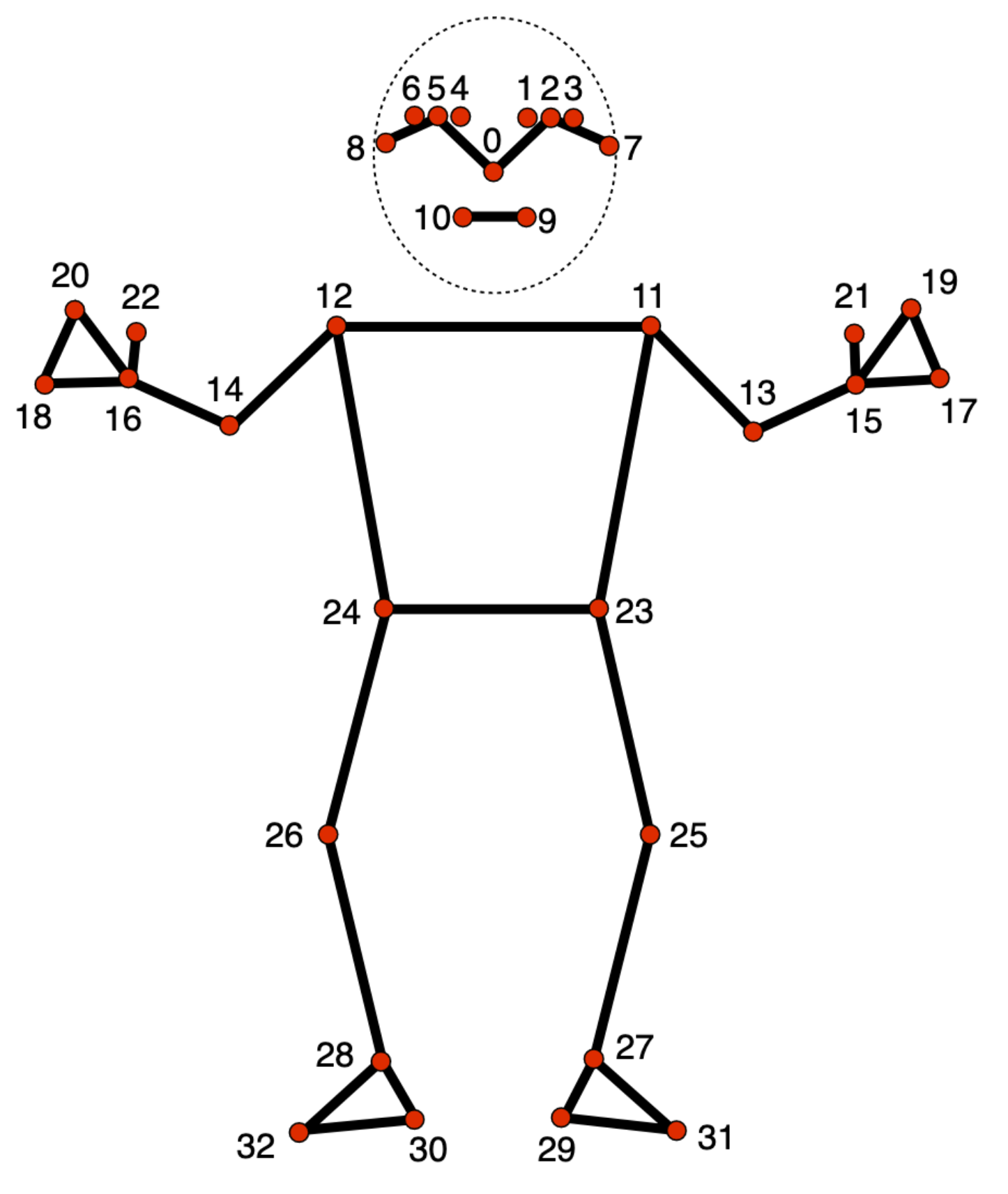
2. Pose landmark detection in mediapipe
내가 필요한 기능은 자세 랜드마크 인식 솔루션이다. 주요 신체 위치를 식별하고 자세를 분석하며 움직임을 분류할 수 있다. 단일 이미지 또는 동영상에 적용할 수 있다. 신체 부위 33개가 포즈 랜드마크 모델에 의해 감지된다. 각 신체 부위는 다음과 같다.
