


DynamoDB 기초
1. Characteristics
모든 규모에서 10밀리초 미만의 성능을 제공하는 빠르고 유연한 NoSQL 데이터베이스이다. 완전 관리형 서비스(fully managed service)이다. AWS에서 DynamoDB 리소스에 대한 모든 관리를 해주는 서버리스 제품이기 때문에 서버 패치, 백업, 복원 같은 부가적인 유지보수가 불필요하다. DynamoDB는 1개의 지역(region)에 3개의 복제본(replica)을 만들어두기 때문에 장애가 나더라도 가용성을 유지할 수 있다.
- A, B, C 가용 영역(AZ, availability zone)에 각 파티션에 대한 복제본이 만들어진다.
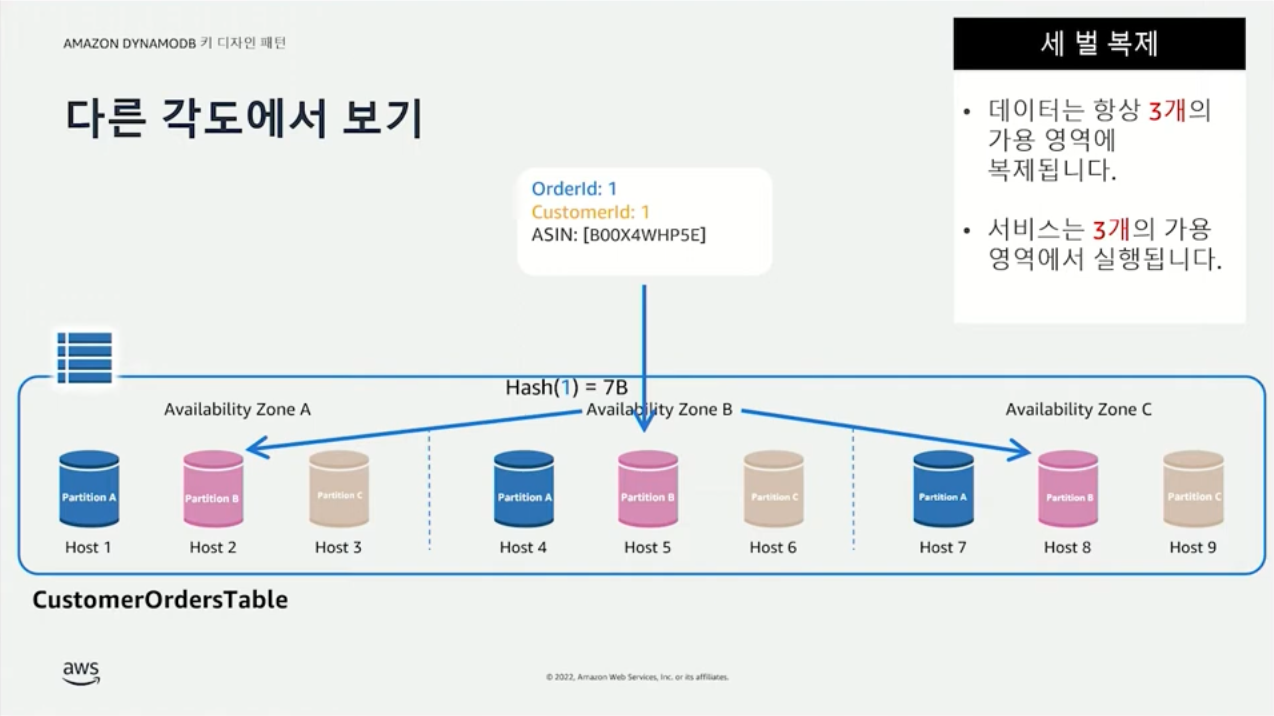
어떤 타이밍에 어떤 복제본으로부터 데이터를 읽는지에 일관성(consistency)이 맞지 않을 수 있다. DynamoDB는 읽기 연산에 대한 두 가지 수준의 일관성을 지원한다.
- 최종적 일관된 읽기(eventually consistent reads)
- 모든 복제본에 동기화되기 전에 데이터를 읽기 때문에 읽은 데이터가 최신 데이터가 아닐 수 있다.
- 강력한 일관된 읽기(strongly consistent reads)
- 오직 리더 노드(leader node)만 쓰기와 강력한 일관된 읽기를 지원한다.
- 리더 노드가 모든 복제본에 동기화 시킨 후에 데이터를 읽기 때문에 항상 최신 데이터를 유지한다.
2. Mode
다음과 같은 두 가지 모드를 지원한다.
- 프로비저닝 모드(provisioned mode)
- 온디맨드 모드(ondemand mode)
프로비저닝 모드는 사전에 정의된 읽기 및 쓰기 용량(throughput)을 미리 지정하고, 이를 기준으로 리소스를 관리하도록 설정하는 방식이다. 작업량(workload)에 따라 프로비저닝 된 처리량이 부족한 경우 오토 스케일링(auto scaling)을 통해 읽기 용량(RCU, read capacity units)와 쓰기 용량(WCU, write capacity units)를 조정할 수 있다. 처리량을 미리 지정하기 때문에 트래픽 변동이 적은 경우 비용을 효율적으로 관리할 수 있다. 일정하고 예측 가능한 트래픽 패턴을 가진 경우 적합하다. 예상 트패픽 패턴을 정확히 파악하지 못하는 경우 용량 부족(throttling)이나 용량 낭비가 발생할 수 있다. 오토 스케일링을 사용하면 비용 측면에서 높은 값의 고정된 프로비저닝 용량을 사용하는 것보다 이득을 볼 수 있다.
