


NoSQL
0. 들어가면서
현재 진행 중인 프로젝트에서 NoSQL 적용에 대한 이야기가 나왔다. 한번도 사용해보지 않았기 때문에 걱정이 앞섰다. 관련 기술 스택을 적용하기 전에 특징이나 장단점, 이슈 등에 대해 정리할 필요가 있다고 생각되었다.
1. NoSQL(Not Only SQL)
관계형 데이터베이스(RDB, relational database)에서 관리하는 데이터 형태에 맞지 않은 데이터가 많아지기 시작하면서 NoSQL이 주목받기 시작했다. 데이터 형태란 무엇일까? 형태에 따른 데이터 분류는 다음과 같다.
- 정형 데이터
- 형태가 정해져 있는 데이터이다.
- 관계형 데이터베이스, Spread Sheet, CSV 등이 사용한다.
- 반정형 데이터
- 형태가 있으나 데이터 모델을 준수하지 않는 데이터이다.
- XML, JSON, HTML, 로그 등이 있다.
- 비정형 데이터
- 데이터의 형태가 없으며 연산이 불가능한 데이터이다.
- 영상, 이미지, 음성, 텍스트 등이 있다.
전통적인 관계형 데이터베이스 시장을 지배하던 시절엔 정형 데이터가 주를 이루었다. 비즈니스 요건 사항에 맞는 데이터 형태와 규칙을 지정하고 그에 맞게 저장, 사용하였다. 예를 들어, 성별을 저장하는 Gender 컬럼에 남, 여를 표현하는 male, female을 저장하였다. 정형 데이터는 규칙을 따르는 값들이 저장되며 수치만으로 의미를 파악하기 쉬운 형태이다.
2000년 후반부터 인터넷이 활성화되고 SNS, 유튜브 같은 서비스들의 사용자가 늘어나면서 비정형 데이터의 양이 대폭 늘어나게 되었다. 데이터가 단순하지만 정해진 형태가 없었고, 세계적인 서비스들의 데이터 규모는 이전과는 비교할 수 없을 정도로 커지게 된다. 대량의 비정형 데이터가 발생하면서 이를 관계형 데이터베이스로 관리하는 것에 한계를 느끼게 된다.
정형 데이터를 관리하는 대표적인 방법인 관계형 데이터베이스와 이를 효과적으로 사용하기 위한 SQL
관계형 데이터베이스와 다른 방식으로 데이터를 다루는 방법이 등장하면서 이를 NoSQL(Not Only SQL)이라고 부르게 된다. NoSQL이라는 용어는 1998년 Carlo Strozzi에 의해 처음 사용되었으나 데이터 사이에 관계가 존재했기 때문에 지금 개념과는 조금 달랐다. 2009년 초 Johan Oskarsson에 의해 “오픈 소스 분산, 비 관계형 데이터베이스”를 논의하기 위한 이벤트가 조직되면서 다시 소개되었다.
2. Characteristics of NoSQL
NoSQL은 관계형 데이터베이스가 아닌 다른 형태의 데이터 저장 기술을 총칭한다. 제품에 따라 특성이 매우 다르기 때문에 전반적인 특징들에 대해 정리하였다.
- RDBMS와 다르게 데이터의 관계를 정의하지 않는다.
- ID를 제외한 다른 필드에는 어떤 종류의 데이터가 저장되어도 괜찮다.
- 테이블 스키마가 유동적이다.
- 트랜잭션을 통한 데이터 일관성보다는 결과적 일관성(Eventual Consistency)를 허용한다.
- 데이터 모델이 다양하다.