- 각 신체 부위 별로 인덱스가 지정되어 있다.
- 각 신체 부위 이름을 확인하고 싶다면 이 링크를 참고하길 바란다.
포즈 랜드마크 모델에 의해 감지되는 랜드마크(landmark) 데이터는 두 가지 존재한다. 동시에 값을 얻을 수 있다. 먼저 정규화 된 랜드마크(Landmarks) 데이터를 살펴보자.
- x 및 y는 이미지 너비(width)와 높이(height)를 사용해 0.0 ~ 1.0 사이의 값을 갖도록 정규화 된 좌표 값이다.
- z는 랜드마크 깊이로 엉덩이 중간 지점의 깊이가 출발지로 사용된다.
- 값이 작을수록 해당 부위가 카메라에 가깝다는 의미이다.
- 비디오를 보는 관찰자에게 가까워질수록 값이 작다.
- visibility 값은 이미지 내에 랜드마크가 표시될 가능성을 의미한다.
- 예를 들어 영상 내 관측 대상이 몸을 비틀어 오른쪽 어깨가 화면에서 보이지 않는 경우 오른쪽 어깨 랜드마크의 visibility 값은 0으로 수렴한다.
landmark {
x: 0.272968799
y: 0.417102337
z: -0.198333099
visibility: 0.992110193
}
다음은 세계 좌표(WorldLandmarks)를 살펴보자.
- x, y, z는 골반의 중간 지점을 출발지로 하는 실제 3차원 좌표(미터 단위)이다.
- visibility 값은 이미지 내에 랜드마크가 표시될 가능성을 의미한다.
landmark {
x: -0.053733781
y: -0.495982617
z: -0.309739351
visibility: 0.992110193
}
3. Example
필자는 다음 두 가지 결과물이 필요했다.
- 미래 AI 학습에 필요한 정규화 된 랜드마크 좌표
- 사용자가 브라우저에서 재생할 수 있는 스켈레톤 프레임이 씌워진 영상
정규화 된 랜드마크 좌표 데이터는 JSON 파일로 저장하고, 원본 비디오로부터 스켈레톤 프레임이 씌워진 영상을 만들었다. 두 결과물을 얻을 수 있는 예제 코드를 살펴보자. 먼저 다음 의존성들이 필요하다.
- opencv-python
- 비디오를 읽고 각 프레임을 추출한다.
- 스크레톤 라인이 그려진 프레임을 새로운 비디오 파일로 만든다.
- mediapipe
- 비디오 프레임으로부터 스켈레톤 데이터를 추출한다.
- 스켈레톤 데이터를 비디오 프레임에 그린다.
$ pip install opencv-python mediapipe
ChatGPT가 만든 코드에서 불필요한 부분을 제거하고 내가 이해하기 쉬운 구조로 재구성했다. 코드를 하나씩 뜯어 살펴보자.
- 랜드마크 데이터를 사용해 스켈레톤 프레임을 비디오 프레임 위에 그리기 위한 mp_drawing 모듈을 파일 전역에 선언한다.
- mediapipe 포즈 감지 솔루션 mp_pose 모듈을 파일 전역에 선언한다.
- Pose 객체를 파일 전역에 선언한다.
- Pose 객체를 생성할 때 옵션을 지정해 객체 감지 신뢰도를 조절할 수 있다.
- 자세한 내용은 구성 옵션 링크를 확인하길 바란다.
- 포즈 랜드마크의 각 신체 부위 배열을 파일 전역에 선언한다.
