


DynamoDB 단일 테이블 설계(Single Table Design)
RECOMMEND POSTS BEFORE THIS
0. 들어가면서
이번 프로젝트에서 DynamoDB를 처음 사용해봤다. 그리 나쁘진 않았지만, 테이블을 디자인 할 때 평소 사용하는 관계형 데이터베이스(RDBMS, relational database)와 전혀 다른 방식으로 접근해야 한다는 점이 상당히 어려웠다.
특히 DynamoDB는 데이터 접근 패턴에 따라 데이터 모델이 달라지는데 이 또한 우리 팀의 플랙틱스(practice)와 잘 맞지 않았다. 우리 팀은 애자일 방법론에 따라 목적 조직으로 움직인다. 매주 작은 단위의 기능들을 기획, 디자인, 개발한다. 이 과정에서 전혀 고려되지 않은 데이터 접근이 필요한 기능이 뜬금 없이 등장하면 이전 모델링을 다시 뒤집어 엎어야 하는 경우가 발생했다. 사정이 있어 어쩔 수 없이 DynamoDB를 사용했지만, 기획 초기 단계이거나 매주 작은 단위의 기능들을 점진적으로 발전시키는 애자일(agile) 팀이라면 DynamoDB는 좋은 선택이 아닌 것 같다.
1. Difference bewteen RDMBS and DynamoDB
DynamoDB는 AWS가 완전 관리형(full managed) NoSQL 데이터베이스다. DynamoDB 모델링에 관련된 여러 자료들을 보면 싱글 테이블 디자인을 권장한다는 사실을 알 수 있다. 관계형 데이터베이스만 사용해본 개발자라면 “이게 무슨 소린가?” 싶겠지만, 추후 살펴볼 싱글 테이블 디자인 예시를 살펴보면 이해가 될 것이다.
RDBMS는 데이터를 유연하게 조회할 수 있다. SQL 언어라는 강력한 무기로 조인(join) 등을 통해 데이터를 유연하게 조회할 수 있다. 도메인 모델링을 한 후 필요에 맞는 SQL 쿼리를 만들어 데이터를 조회한다. 쿼리 최적화는 일반적으로 스키마 설계에 영향을 미치지 않는다. 반면, DynamoDB는 제한된 방식으로만 데이터를 조회할 수 있다. 그렇기 때문에 제한된 방법 내에서 데이터 접근 방식을 정의하고 이 요구사항에 맞게 데이터 구조가 결정된다.
- RDMBS는 데이터 모델링 후 적절한 SQL 쿼리(데이터 접근 방식) 작성
- DynamoDB는 데이터 접근 방식 정의 후 이에 맞도록 데이터 모델링
2. Single table design
DynamoDB는 데이터 규모에 상관 없이 밀리초 단위의 일관된 읽기, 쓰기 연산 속도를 권장한다. 확장성을 극대화 하기 위해 데이터를 기본적으로 여러 파티션에 나눠 저장한다. 이 장점을 극대화 하고 싶어서인지 조인을 지원하지 않는다. 조인을 위해 여러 파티션에 분산된 데이터를 모두 탐색하게 된다면 응답이 지연될 것이다.
데이터베이스 자체 조인이 지원되지 않기 때문에 애플리케이션 수준에서 논리적으로 조인을 수행한다면 차악(次惡)을 피하기 위해 최악을 선택하는 것일지도 모른다.
- 애플리케이션 수준에서 조인을 수행한다는 것은 하나의 결과를 얻기 위해 연쇄적인 데이터 요청을 한다는 의미이다.
- 애플리케이션에서 네트워크 I/O는 불확실하고 가장 느린 영역이다. 하나의 결과를 위해 여러 번의 순차적인 네트워크 요청을 수행하는 것은 성능이나 시스템의 문제를 일으킬 확률을 높이는 행위이다.
- 코드 복잡도도 늘어날 확률이 높다.