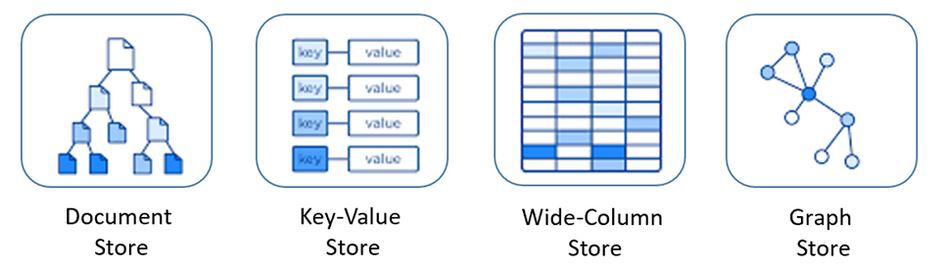
- Key-Value
- Wide-Column
- Graph
- Document
- 데이터를 질의하는 API가 다양하다.
- 제품마다 질의가 다르다.
- UnQL(Unstructured Query Language)라고 한다.
- 복잡한 질의를 하기 어려우므로 주로 저수준의 질의를 사용한다.
- 데이터베이스 중단 없이 서비스가 가능하며 자동 복구 기능이 지원된다.
- 분산형 컴퓨팅을 효과적으로 지원할 수 있도록 설계되었다.
- 수평적 확장(Horizontal Scaling)이 용이하다.
- 대부분이 오픈 소스 형태로 제공되고 있다.
3. NoSQL Data Models
많은 유형의 NoSQL들이 존재하지만 대부분의 글에서 대표적으로 언급하는 4가지 유형에 대해서만 정리해보았다. 각 유형별 특징과 대표하는 제품도 함께 소개한다.
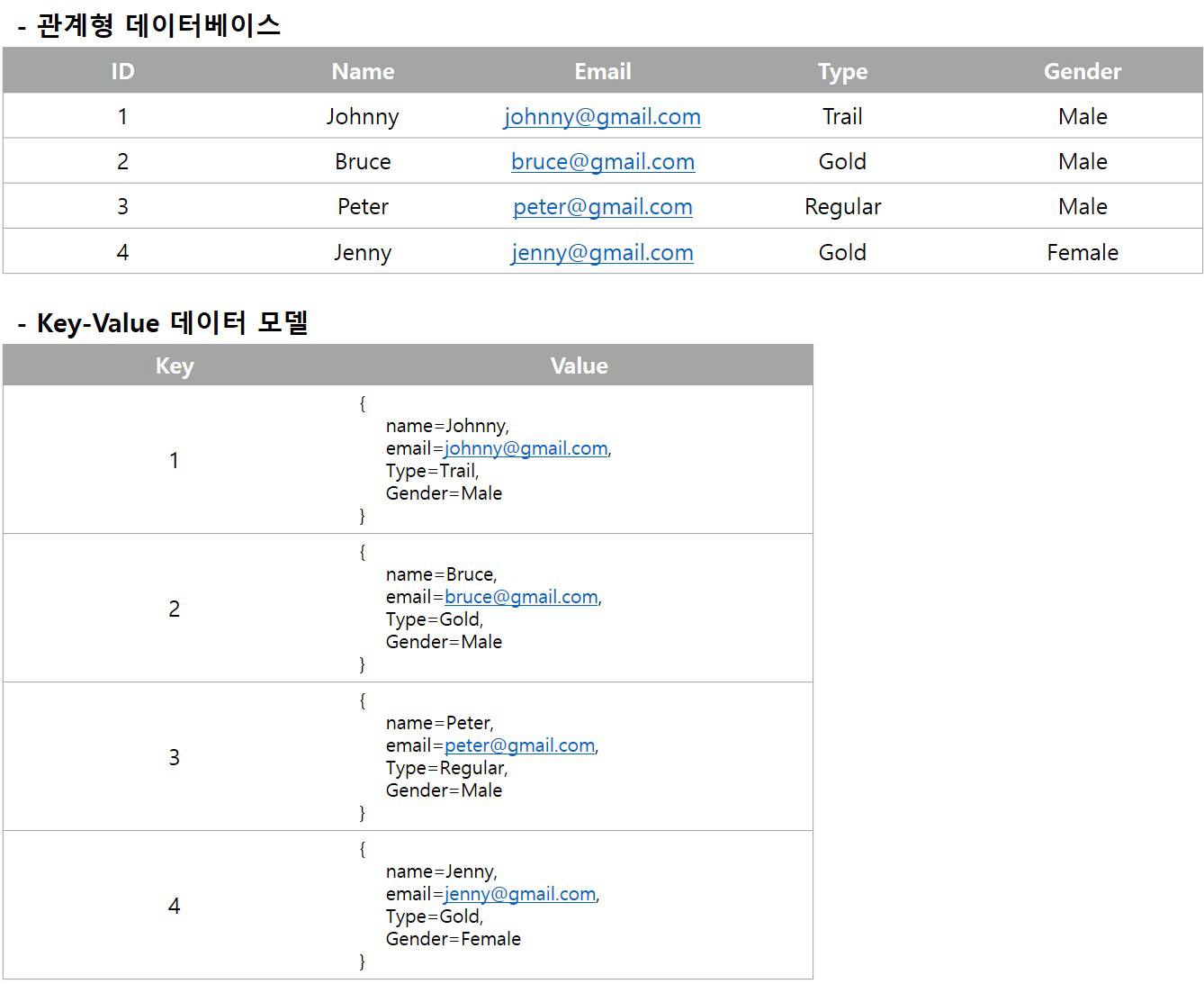