- 비디오 프로세스를 실행한다.
import json
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils # 1
mp_pose = mp.solutions.pose # 2
pose = mp_pose.Pose() # 3
POSE_LANDMARKS = [
"nose", "left_eye_inner", "left_eye", "left_eye_outer", "right_eye_inner", "right_eye", "right_eye_outer",
"left_ear", "right_ear", "mouth_left", "mouth_right", "left_shoulder", "right_shoulder", "left_elbow",
"right_elbow", "left_wrist", "right_wrist", "left_pinky", "right_pinky", "left_index", "right_index",
"left_thumb", "right_thumb", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle",
"right_ankle", "left_heel", "right_heel", "left_foot_index", "right_foot_index"
] # 4
...
process() # 5
스켈레톤 감지의 메인 실행 흐름인 process 함수를 먼저 살펴보자.
- 샘플 비디오를 읽는다.
- 샘플 비디오 메타 정보를 바탕으로 결과 비디오 파일을 생성한다.
- 화면의 너비와 높이, FPS 정보 등을 동일하게 만든다.
- 원본 비디오의 각 프레임을 읽는다.
- 원본 비디오의 모든 프레임을 읽을 때까지 반복 수행한다.
- 각 비디오 프레임으로부터 포즈 랜드마크 결과를 얻는다.
- 정규화 된 랜드마크는 pose_landmarks 변수를 통해 얻을 수 있다.
- 세계 좌표 랜드마크는 pose_world_landmarks 변수를 통해 얻을 수 있다.
- 랜드마크 데이터를 사용해 원본 비디오 프레임에 스켈레톤 프레임을 그린다.
- 각 프레임마다 랜드마크 데이터를 배열에 저장한다.
- 스켈레톤 프레임이 그려진 원본 비디오 프레임을 결과 비디오 파일에 출력한다.
- 프로세스 진행에 따라 한 프레임씩 결과 비디오 파일에 추가된다.
- 랜드마크 데이터를 JSON 파일로 저장한다.
def process():
frame_index = 0
result_json = []
capture = cv2.VideoCapture('input/sample.mp4') # 1
output = output_video(capture) # 2
while capture.isOpened():
ret, frame = capture.read() # 3
if not ret:
break
results = pose.process( # 4
cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
)
if results.pose_landmarks:
pose_landmarks = results.pose_landmarks
mp_drawing.draw_landmarks( # 5
frame,
pose_landmarks,
mp_pose.POSE_CONNECTIONS
)
result_json.append({ # 6
'frame': frame_index,
'landmarks': extract_landmarks(pose_landmarks)
})
frame_index += 1
output.write(frame) # 7
write_json('output/result.json', result_json) # 8
capture.release()
output.release()
위 비디오 프로세스에서 사용한 커스텀 함수들을 살펴보자. 먼저 output_video 함수는 다음과 같다.
- 원본 비디오로부터 화면 너비, 높이, FPS 정보를 획득한다.
- 원본 비디오와 동일한 사이즈, FPS 비디오를 생성할 수 있는 VideoWriter 객체를 반화한다.
- output 디렉토리에 result.mp4 비디오 파일을 생성한다.
- MPEG-4 Part 2 코덱(codec)을 사용하기 위해 fourcc(four character code)를 MP4V으로 지정한다.
def output_video(input_video):
frame_width = int(input_video.get(cv2.CAP_PROP_FRAME_WIDTH)) # 1
frame_height = int(input_video.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(input_video.get(cv2.CAP_PROP_FPS))
return cv2.VideoWriter( # 2
'output/result.mp4',
cv2.VideoWriter_fourcc(*'MP4V'),
fps,
(frame_width, frame_height)
)
다음 정규화 된 랜드마크로부터 필요한 데이터를 추출하는 extract_landmarks 함수를 살펴보자.
- 한 프레임마다 33개의 랜드마크를 배열에 담는다.
- 각 아이템의 데이터는 다음과 같다.