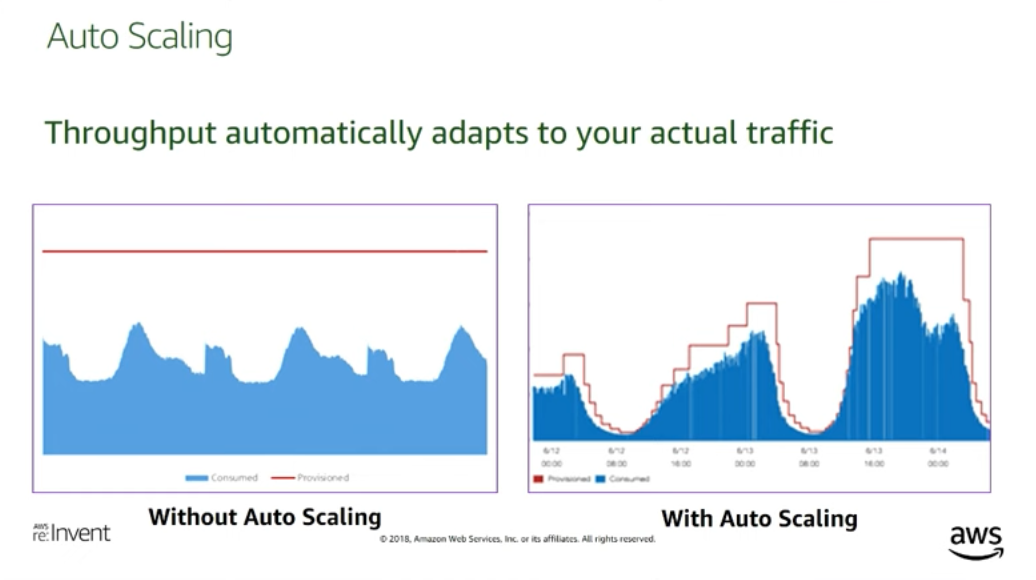
온디맨드 모드는 사용한 만큼만 비용을 지불한다. 트래픽이 갑자기 증가하거나 감소하더라도 DynamoDB가 자동으로 처리량을 확장하거나 축소한다. 트래픽 패턴을 예측하지 않아도 되고, 설정에 따른 성능 문제나 요청 제한을 신경쓸 필요가 없다. 매우 높은 트래픽이 장기간 유지되는 경우에는 비용이 급격히 증가할 수 있다.
| 특성 | Provisioned Mode | On-Demand Mode |
|---|---|---|
| 요금 | 설정한 RCU/WCU 용량에 따라 비용 발생 | 사용된 읽기/쓰기 요청 수에 따라 비용 발생 |
| 트래픽 변화 대응 | 수동 설정 또는 Auto Scaling 필요 | 자동으로 트래픽 변화에 대응 |
| 적합한 워크로드 | 일정하고 예측 가능한 트래픽 | 변동성 있는 트래픽, 간헐적 워크로드 |
| 초과 요청 처리 | 설정 용량 초과 시 요청이 제한(Throttle)될 수 있음 | 요청 초과 시에도 자동으로 처리량 확장 가능 |
| 설정의 복잡도 | 처리량(RCU/WCU) 설정 및 조정 필요 | 설정이 간단, 추가 조정 필요 없음 |
| 비용 효율성 | 트래픽이 안정적이고 지속적일 때 비용 효율적 | 트래픽이 간헐적이거나 변동이 클 때 비용 효율적 |
| 확장성 | 설정한 용량 범위 내에서 확장 가능 | 무제한 확장 가능 |
| 운영 부담 | 처리량 설정과 모니터링 필요 | 운영 부담 없음 |
3. Backups
DynamoDB는 테이블 크기에 관계 없이 몇 초안에 백업을 완료하고, 모든 백업은 자동으로 암호화한다. 직접 테이블 백업을 만들수도 있지만, PITR(Point-in-Time Recovery, 특정 시점 복구)이라는 기능을 제공한다. PITR은 DynamoDB 테이블의 데이터를 최대 35일간 지속적으로 데이터를 사용자 지점 시점으로 복구할 수 있도록 모든 데이터의 변경 사항을 기록한다. 복구 가능한 시간 범위 내의 특정 초 단위로 테이블 상태를 복원할 수 있다. 복구 가능한 시간 범위는 최대 35일 전부터 현재 시점까지이며 그 이전 데이터는 복구할 수 없다.
