


대용량 파일 처리를 위한 시스템 디자인
0. 들어가면서
최근 상담 받았던 내용과 내가 제시한 대안책에 대해 정리했다.
1. Problem context
최근 받은 상담은 용량이 큰 파일(1.5GB 이상)을 서버에서 직접 핸들링하면서 발생하는 문제를 어떻게 해결하면 좋을지에 대한 내용이었다. 이 문제의 컨텍스트를 자세히 살펴보자. 이 시스템은 파일 포맷을 변환하는 기능을 제공한다. 내부 코드를 살펴보니 다음과 같이 동작하고 있었다.
- 사용자(브라우저)가 특정 포맷의 파일을 압축 후 서버로 업로드한다.
- 서버는 업로드 된 파일의 압축을 해제하고 임시로 파일 시스템에 저장한다. 네이티브 라이브러리를 사용해서 임시로 저장한 파일을 CAD로 변환한다.
- 파일 시스템에 임시로 저장한 파일들을 삭제한다.
- 변환된 파일을 사용자에게 응답한다.
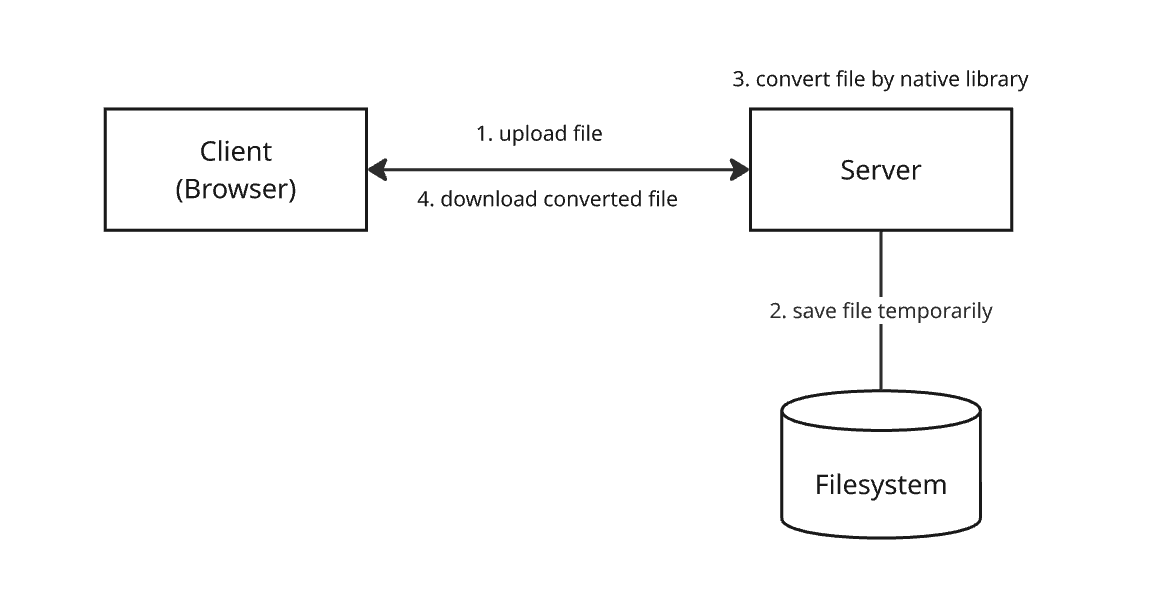
위 상황에서 파일을 업로드 했을 때 다음과 같은 현상들이 발견됐다.
- 용량이 큰 파일을 업로드되면 하나의 요청이 CPU 사용량을 70~80% 까지 상승시키고, 메모리 사용량이 60~70% 까지 점유할 정도로 파일 변환에 필요한 계산 비용이 크다.
- 동시에 여러 파일을 업로드되면 응답을 받는데 약 2분 이상의 시간이 걸리고 게이트웨이 타임아웃 에러(504)가 발생한다.
발견된 현상들을 통해 다음과 같은 문제들을 예상할 수 있다.
- 클라이언트가 보낸 대용량 파일 스트림을 서버가 직접 받아야 한다. 파일 전체를 다 받을 때까지 서버의 프로세스(스레드)는 해당 요청에 묶여있게 된다.
- 파일 데이터를 메모리에 버퍼링하거나 임시 디스크에 쓰는 과정에서 CPU와 메모리 사용량이 급증한다. 다시 말해 서버의 자원이 한 명의 사용자 업로드에 거의 집중된다. 다른 사용자가 로그인, 데이터 조회 등 간단한 요청을 보내도, 서버는 기존 업로드를 처리하느라 즉시 응답하지 못하고 지연이 발생할 수 있다.