- x, y, z 좌표
- visibility 확률
- 신체 부위
POSE_LANDMARKS = [
"nose", "left_eye_inner", "left_eye", "left_eye_outer", "right_eye_inner", "right_eye", "right_eye_outer",
"left_ear", "right_ear", "mouth_left", "mouth_right", "left_shoulder", "right_shoulder", "left_elbow",
"right_elbow", "left_wrist", "right_wrist", "left_pinky", "right_pinky", "left_index", "right_index",
"left_thumb", "right_thumb", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle",
"right_ankle", "left_heel", "right_heel", "left_foot_index", "right_foot_index"
]
...
def extract_landmarks(pose_landmarks):
landmarks = []
for (idx, landmark) in enumerate(pose_landmarks.landmark): # 1
landmarks.append({ # 2
'x': landmark.x,
'y': landmark.y,
'z': landmark.z,
'visibility': landmark.visibility,
'body_part': POSE_LANDMARKS[idx]
})
return landmarks
마지막으로 JSON 파일을 저장하는 write_json 함수다.
- 지정한 경로에 JSON 파일을 만든다.
- 랜드마크 배열 데이터를 저장한다.
def write_json(output_json_path: str, result_json):
with open(output_json_path, 'w') as json_file: # 1
json.dump(result_json, json_file, indent=4) # 2
4. Run example
다음 명령어로 파이썬 애플리케이션을 실행한다.
$ python3 main.py
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1720024465.498568 4643108 gl_context.cc:357] GL version: 2.1 (2.1 Metal - 88.1), renderer: Apple M1 Pro
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
OpenCV: FFMPEG: tag 0x5634504d/'MP4V' is not supported with codec id 12 and format 'mp4 / MP4 (MPEG-4 Part 14)'
OpenCV: FFMPEG: fallback to use tag 0x7634706d/'mp4v'
W0000 00:00:1720024465.551066 4643189 inference_feedback_manager.cc:114] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
W0000 00:00:1720024465.559157 4643189 inference_feedback_manager.cc:114] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
/Users/junhyunkang/Desktop/action-in-blog/venv/lib/python3.12/site-packages/google/protobuf/symbol_database.py:55: UserWarning: SymbolDatabase.GetPrototype() is deprecated. Please use message_factory.GetMessageClass() instead. SymbolDatabase.GetPrototype() will be removed soon.
실행한 애플리케이션이 종료되면 다음 결과 영상을 output 디렉토리에서 볼 수 있다.
랜드마크 JSON 파일도 output 디렉토리에서 찾을 수 있다.
[
{
"frame": 0,
"landmarks": [
{
"x": 0.2730301320552826,
"y": 0.41813576221466064,
"z": -0.07867277413606644,
"visibility": 0.9938981533050537,
"body_part": "nose"
},
{
"x": 0.27328500151634216,
"y": 0.4106557071208954,
"z": -0.06848934292793274,
"visibility": 0.9853909015655518,
"body_part": "left_eye_inner"
},
...
]
},
{
"frame": 1,
"landmarks": [
{
"x": 0.2728402018547058,
"y": 0.4169551432132721,
"z": -0.20106975734233856,
"visibility": 0.9944910407066345,
"body_part": "nose"
},
{
"x": 0.27332279086112976,
"y": 0.409657746553421,
"z": -0.1893816888332367,
"visibility": 0.9868107438087463,
"body_part": "left_eye_inner"
},
...
]
},
...
]
TEST CODE REPOSITORY
REFERENCE
- https://github.com/google-ai-edge/mediapipe
- https://ai.google.dev/edge/mediapipe/solutions/guide?hl=ko
- https://ai.google.dev/edge/mediapipe/solutions/vision/pose_landmarker?hl=ko
- https://ai.google.dev/edge/mediapipe/solutions/vision/pose_landmarker/python?hl=ko
- https://stackoverflow.com/questions/78329439/how-to-normalize-hand-landmark-positions-in-video-frames-using-mediapipe
댓글남기기