


Patterns for Cache
0. 들어가면서
효과적인 캐싱 전략을 펼치기 위한 캐시 패턴과 관련된 내용을 포스트로 정리하였습니다.
1. Inline Cache Pattern
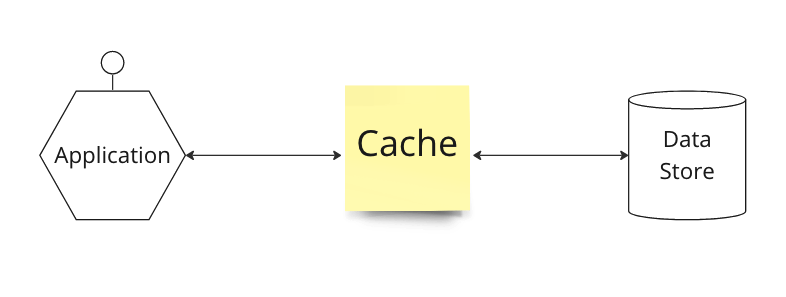
- 인라인 캐시(inline cache)는 애플리케이션과 데이터 저장소(data store) 사이에 존재합니다.
- 애플리케이션은 캐시 서버랑만 통신합니다.
- 애플리케이션은 코드의 변경 없이 일관된 방법으로 캐시를 사용할 수 있습니다.
- 캐시와 데이터 저장소의 동기화는 캐시 서버를 통해 이뤄집니다.
1.1. Read-Through
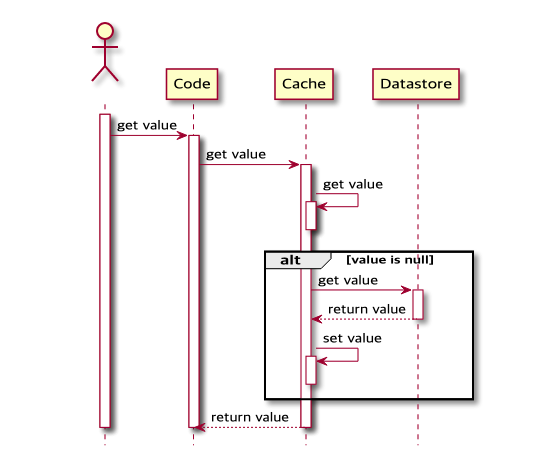
인라인 캐시 패턴에서 데이터를 조회하는 방법은 read-through입니다.
- 클라이언트 애플리케이션은 캐시 서버에서 데이터를 확인합니다.
- 캐시 서버는 자신에게 해당 데이터가 존재하는지 확인합니다.
- 데이터가 존재하면 이를 반환합니다.
- 데이터가 없다면 캐시 서버는 데이터 저장소로부터 데이터를 조회 후 자신을 최신화합니다.
- 캐시 서버는 최신화 이후 클라이언트 애플리케이션에게 데이터를 전답합니다.
1.2. Write-Through and Write-Behind
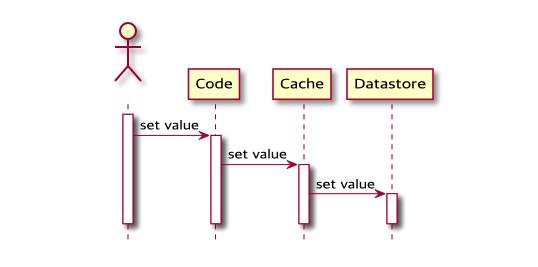
- 캐시 서버가 데이터 저장소에 데이터를 저장하는 책임을 가집니다.
- 클라이언트 애플리케이션은 캐시 서버에 데이터를 저장하거나 변경합니다.
- 캐시 서버는 변경된 내용을 데이터 저장소에 반영합니다.
- 동기적으로 수행하는 경우
write-through방식입니다. - 비동기적으로 수행하는 경우
write-behind방식입니다.
- 동기적으로 수행하는 경우
2. Cache Aside Pattern
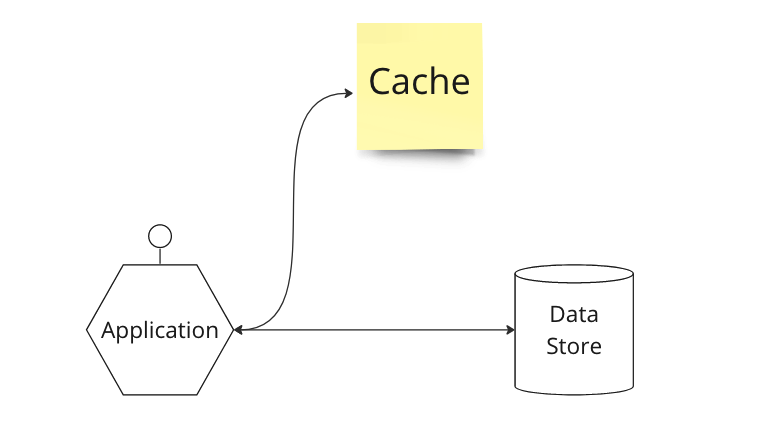
인라인 캐시 패턴처럼 캐시 서버가 자동적인 읽기, 쓰기를 통해 데이터 저장소와의 동기화를 해주지 않으면 캐시 배제(cache aside) 패턴을 고려합니다.
- 캐시 서버와 데이터 저장소 사이에 별도 통신은 수행하지 않습니다.