간단한 예를 들어보자. 다음과 같이 User, Order 두 개의 테이블이 DynamoDB에 구성되어 있다고 가정한다.
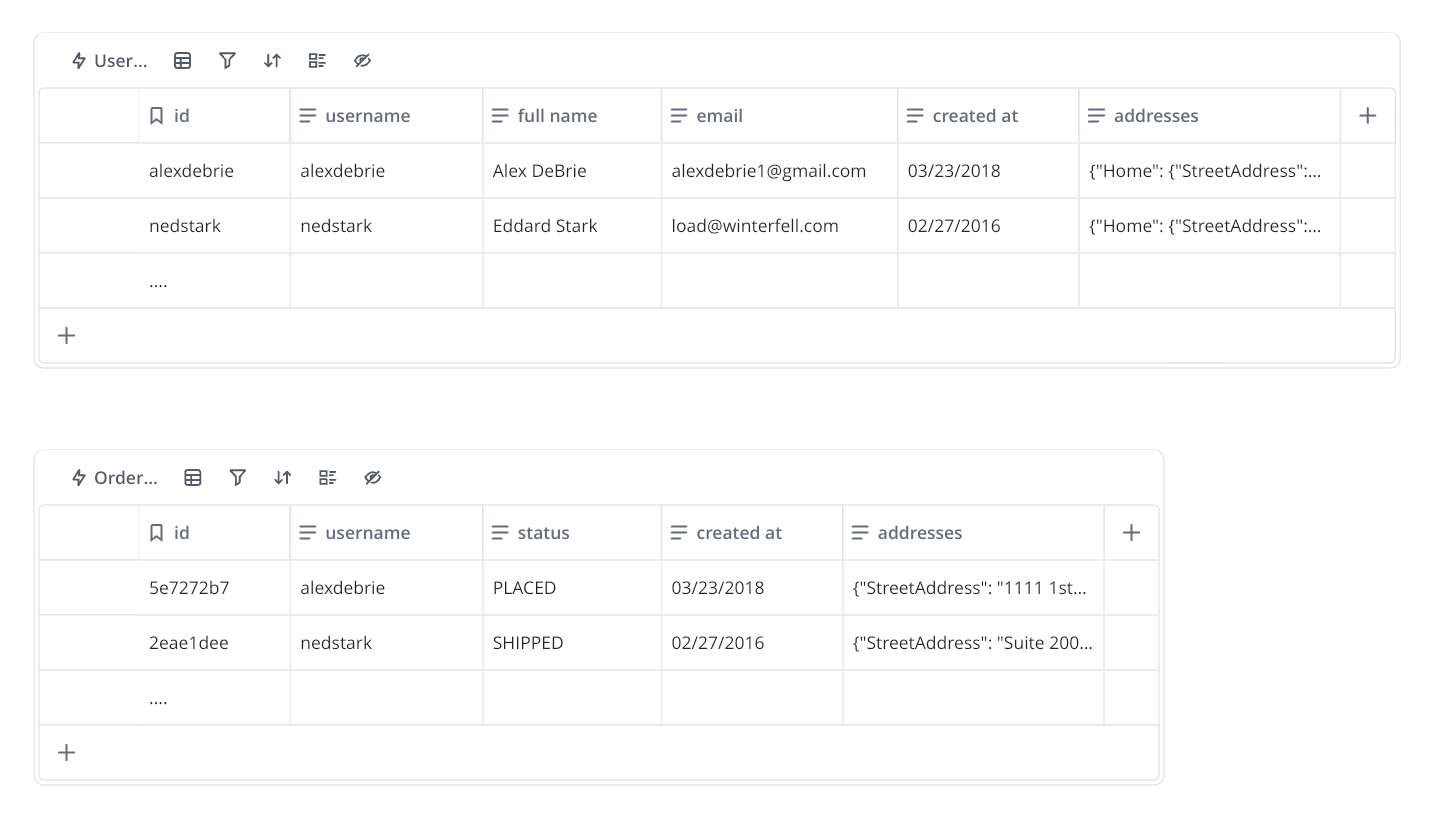
DynamoDB는 조인 연산을 지원하지 않기 때문에 애플리케이션은 DynamoDB로 두 차례 HTTP 조회 요청을 수행한다.