- 동시 업로드 사용자가 늘어나면 서버는 쉽게 다운되거나 느려진다. 이를 해결하기 위해 서버 자체를 증설하거나 더 좋은 사양으로 교체해야 하는데, 비용이 많이 들고 비효율적이다.
2. Design system for converting big size files
이 팀이 운영하는 서비스의 활성 사용자 수는 잘 모르겠지만, 이를 어떻게 대응하면 좋을지 질문을 받았다. 스케일-아웃(scale-out)이나 스케일-업(scale-up)을 해야할지, 동시 요청 수에 제한을 두는 것이 좋은지 등과 일반적인 대처 방법이나 제안을 요구했다. 아무래도 이 상황에선 서버 수가 늘어나는 스케일-아웃이나 서버 스펙을 올리는 스케일-업 같은 임시 방편은 근본적으로 문제 해결을 하지 못 한다고 생각했다.
- 구체적인 서비스 이용자 수는 모르지만, 서버 스펙이나 스케일 아웃을 무제한으로 할 수 없다. 사용자 수가 늘어난다면 언젠간 한계에 부딪힌다.
- 파일 변환을 처리하는 서버의 리소스가 과도하게 사용되므로 일반 유저들의 요청을 처리하는 것도 느려진다.
- 문제가 되는 파일 변환 기능을 위해 스케일 아웃이나 스케일 업을 하는 것은 비용적으로 비효율적이다.
스케일-업은 전체 트래픽이 꾸준히 많고, 지속적으로 CPU 사용률이 80% 이상을 넘는다면 효율적일 것이다. 스케일-아웃은 시간대 별로 혹은 특정 이벤트로 인해 급격하게 트래픽이 변동할 때 적합하다. 나는 이 대용량 파일 업로드에 관련된 문제를 해결하기 위해선 다음과 같은 시스템 디자인이 필요하다고 생각했다.
- 클라이언트는 서버로에게 업로드를 위한
사전 서명된 URL(presigned url)을 요청한다. - 클라이언트는 업로드 사전 서명된 URL을 대용량 파일을 S3에 직접 업로드한다.
- 파일 업로드가 완료되면 S3 버킷은 이벤트 브릿지(event bridge) 같은 컴포넌트를 통해 ECS 태스크(task)를 실행시킨다. 파일 업로드가 완료될 때마다 새로운 ECS 태스크 인스턴스가 실행된다.
- ECS 태스크는 S3 버킷에서 타겟 파일을 다운로드 받은 후 변환한다. 변환 프로세스가 완료되면 S3 버킷에 업로드를 수행한다.
- 클라이언트는 S3 버킷으로부터 변환 완료된 파일을 다운로드 받기 위해 지속적으로 폴링(polling)한다. 다운로드 가능한 상태라면 다운로드용 사전 서명된 URL을 통해 변환 완료된 파일을 다운로드 받는다.