키(key)-값(value) 데이터 모델은 키-값의 쌍으로 데이터가 저장되는 가장 단순한 형태의 데이터 모델이다. 복잡한 조회 연산은 지원하지 않는다. 고속 읽기와 쓰기에 최적화된 경우가 많다. 구현하기 쉽지만 값의 일부분을 읽거나 업데이트하는 것이 매우 비효율적이다. 대표적인 제품들은 다음과 같다.
- Tokyo Cabinet/Tyrant
- Redis
- Voldemort
- Oracle BDB
- Amazon SimpleDB
- Riak
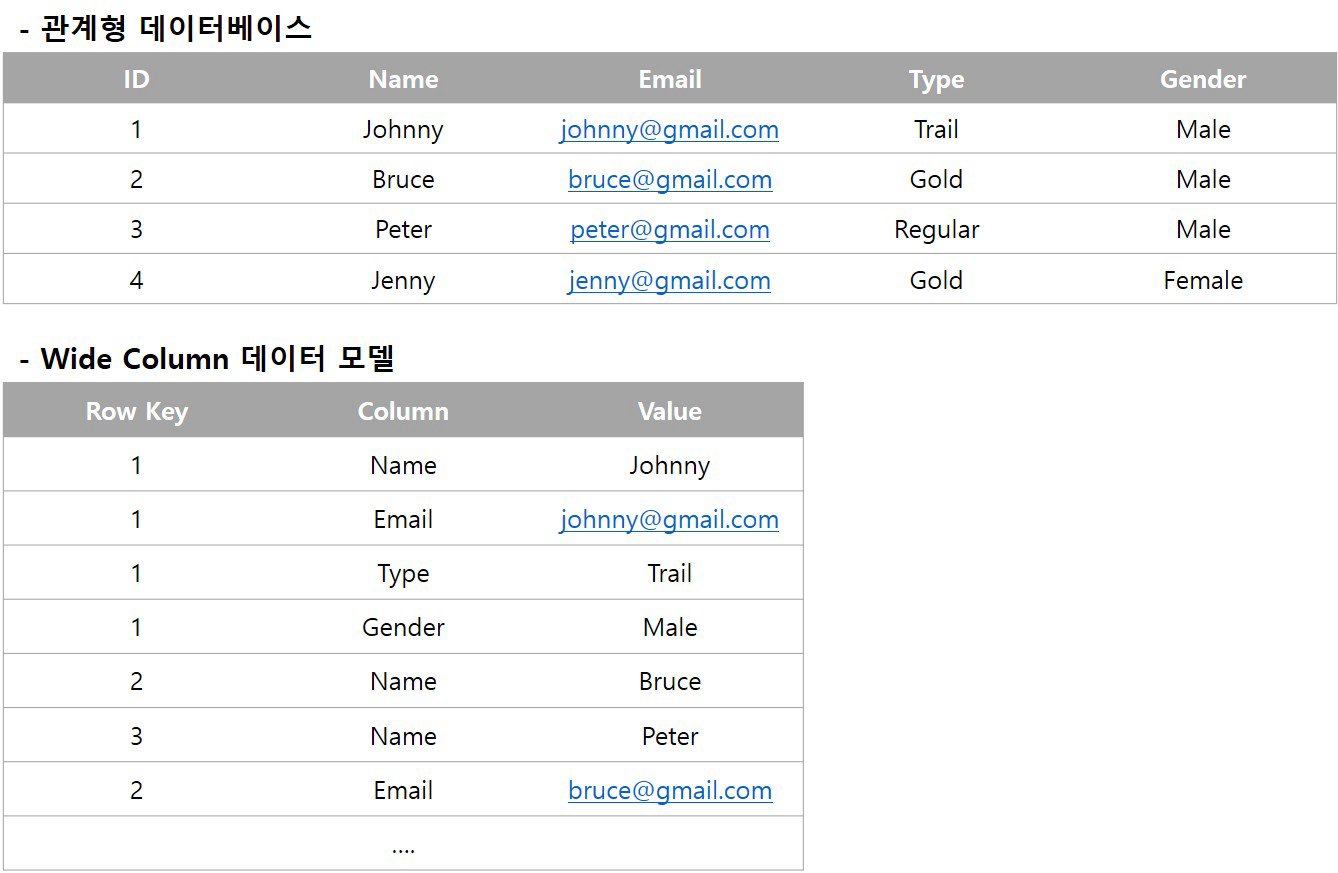
와이드 컬럼(wide column) 데이터 모델은 키-값으로 데이터를 저장하는 방식이 키-값 데이터 모델과 동일하다. 다만 데이터 덩어리가 아닌 컬럼 이름과 값이 각각 저장된다. 이 데이터 모델은 컬럼 가족(column family)라는 개념이 사용된다.
Wikipedia - Standard column family
A standard column family consists of a (unique) row key and a number of columns.