- 사용자 정보 조회
- username 속성을 통해 해당 사용자의 주문 조회
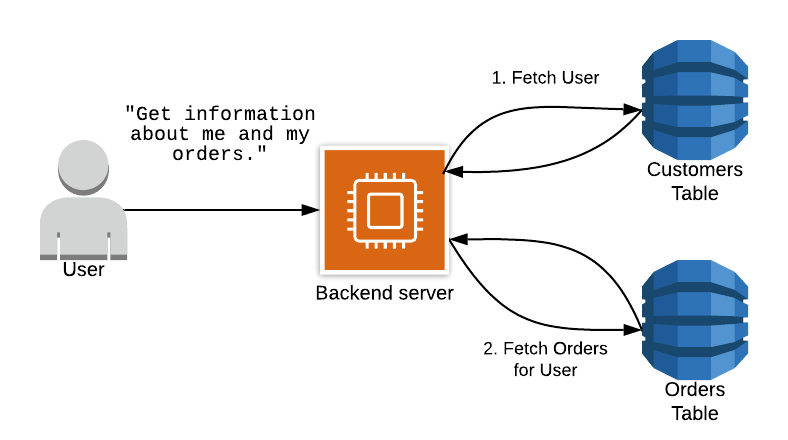
단순한 예제이기 때문에 두 차례 요청뿐이지만, 복잡한 비즈니스 케이스인 경우 여러 차례 통신이 필요하다. 해당 요청은 순차적인 HTTP 요청이다. 애플리케이션의 가장 불안한 요소(속도, 불확실성 등)인 네트워크 통신을 여러 차례 수행하는 것은 그리 좋지 못한 패턴이다.
Alex DeBrie의 글을 보면 이런 문제를 해결하기 위해 사전에 조인된 형태의 데이터 컬렉션을 하나의 테이블에 저장한다. 다만, 데이터 컬렉션을 저장할 때 조인이 필요한 데이터 그룹은 동일한 파티션 키(partition key)를 사용하도록 설계한다. 이렇게 설계하면 SQL 조인을 한 것처럼 한번의 조회만으로 필요한 데이터를 모두 조회할 수 있다.
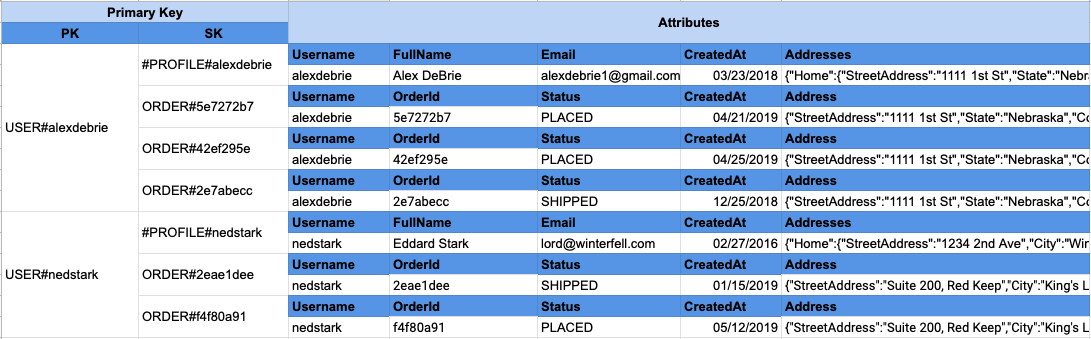
단일 테이블 설계의 핵심은 하나의 테이블에 모든 데이터를 저장하고, 데이터 구조를 튜닝하여 최대한 적은 수의 요청을 통해 DynamoDB로부터 필요한 데이터를 조회하는 것이다. 한번의 조회 요청만으로 필요한 데이터를 가져오는 것을 이상적으로 생각한다. DynamoDB가 제공하는 쿼리(query) 연산을 수행하면 필요한 여러 건의 데이터를 한번에 조회할 수 있다.