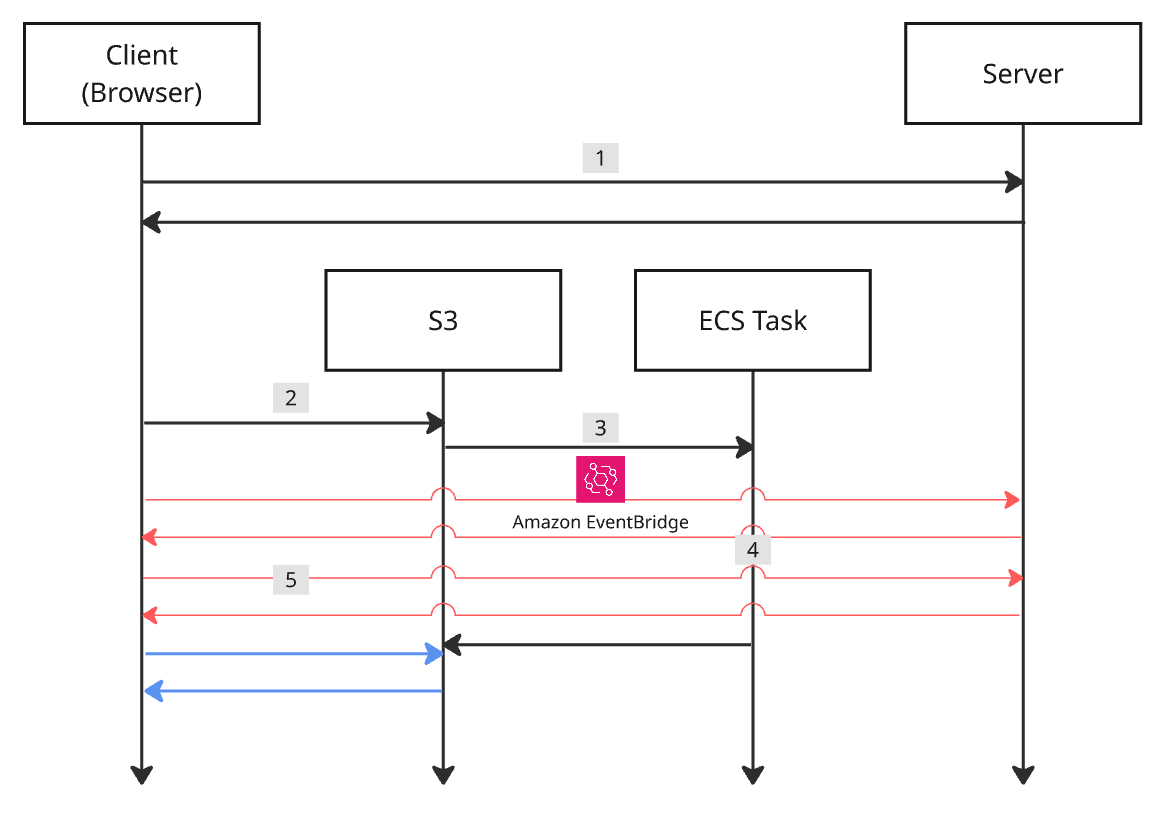
위와 같이 시스템 디자인을 변경하면 구조는 다소 복잡해지지만, 시스템은 더 안정적으로 동작한다.
- 서버의 역할은 사전 서명된 URL을 발급하는 아주 가벼운 작업으로 축소된다. 이 작업은 CPU와 메모리를 거의 사용하지 않으며 빠르게 끝난다.
- 파일을 직접 받는 모든 부담은 AWS S3로 이전된다. S3는 대용량 트래픽 처리를 위해 설계된 서비스이므로 일반적인 서버보다 효율적이고 안정적이다.
- 서버의 CPU와 메모리는 항상 여유 있는 상태를 유지할 수 있으므로 시스템의 응답성과 가용성이 향상되어 모든 사용자의 경험이 좋아진다.
- ECS 태스크가 실패하더라도 재시도 로직(retry)이나 DLQ(dead letter queue)를 통해 안정적으로 작업을 처리할 수 있다. 서버의 상태가 전체 시스템의 장애로 이어지지 않는 느슨한 결합(loosely coupled) 구조가 된다.
- 서버를 항상 높은 스펙으로 유지할 필요가 없고, ECS 태스크도 파일 변환을 위한 적절한 수준의 리소스만 사용하면 된다. 가격이 저렴해진다.
시스템 디자인을 이렇게 변경하면 여러가지 장점들이 있지만, 고려해야 하는 부분도 많다. 어떤 부분들이 있을까?
2.1. Process tracking
우선 파일 변환 프로세스에 대한 상태 관리 및 작업을 추적할 필요가 있다. 작업 상태를 추적하기 위해 데이터베이스를 사용한다.
- 클라이언트가 업로드용 사전 서명된 URL을 요청할 때 서버는
job_id를 생성한다. 클라이언트가 만들어 서버에게 전달해도 무관하다. 추후 클라이언트가 폴링할 때job_id가 필요하다. - 서버는 job_id와 함께 작업 상태를
PENDING으로 데이터베이스에 저장한다. - 클라이언트는 업로드용 사전 서명된 URL을 통해 S3에 파일을 업로드한다.
- 파일 업로드가 완료되면 ECS 태스크가 실행된다. S3 객체의 메타 데이터(혹은 경로)를 통해
job_id를 받는다. 작업 상태를PROCESSING으로 업데이트한다. - ECS 태스크는 변환 작업 완료 시
COMPLETED, 실패 시FAILED등으로 업데이트한다.
