


CQRS(Command Query Responsibility Segregation) 패턴
0. 들어가면서
마틴 파울러의 CQRS(Command Query Responsibility Segregation)에 관련된 글을 읽고 들었던 생각에 대해 정리했다. 패턴(pattern)의 원칙 자체는 어렵지 않지만, 구현할 때 시스템의 복잡성이 증가하고 다른 패턴이나 방법론 등이 함께 사용되면서 이해하는데 어려움을 겪는다. 이번 글은 순수하게 CQRS 패턴에 대한 내용만 다룬다.
1. CQRS(Command Query Responsibility Segregation) Pattern
CQRS(Command and Query Responsibility Segregation) - 명령과 조회의 책임 분리
시스템의 상태를 바꿀 수 있는 커맨드(command) 기능과 시스템의 상태를 확인하는 쿼리(query) 기능을 분할하여 개발하자는 원칙을 가진 패턴이다. 커맨드와 쿼리를 분리하려는 개념은 Bertrand Meyer의 Object Oriented Software Construction에서 CQS(Command Query Segregation)라는 용어를 통해 소개되었다. CQS(Command Query Segregation)에서 커맨드와 쿼리를 다음과 같이 정의한다.
- 커맨드 - 상태를 바꾸고 값을 반환하지 않는다.
- 쿼리 - 상태 변경 없이 조회만 수행한다.
해당 설명은 객체의 행동(method)에 대한 정의이지만, 이 개념이 아키텍처까지 확장되면 CQRS 패턴의 모습을 보여준다.
2. CQRS 패턴은 왜 사용하는가?
최초 설계한 도메인 모델은 시간이 지남에 따라 “데이터가 저장되는 모습”과 “보고 싶어하는 데이터 모습”이 달라진다. 저장하는 데이터의 모습과 보고 싶어하는 데이터의 모습이 바뀌는 이유는 다양하다. 시간이 지남에 따라 비즈니스 요건 사항이 정교해진다. 예를 들면 통계성 데이터의 추가를 원할수도 있고, 여러 모델의 데이터를 조합해서 보고 싶어하는 경우가 있다. UX(user experience) 측면에서 보고 싶은 데이터 모습이 복잡해지기 마련이다. 즉, 점점 쿼리가 어려워진다.
보통 모델은 도메인 모습을 따라가고, 영속성 데이터 저장소도 이를 따라 도메인의 모습을 반영한다. 정교해지는 비즈니스 요건은 쿼리를 복잡하게 만들고, 불필요한 항목들이 추가되면서 최초 설계한 모델을 무너뜨릴 수 있다. 다양한 표현들을 하나의 개념적인 모델으로 표현하기 점점 어려워진다.
이런 문제를 사전에 방지하기 위해 시스템의 상태를 변경하는 커맨드 책임과 상태를 반환하는 쿼리 책임을 구분짓는다. 커맨드는 데이터를 생성(create), 변경(update) 그리고 삭제(delete)를 수행한다. 쿼리는 데이터를 조회(read)하는 책임을 맡는다.
3. 어떻게 구현하는가?
반드시 커맨드와 쿼리를 서비스 수준으로 구분하거나 데이터베이스를 나눌 필요는 없다. 정답은 없으니 각자 상황에 맞게 이점을 최대한 취할 수 있는 아키텍처를 선택한다.
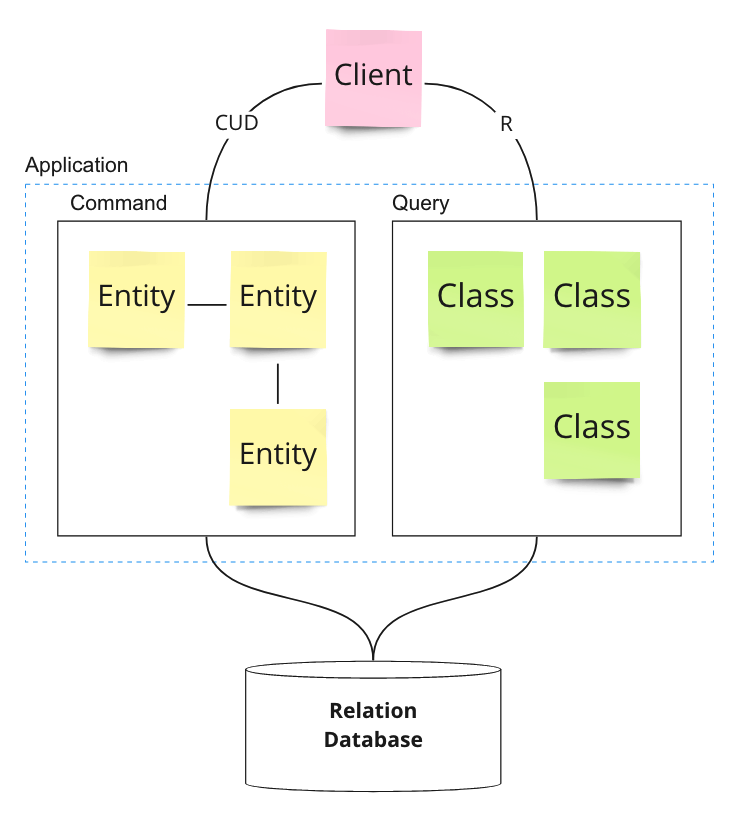
3.1. 코드 수준 분리
한 애플리케이션 내에서 커맨드 모델과 쿼리 모델을 분리한다.