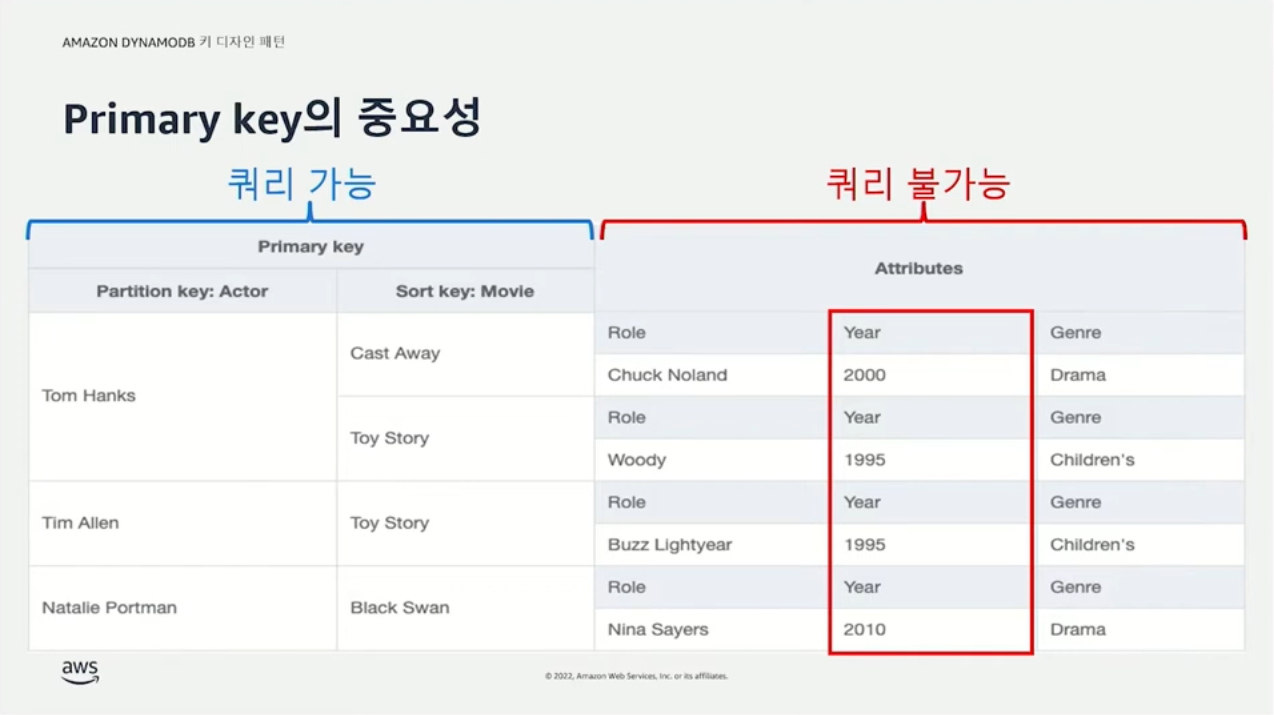
4. Key types, attributes and item
DynamoDB 테이블은 다른 데이터베이스들과 마찬가지로 데이터의 집합이다. RDBMS(relational database management system)의 테이블은 데이터 로우(row)와 컬럼(column)을 통해 구성된다. DynamoDB는 아이템(item)과 속성(attribute)으로 구성된다. 데이터 로우가 아이템으로, 컬럼이 속성 동일한 개념이라고 생각하면 이해하기 쉽다.
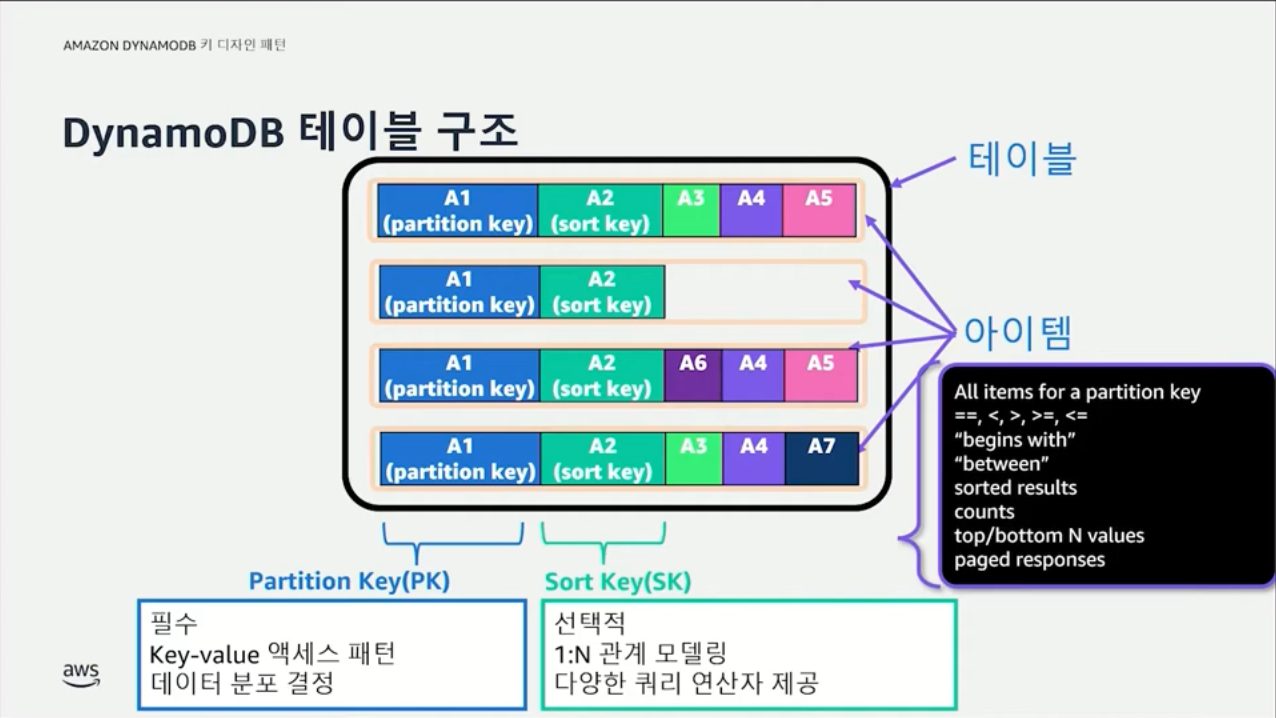
DynamoDB에는 특별한 속성이 두 개 존재한다. 이를 키(key)라고 부른다.