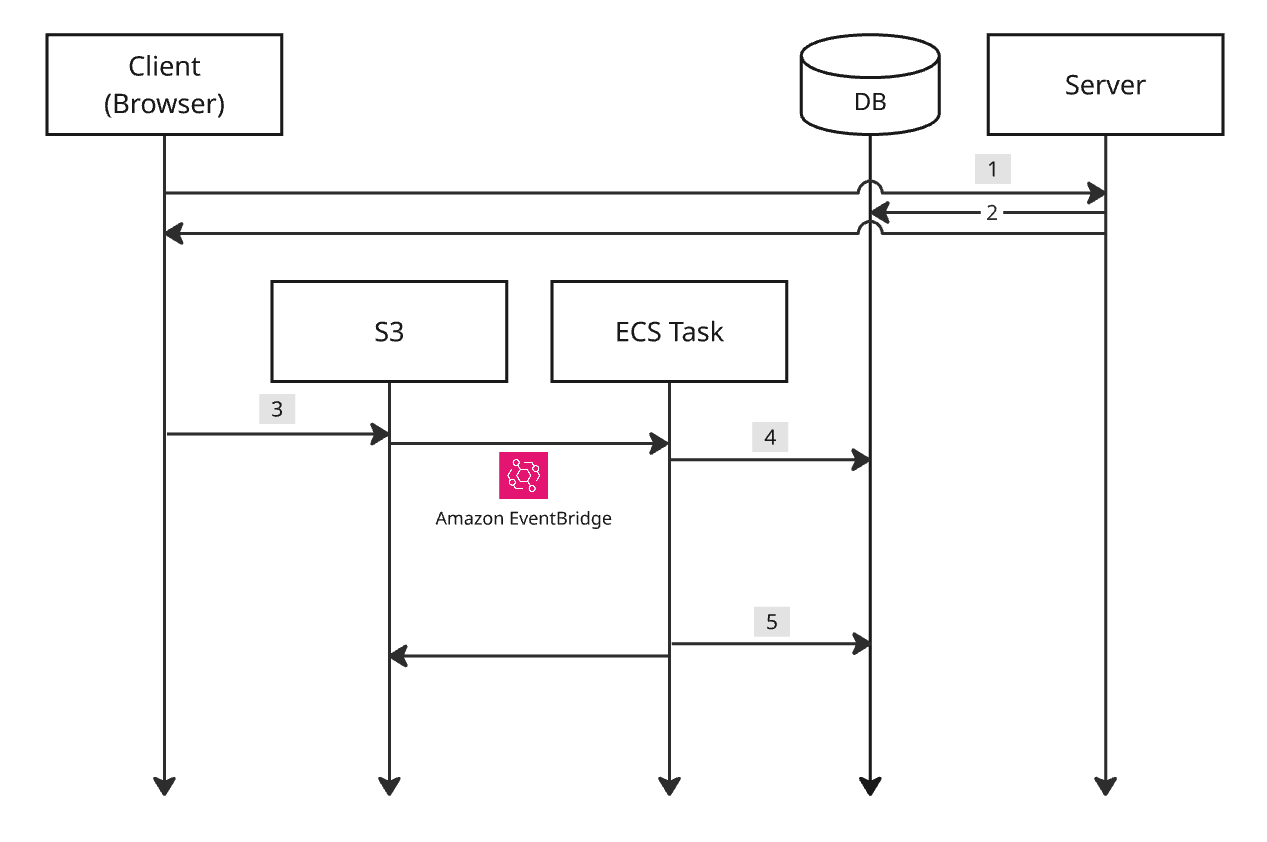
시스템은 동일한 요청에 항상 같은 결과를 보장하는 멱등성(idempotency)이 필요하다. S3 이벤트가 중복으로 발생하여 ECS 태스크가 여러 번 실행되는 케이스에 대한 처리가 필요하다. ECS 태스크는 시작할 때 데이터베이스에 저장된 job_id 상태를 확인한다. 상태가 PENDING이 아니면 작업을 중복 실행하지 않고 바로 종료한다.
2.2. Scheduler to delete files
클라이언트가 변환 완료된 파일을 다운로드하면 불필요해진 파일들은 삭제해야 한다. 주기적으로 삭제해도 문제가 없지만, 이 팀의 경우 업로드하는 파일이 매우 중요한 기밀이기 때문에 S3 스토리지에 파일이 올라가는 것을 큰 보안 리스크로 간주했다. 파일을 최대한 빨리 삭제하기 위한 정책이나 프로세스가 필요했다. S3는 생명 주기(lifecycle) 정책을 사용하면 일정 기간이 지난 파일을 삭제할 수 있지만, 일(day) 단위부터 가능하다. 별도 삭제 스케줄러가 구현이 필요했다.
job_id를 사용하면 스케줄러가 빠른 주기로 작업 상태를 확인 후 파일을 삭제하는 것이 가능하다. 데이터베이스를 검색해서 COMPLETED이나 FAILED 상태의 파일들을 삭제한다. PENDING이나 PROCESSING 상태가 너무 오래 유지된 경우에도 삭제한다. 다만, 이 경우에는 DLQ나 로깅을 통해 진행이 제대로 되지 않은 이유를 추적한다.