대표적인 제품들은 다음과 같다.
- HBase
- Cassandra
- ScyllaDB
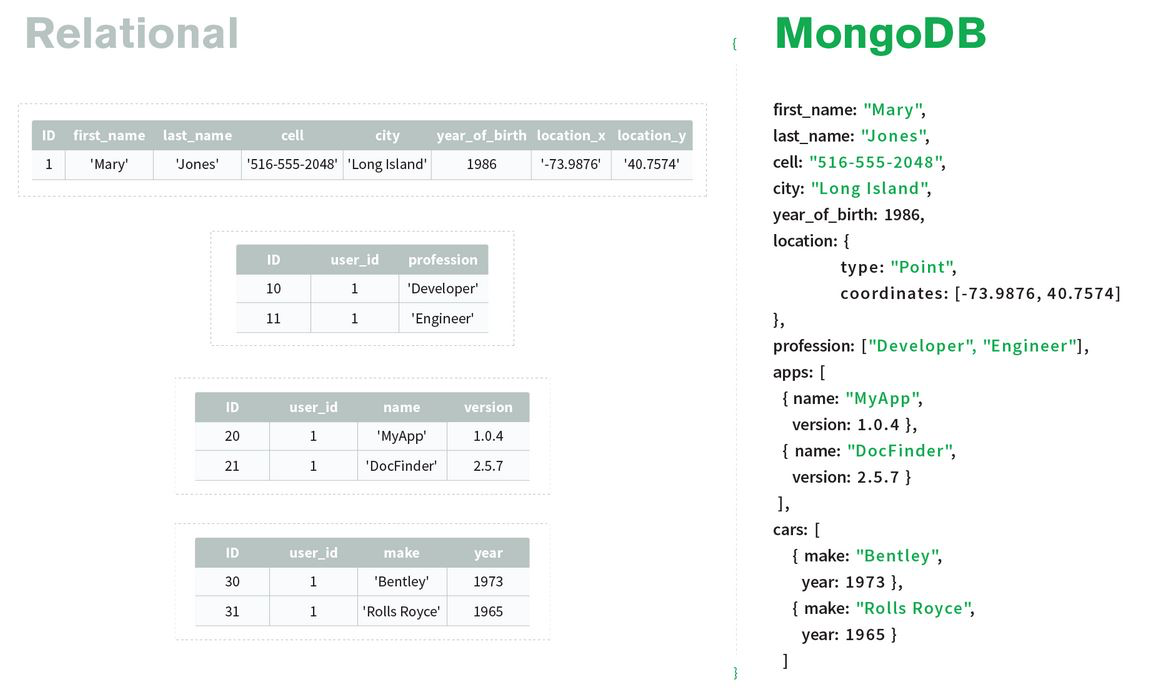
문서(document) 데이터 모델 키-값 데이터 모델의 확장된 형태이다. 값에 XML, JSON, Yaml 같은 문서 타입의 데이터를 저장한다. 복잡한 데이터 구조를 표현하는 것이 가능해졌다. 문서 ID 또는 속성 값을 기준으로 인덱스를 생성할 수 있다. 대표적인 제품들은 다음과 같다.
- MongoDB
- CoughDB
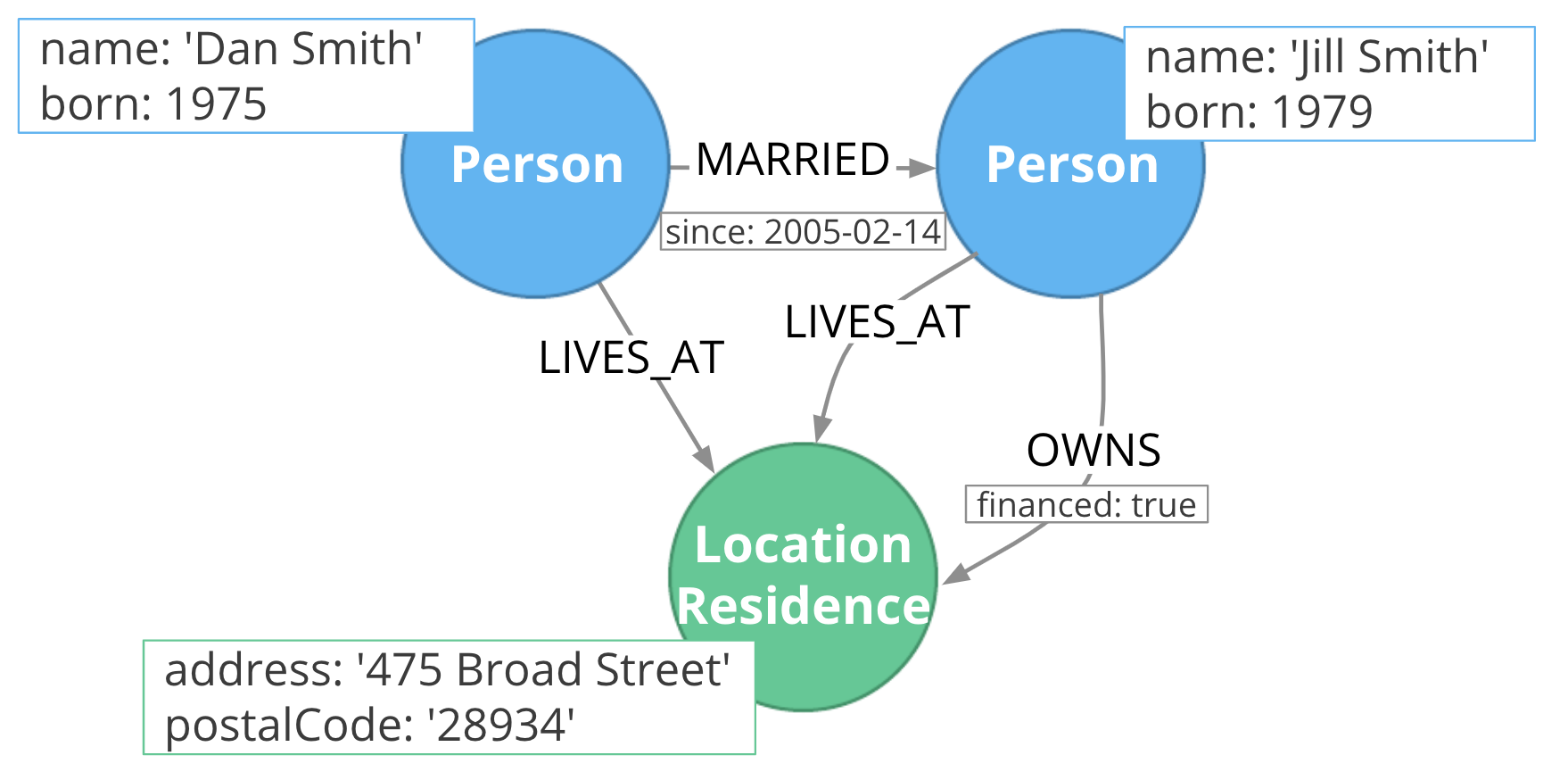
그래프(graph) 데이터 모델은 노드들과 그들 사이의 관계를 기반으로 구성된 데이터베이스이다. 노드들은 데이터 엔티티를 의미한다. 관계는 두 개의 노드가 어떤 연관이 있는지, 어떻게 연결되어 있는지 표현한다. 대표적인 제품들은 다음과 같다.
- Neo4J
- InfoGrid
- Infinite Graph
CLOSING
조사하는 과정에서 이런 내용을 발견하였다.