- 파티션 키(partition key)
- 정렬 키(sort key)
파티션 키만 사용할수도 있고, 파티션 키와 정렬 키를 함께 사용하는 것도 가능하다. 파티션 키와 정렬 키를 함께 사용하는 것을 복합 키(composite key)라고 한다. 아이템을 식별할 수 있는 방법이 기본 키(primary key)이기 때문에 파티션 키만 사용하는 경우 파티션 키가 기본 키가 되고, 복합 키를 사용하는 경우 파티션 키와 정렬 키의 조합이 기본 키가 된다.
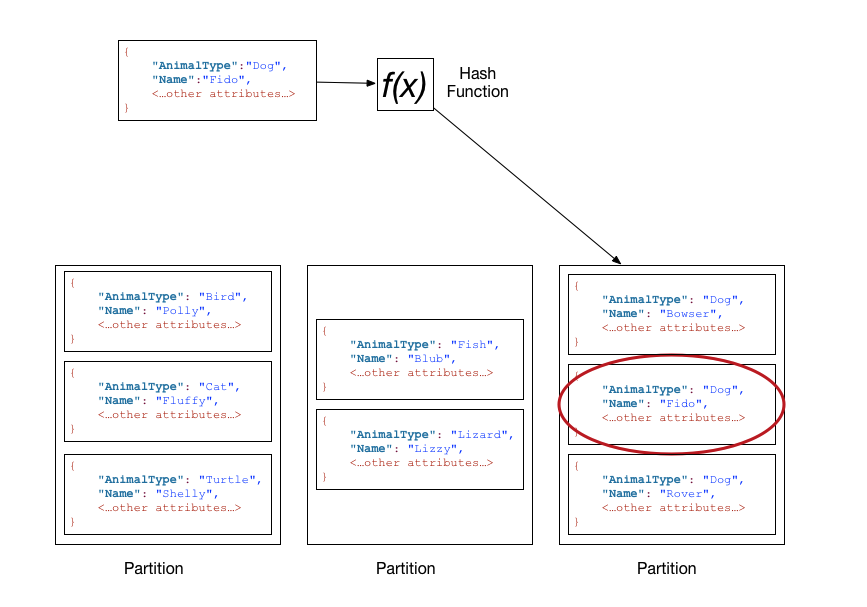
파티션 키는 필수(required) 값으로 key-value 액세스 패턴을 통해 데이터를 조회할 수 있다. 동등(equal, ==) 연산을 통해 파티션 키 값에 해당하는 아이템을 조회할 수 있다. 파티션 키는 조회뿐만 아니라 데이터 분포를 위해 사용된다. 아이템의 파티션 키가 해시 함수를 통과하면 해시 값이 결정된다. 이 해시 값이 포함된 주소 범위를 갖는 파티션에 해당 아이템을 저장한다. 파티션은 3개의 레플리카 노드에 동일하게 존재하며 실시간으로 동기화된다. 파티션 키 값에 따라 데이터가 각 파티션에 균등하게 혹은 비균등하게 분할될 수 있다.