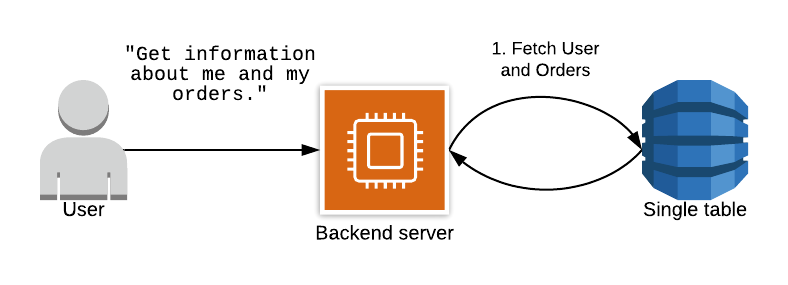
싱글 테이블 디자인의 장점은 요청 횟수를 줄이는 것 이외에 다음과 같은 것들이 있다.
- 다중 테이블은 매트릭, 모니터링 등에 대한 오버헤드가 있다.
- 다중 테이블은 싱글 테이블에 비해 비용이 비싸다.
싱글 테이블 디자인도 장점만 있는 것은 아니다. Alex DeBrie의 글에선 다음과 같은 단점들을 이야기한다.
- 싱글 테이블 디자인을 이해하기 위한 가파른 러닝 커브
- 새로운 액세스 패턴을 추가할 때 유연하지 못함
- 분석을 위한 테이블 내보내기(export) 어려움
이번 프로젝트에서 DynamoDB를 처음 사용해니 첫 번째, 두 번째 단점에 크게 공감이 된다. 첫 번째 가파른 러닝 커브는 RDBMS에만 익숙한 개발자가 도메인 설계를 고민할 때 DynamoDB의 액세스 패턴을 고려하지 않기 때문에 생기는 것 같다. 어느 정도 애플리케이션을 개발하면서 몇 번의 시행 착오를 겪다보면 금새 익숙해진다.
두 번째 새로운 액세스 패턴을 추가할 때 유연하지 못하다는 단점은 프로젝트를 내내 큰 문제라고 느꼈다. 새로운 액세스 패턴은 새로 개발할 기능(feature)이나 기존의 로직을 어떻게 변경할 것인지에 따라 전혀 고려되지 않은 방식이 필요할 수 있다. 새로운 기능의 추가나 기존 기능의 변경은 비즈니스 방향성에 따라 언제든 일어날 수 때문에 변동성이 굉장히 크다고 생각한다. 시스템을 크게 변경하고 싶지 않아 베이비 스텝(baby step), 주기적인 이터레이션(iteration)과 검증을 실천하는 애자일에 전혀 맞지 않는 데이터베이스라는 생각을 떨치기 힘들었다.
Alex DeBrie도 싱글 테이블 디자인을 사용하지 않아야 하는 케이스에 대해 다음과 같이 이야기하고 있다.
- in new applications where developer agility is more important than application performance.
- in applications using GraphQL.
CLOSING
새로운 액세스 패턴에 대응하기 위해 글로벌 인덱스(global index)나 마이그레이션 전략이 필요하다. 이번 프로젝트의 글로벌 인덱스 유즈-케이스(use-case)나 마이그레이션 경험은 다음 글들로 정리할 예정이다.
REFERENCE
- https://www.youtube.com/watch?v=DIQVJqiSUkE
- https://www.alexdebrie.com/posts/dynamodb-single-table/
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-general-nosql-design.html#bp-general-nosql-design-concepts
- https://www.bounteous.com/insights/single-table-design-with-aws-dynamodb-and-the-inverted-index/
댓글남기기