- 책임을 코드 수준에서 분할한다.
- 비즈니스 요건 사항 변경에 맞는 변경을 각 모델에서 수행한다. 화면의 변경 사항으로 인해 엔티티를 변경하지 않아도 된다.
- 각자 다른 모델을 사용하기 때문에 변경에 영향도가 줄어든다.
- 단순하지만 확장성이 떨어지고, 최적화에 한계가 있다.
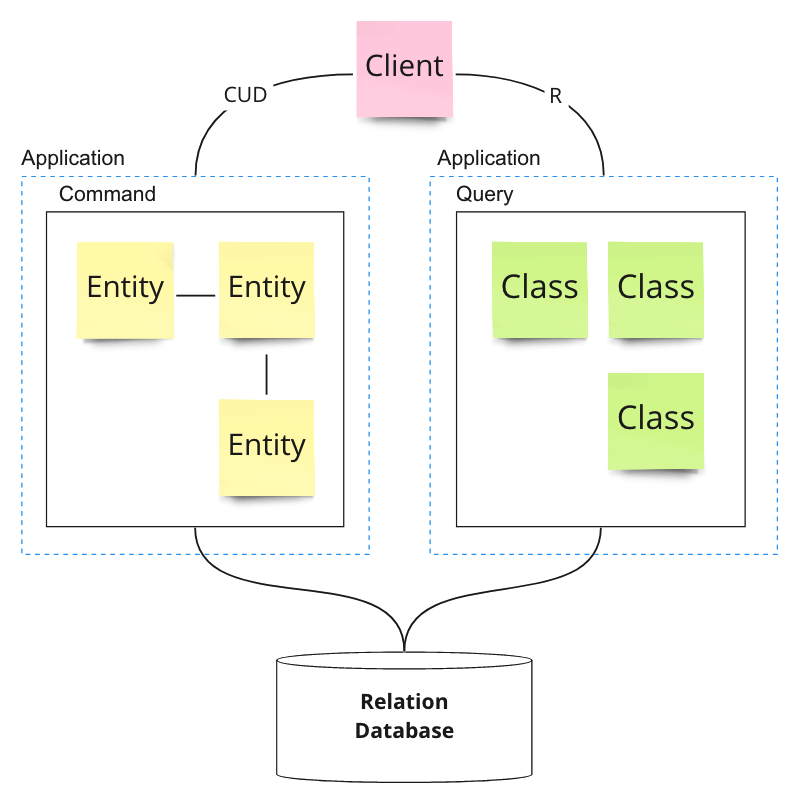
3.2. 서비스 수준 분리
커맨드 책임과 쿼리 책임을 서비스 수준으로 분리한다.
- 책임을 서비스 수준에서 분할한다.
- 각 서비스 별로 스케일(scale) 변경이 가능하다. 보통 쿼리 기능에 부하가 집중되는데 쿼리 서비스만 스케일 아웃하여 부하를 분산시킬 수 있다.
- 서비스 사이의 커플링(coupling)은 느슨해진다.
- 단순하게 모델을 분리하는 것에 비해 복잡성이 증가한다.