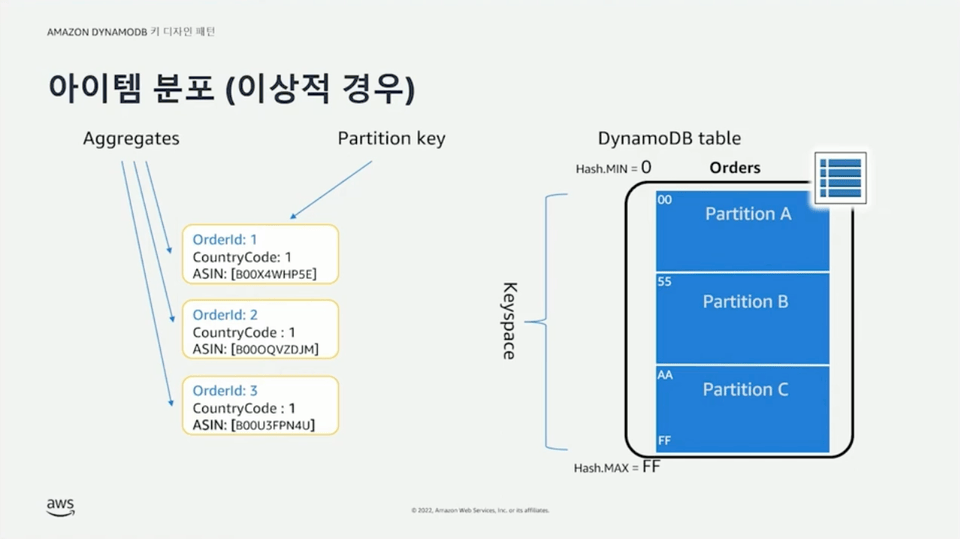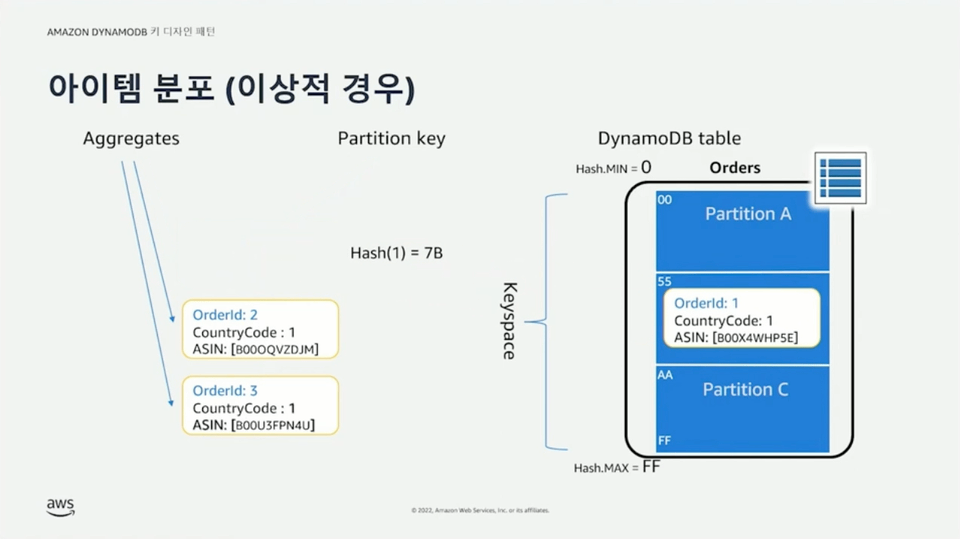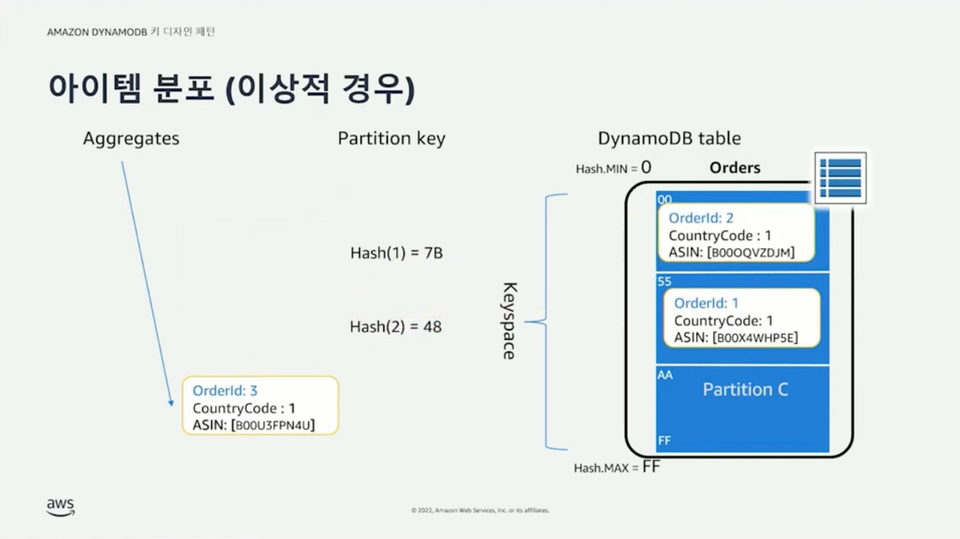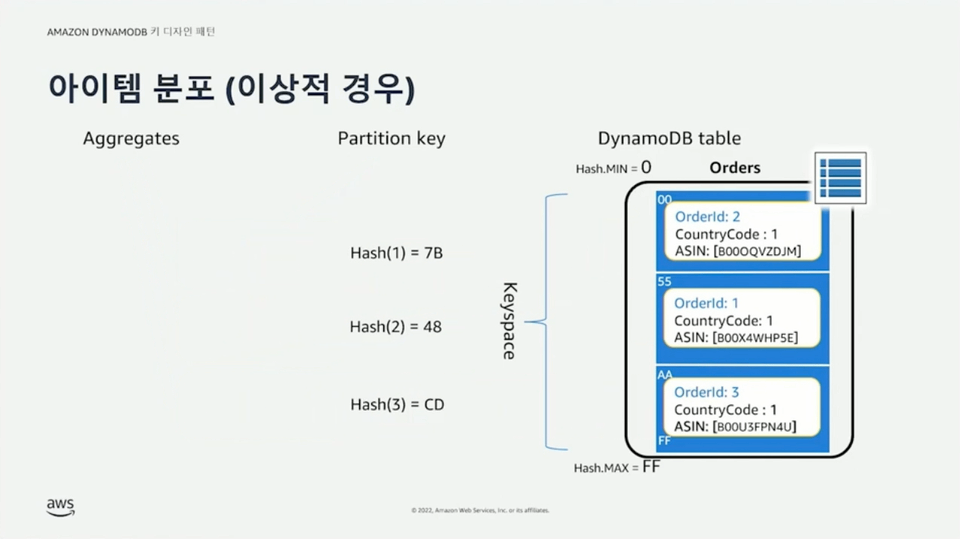
정렬 키는 옵션(optional) 값으로 파티션 내부에 동일한 파티션 키를 갖는 데이터들에 대한 정렬을 수행한다. 정렬 키를 사용하면 1:N 관계를 모델링 할 수 있다. 파티션 키만 사용하는 경우 여러 아이템이 동일한 파티션 키를 가질 수 없지만, 파티션 키와 정렬 키를 함께 사용하는 복합 키를 사용하는 경우 여러 아이템이 정렬 키를 통해 구분되기 때문에 동일한 파티션 키를 갖는 것이 가능하다. 이를 통해 1:N 관계가 성립할 수 있다. 정렬 키는 동등 연산뿐만 아니라 >, >=, <, <=, begins with, bewteen 같은 연산 조건들을 통해 동일한 파티션 키를 갖는 아이템들 중에서도 조건에 맞는 아이템들만 조회할 수 있다.