NoSQL이라는 새로운 기술과 제품군을 사용하려면, 그에 들어가는 교육과 개발 비용들이 결코 만만치 않다. 기존의 Oracle이나 MySQL과 같은 RDBMS를 사용해도 국내 대부분의 서비스는 구현이 가능하다. 데이터가 늘어나면 추가 RDBMS 클래스터를 추가해 용량을 증설하는 방법도 있다.
…
1억 명을 대상으로 한 서비스를 만들려고 시도할 때 NoSQL이 적합해 보이지만, NoSQL을 공부하는데 시간이 들어가고 운영하면서 수많은 장애를 겪다 보면 사용자들이 다 떨어져 나갈지도 모른다. MySQL 등 기존의 익숙한 기술을 사용하다가 MySQL로 도저히 용량 감당이 되지 않는 경우에 NoSQL로의 전환을 고려하는 것은 어떨까? MySQL로 용량이 안 된다면 그 때는 이미 사업이 성공했을 때이므로 NoSQL로 전환할 기술력이나 자금력이 충분할 것이다.
섣부르게 모르는 기술을 선택하기보단 손에 쥔 무기를 활용하고, 추후에 필요하다면 적용해야겠다는 생각이 들었다. 물론 미래를 고려해 기술 부채를 최소한으로 만드는 노하우가 필요할 것이다.
- 도메인 모델링
- 인터페이스를 활용한 결합도 낮은 설계
RECOMMEND NEXT POSTS
REFERENCE
- https://en.wikipedia.org/wiki/NoSQL#History
- https://philip1994.tistory.com/61
- https://esckey.tistory.com/107
- https://12bme.tistory.com/323
- https://neo4j.com/docs/pdf/neo4j-getting-started-4.2.pdf
- https://shoark7.github.io/programming/knowledge/what-is-NoSQL
- https://studio3t.com/knowledge-base/articles/nosql-database-types/
- https://docs.microsoft.com/en-us/dotnet/architecture/cloud-native/relational-vs-nosql-data
댓글남기기