- 애플리케이션은 캐시 서버와 데이터 저장소 모두와 통신합니다.
- 애플리케이션이 캐시와 데이터 저장소 사이의 데이터를 직접 동기화합니다.
- 한번 읽었던 데이터는 잇따라 다시 읽을 가능성이 높기 때문에 캐시 적중률(hit rate)가 높습니다.
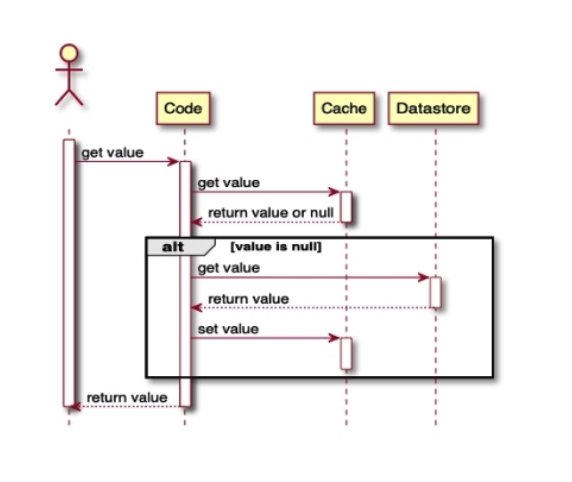
2.1. Read in Cache Aside Pattern
- 클라이언트 애플리케이션은 먼저 캐시를 조회합니다.
- 데이터가 존재하면 이를 사용합니다.
- 애플리케이션은 원하는 데이터가 존재하지 않으면 데이터 저장소에서 이를 조회합니다.
- 애플리케이션은 조회한 데이터를 캐시 서버에 저장합니다.
- 캐시 최신화 이후 애플리케이션은 조회한 데이터를 사용합니다.
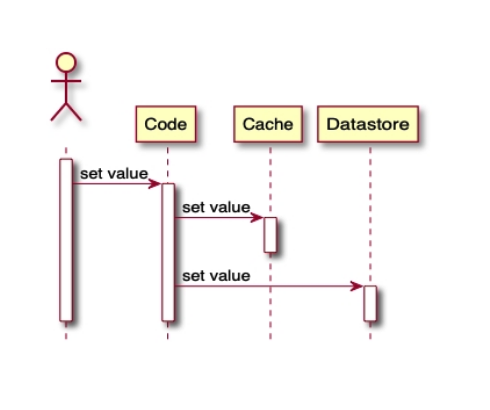
2.2. Write in Cache Aside Pattern
- 클라이언트 애플리케이션은 데이터를 저장하고자 합니다.
- 애플리케이션은 캐시에 데이터를 저장합니다.
- 애플리케이션은 데이터 저장소에 데이터를 저장합니다.
- 데이터를 저장하는 순서는 중요하지 않지만, 둘 중 하나라도 실패하는 경우 데이터 불일치가 발생할 수 있습니다.
- 두 저장소의 데이터 일관성을 위해 어느 한 곳의 저장이 실패하는 경우 이를 위한 예외 처리를 수행해야 합니다.
3. Considerations
인라인 캐시 혹은 캐시 배제 패턴 적용할 때 다음과 같은 사항들을 고려해야 합니다.
- 시간에 따른 캐시 만료
- 대부분의 캐시는 규정된 기간 동안 접근하지 않으면 데이터를 무효화하고 캐시를 삭제합니다.
- 로드(load)된 객체마다 적절한 TTL(time to live) 시간을 지정하는 만료 방식을 사용합니다.
- 캐싱은 변경이 적은 정적인 데이터 또는 자주 읽는 데이터에 가장 효과적입니다.
- 저장 용량에 따른 캐시 제거
- 캐시는 메모리 크기가 제한되기 때문에 필요한 경우 데이터를 제거해야 합니다.
- 대부분의 캐시는 오래 전에 사용한 항목을 제거하지만, 정책은 사용자가 지정할 수 있습니다.
- 높은 캐시 적중률을 보장할 수 있는 캐시 크기를 계산합니다.
- 최대 용량에 도달했을 때 캐시를 지우며 일반적인 제거 정책은 LRU(least recently used)입니다.
- 캐시 초기화
- 시작 처리 과정에서 애플리케이션에 필요한 데이터를 미리 캐시에 채울지 말지를 결정합니다.
- 일관성
- 데이터 저장소와 캐시의 일관성은 항상 보장되지 않습니다.
- 데이터 저장소의 항목은 외부 프로세스를 통해 언제든지 변경될 수 있습니다.
- 데이터 저장소에 변경된 내용들은 다시 캐시에 로드되지 않으면 반영되지 않습니다.
RECOMMEND NEXT POSTS
REFERENCE
- https://www.youtube.com/watch?v=mPB2CZiAkKM
- https://brunch.co.kr/@springboot/151
- https://docs.pivotal.io/p-cloud-cache/1-9/design-patterns.html
- https://hazelcast.com/blog/a-hitchhikers-guide-to-caching-patterns/
- https://learn.microsoft.com/ko-kr/azure/architecture/patterns/cache-aside
- https://aws.amazon.com/ko/builders-library/caching-challenges-and-strategies/
- https://www.gomomento.com/blog/6-common-caching-design-patterns-to-execute-your-caching-strategy
- https://j2wooooo.tistory.com/121
댓글남기기