- 동일한 파티션 키 값을 갖는 아이템들 중 정렬 키 순서에 맞게 가운데 데이터가 위치한다.
5. Read Methods
DynamoDB에서 데이터를 다루는 다양한 방법을 제공한다. 그 중 데이터를 읽는 기본적인 방법 3가지에 대해 알아본다. 아래 3가지 외에도 BatchGetItem 같은 연산도 있지만, GetItem 연산의 연장선이기 때문에 이 글에선 다루지 않는다.
- GetItem
- Query
- Scan
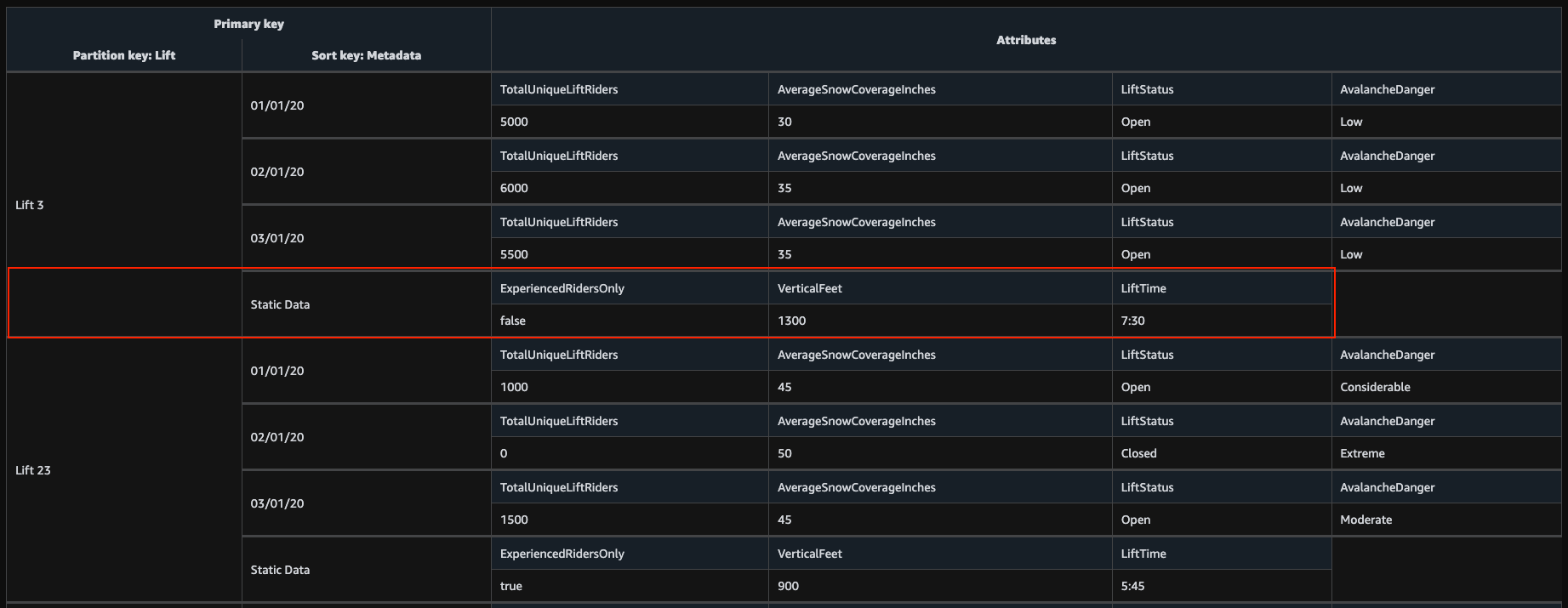
GetItem 연산은 기본 키(파티션 키 혹은 복합 키)를 알고 있을 때 하나의 데이터를 조회할 수 있는 방법이다. RDBMS에서 PK를 사용해 한 개의 데이터를 질의하는 연산(findById)과 동일하다. “Lift”, “Metadata”이라는 속성을 파티션 키, 정렬 키로 사용하는 테이블의 경우 다음과 같은 기본 키 정보를 통해 아이템을 조회할 수 있다.