사전 서명된 URL을 만들 때 S3 오브젝트 경로에 job_id를 포함시킨다. 예를 들면, 원본 파일은 {job_id}/uploads 경로, 처리된 파일은 {job_id}/processed 경로로 설계한다. job_id는 항상 다른 값을 갖도록 UUID 같은 데이터를 사용한다. 원본 파일, 변환된 파일을 변환 프로세스 별로 한 경로에 모은다. 스케줄러를 통해 {job_id}/* 경로 하위 파일들을 삭제한다.
2.3. Client polling
위 구조에서 가장 큰 약점은 클라이언트가 계속 폴링하는 것이다. 불필요한 트래픽을 유발하고, 클라이언트 코드도 폴링 처리를 위한 로직으로 복잡해진다. 장시간 파일 업로드와 변환 프로세스를 기다려야 하므로 사용성이 좋지 않다. 웹소켓이나 서버 전송 이벤트(SSE, sever-sent event)를 통해 비동기적으로 처리하는 편이 효율적이고 사용성이 좋을 것이다.
다만, 기존에 작성된 프론트엔드 코드를 봤을 때 즉시 비동기 처리로 넘어가기에 어려움이 있어 보였다. 이 부분은 일단 폴링으로 처리하되 파일 변환 프로세스의 큰 흐름이 잡히면 이후에 비동기적인 사용자 플로우를 PM, 디자이너와 함께 재정의 할 필요가 있었다.
클라이언트는 폴링을 수행할 때 job_id를 사용한다. 효율적인 폴링을 위해 파일 변환에 걸리는 시간을 고려한 인터벌(interval) 시간이나 최대 폴링 시도 횟수를 지정한다. 클라이언트가 S3 스토리지를 직접 폴링하는 것은 보안적으로 좋지 않고, 모니터링이 어렵다. 서버 폴링을 거쳐 파일 다운로드를 수행하는 설계가 필요하다.
- 서버에 파일 변환 프로세스의 작업 상태를 반환하는
[GET] /api/jobs/{job_id}/status같은 API 엔드포인트를 만든다. 이를 통해 클라이언트는 단순히 파일 유무가 아닌 진행 중인지 실패(사유 포함)인지 등의 구체적인 이유를 알 수 있다. 클라이언트는 작업 상태에 따라 폴링을 중간에 멈출 수 있다. - 서버로부터 작업 상태를 확인 후 다운로드용 사전 서명된 URL을 받으면 URL의 만료 시간을 최소한으로 지정할 수 있으므로 보안적으로 안전하다. 클라이언트가 직접 S3 스토리지를 폴링하기 위해선 언제 끝날지 모르는 변환 작업을 위해 긴 유효 시간을 갖는 사전 서명된 URL이 필요하다. 긴 유효 시간을 갖는 사전 서명된 URL은 노출되면 통제할 수 없으므로 보안적으로 매우 취약하다.
- 클라이언트가 서버의 엔드포인트를 지속적으로 폴링을 하고 있는지, 어떤 응답을 받고 있는지, 언제 포기했는지 등의 로그를 남긴다.
2.4. Run ECS task
파일 변환은 *.so(shared object) 같은 네이티브 라이브러리가 필요했다. 이 네이티브 라이브러리를 래핑(wrapping)한 서드-파티 jar 라이브러리를 사용 중이므로 JVM 애플리케이션을 도커 컨테이너로 실행해야 했다. 도커 컨테이너를 실행하고 메모리나 시간 제약에도 여유가 필요하므로 람다보다 ECS 태스크가 유리하다. 파일 업로드 이벤트에 컨테이너가 빠르게 실행될 수 있도록 그랄VM(graalVM) 도입을 고려해볼만 하다.
CLOSING
이 팀은 큰 파일을 처리하는 아키텍처에 대한 고민뿐만 아니라 원인을 알 수 없는 서버 에러가 발생하고 있었는데, 이 부분은 시스템 버그였다. 시스템 버그를 찾아준 것만으로 일단 급한 불은 껐는지 새로 제안한 아키텍처에 대한 구현은 추후로 미뤄진 것 같다. 대안책을 전달한 미팅 이후에 별다른 연락은 없었다. 가능하다면 이 시스템 디자인을 함께 개발하고 싶었는데 아쉽다. S3의 ECS 태스크 이벤트 트리거 같은 AWS 리소스 사이의 연결 부분이 궁금해서 구축해 본 내용은 다음 글을 통해 정리할 생각이다.
댓글남기기