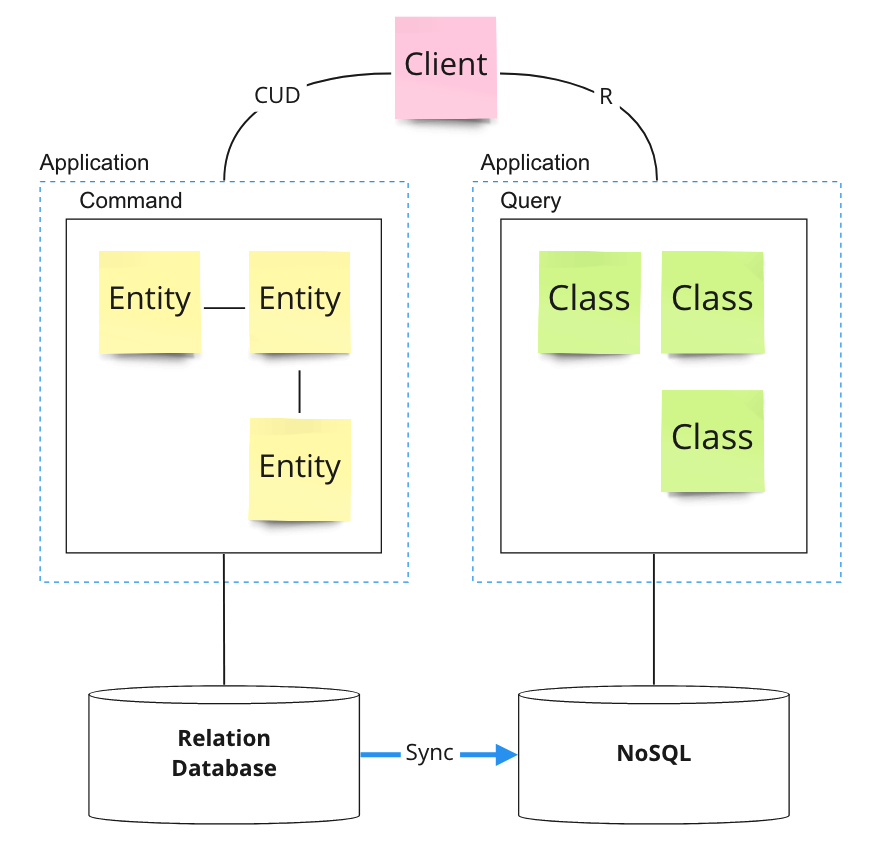
3.3. 데이터베이스 분리
- 각 서비스에 맞는 데이터베이스를 사용할 수 있도록 분리한다.
- 폴리글랏(polyglot) 저장소를 사용할 수 있다. 서비스의 강점을 살릴 수 있는 데이터베이스를 선택할 수 있다.
- 데이터베이스 사이의 동기화를 위한 방법을 고려해야 한다.
- 브로커를 이용한 메시지 처리
- 데이터베이스 CDC(Change Data Capture)
- 데이터 유실과 트랜잭션 범위에 대한 고민이 필요하다.
- 데이터 동기화로 인해 발생하는 최종적 일관성(eventually consistency)에 대한 고민이 필요하다.
- 시스템의 복잡성이 크게 증가한다.
4. When to use CQRS and not to use?
마틴 파울러는 CQRS 패턴을 적용할 수 있는 가이드들을 제시했다.
- 전체 시스템이 아닌 DDD 원칙의 바운디드 컨텍스트(bounded context)로 구분되는 시스템의 일부 영역
- 소수의 복잡한 비즈니스 도메인
- 고성능 애플리케이션 개발
마틴 파울러의 포스트를 읽으면서 받은 느낌은 “좋은 방법이긴 하지만, 고민 많이해보고 결정해.” 이다.
CQRS
Like any pattern, CQRS is useful in some places, but not in others. Many systems do fit a CRUD mental model, and so should be done in that style. CQRS is a significant mental leap for all concerned, so shouldn’t be tackled unless the benefit is worth the jump. While I have come across successful uses of CQRS, so far the majority of cases I’ve run into have not been so good, with CQRS seen as a significant force for getting a software system into serious difficulties.
… Despite these benefits, you should be very cautious about using CQRS. Many information systems fit well with the notion of an information base that is updated in the same way that it’s read, adding CQRS to such a system can add significant complexity. I’ve certainly seen cases where it’s made a significant drag on productivity, adding an unwarranted amount of risk to the project, even in the hands of a capable team. So while CQRS is a pattern that’s good to have in the toolbox, beware that it is difficult to use well and you can easily chop off important bits if you mishandle it.
CQRS 패턴이 맞지 않는 도메인에 적용하는 경우 시스템 복잡성과 프로젝트의 리스크는 커지고, 생산성은 줄어드는 결과를 얻게 된다. 단순히 몇 가지 기준들로 CQRS 패턴의 적용 여부를 결정하는 것은 큰 리스크가 있어 보인다. 프로젝트를 진행하는 팀원들과 충분한 대화를 통해 패턴의 적용 여부를 결정하면 좋을 것 같다.
댓글남기기