$ aws dynamodb get-item \
--table-name SkiLifts \
--key '{"Lift": {"S": "Lift 3"}, "Metadata": {"S": "Static Data"}}'
아래 아이템이 조회된다.
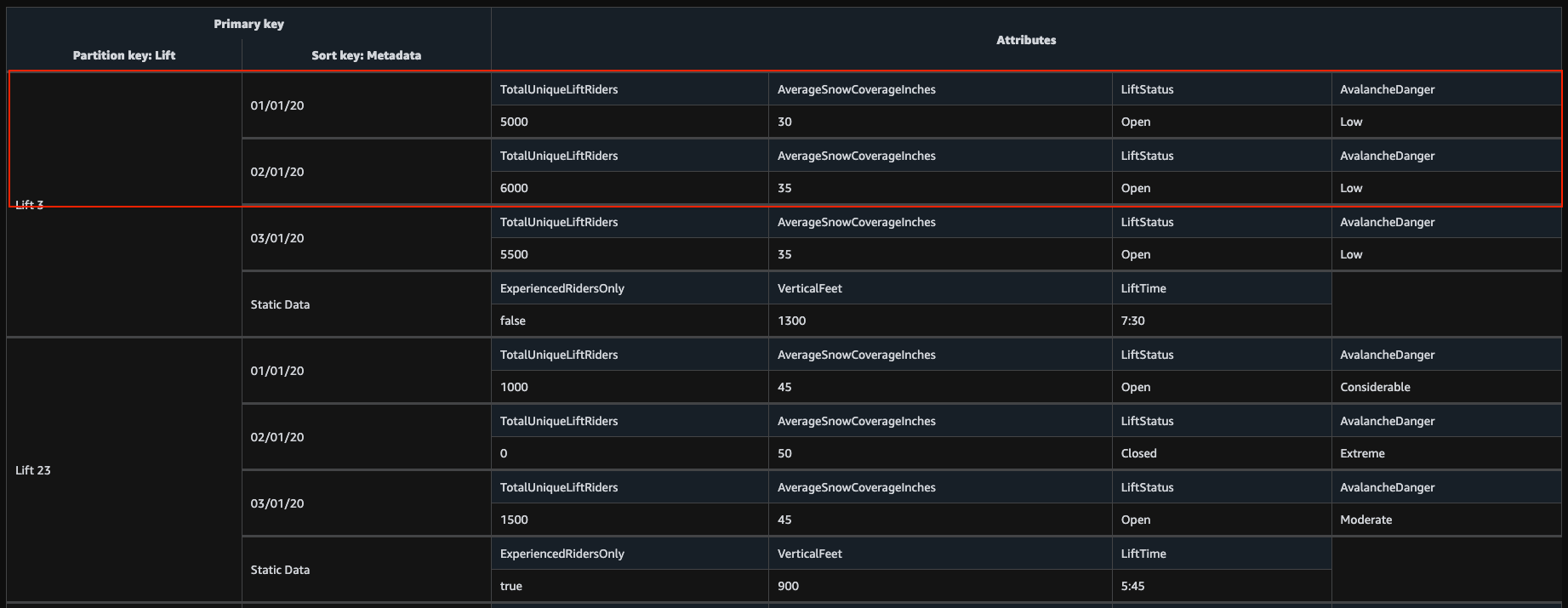
Query 연산은 한번의 연산으로 여러 개의 아이템들을 조회하는 기능이다. 이 연산에서 파티션 키가 필수로 사용된다. 파티션 키는 = 연산 조건만 가능하다. 만약, 파티션 키만 기본 키로 사용하는 아이템의 경우 GetItem 연산과 동일하지만, 복합 키를 기본 키로 사용하는 경우 하나의 파티션 키에 여러 개의 아이템이 매칭된다. 정렬 키는 선택적으로 조회 조건에 활용할 수 있다. 위에서 언급했듯이 정렬 키는 =, >, >=, <, <=, begins with, bewteen 같은 연산 조건들과 함께 사용할 수 있기 때문에 특정 범위에 해당하는 아이템 리스트를 조회하는 것이 가능하다. 다음과 같은 키 조건을 만들어 아이템을 조회할 수 있다.
$ aws dynamodb query \
--table-name SkiLifts \
--key-condition-expression 'Lift = :v1 AND Metadata BETWEEN :v2 AND :v3' \
--expression-attribute-values '{":v1": {"S": "Lift 3"}, ":v2": {"S": "01/01/20"}, ":v3": {"S": "03/01/20"}}'
아래 아이템이 조회된다.
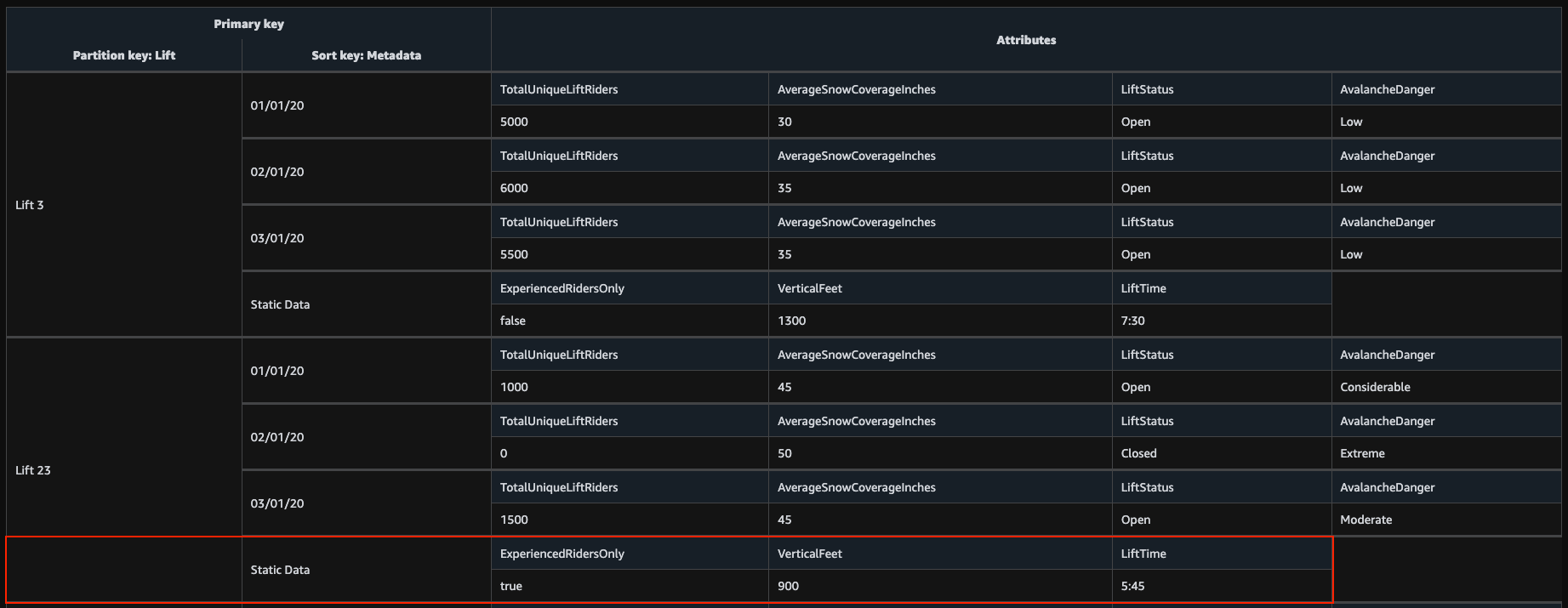
Scan 연산은 데이터를 조회할 때 기본 키에 대한 정보가 없는 경우 사용할 수 있다. 기본적으로 GetItem, Query 연산은 모두 기본 키 정보가 필요하다. Query 연산은 적어도 파티션 키 정보라도 필요하다. 이런 경우 보조 인덱스(secondary index)를 사용하면 쿼리를 사용할 수 있지만, 이번 글에서 다루진 않는다.
Scan 연산은 어떤 연산 조건이든 사용할 수 있기 때문에 유연한 데이터 조회가 가능하지만, 권장하지 않는다. 테이블 전체를 스캔 후 필터링 조건에 따라 적합한 데이터만 남기기 때문에 성능이 떨어지고 비용이 비싸기 때문이다. 테이블에 아이템이 많을수록 Scan 연산의 효율성은 떨어진다. Scan 연산은 다음과 같이 필터 조건을 만들어 아이템들을 조회할 수 있다.
$ aws dynamodb scan \
--table-name SkiLifts \
--filter-expression "VerticalFeet < :v1" \
--expression-attribute-values '{":v1":{"N":"1000"}}'
아래 아이템이 조회된다.
RECOMMEND NEXT POSTS
REFERENCE
- https://www.youtube.com/watch?v=HaEPXoXVf2k
- https://www.youtube.com/watch?v=I7zcRxHbo98
- https://www.usenix.org/conference/atc22/presentation/elhemali
- https://www.usenix.org/system/files/atc22-elhemali.pdf
- https://aws.amazon.com/ko/blogs/database/choosing-the-right-dynamodb-partition-key/
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/HowItWorks.Partitions.html
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/HowItWorks.ReadConsistency.html
- https://docs.aws.amazon.com/ko_kr/amazondynamodb/latest/developerguide/Query.KeyConditionExpressions.html
- https://www.dynamodbguide.com/what-is-dynamo-db/
- https://zuminternet.github.io/DynamoDB/
- https://alphahackerhan.tistory.com/39
- https://stackoverflow.com/a/76237844/14859847
- https://medium.com/rate-labs/%EC%95%84-%ED%95%B4%EB%B4%90-dynamodb-%EB%93%A4%EC%96%B4%EA%B0%84%EB%8B%A4-f8da282bc625
댓글남기기