


LLM 랭체인(LangChain) 예제
1. LangChain
공식 홈페이지를 보면 다음과 같은 설명을 볼 수 있다.
LangChain is a framework for developing applications powered by large language models (LLMs).
랭체인(langchain)은 LLM(Large Language Model)을 사용하는 애플리케이션을 개발할 때 사용하는 프레임워크다. LLM과 연관된 기술들(e.g. 임베딩 모델, 벡터 저장소)을 위한 표준 인터페이스를 제공한다. 랭체인이 제공하는 표준화 된 인터페이스를 제공하기 때문에 개발자는 동일한 코드로 OpenAI, Cohere, HuggingFace, Ollama 같은 여러 LLM들을 사용할 수 있다.
랭체인이라는 이름처럼 LLM 애플리케이션을 구성할 때 필요한 기능들(혹은 컴포넌트, 객체)을 연결하는 체이닝(chaining)하는 것이 가능하다. 체이닝 예제는 아래에서 살펴보자. 랭체인 아키텍처를 보면 랭체인과 함께 협업하는 컴포넌트들이 하나의 에코 시스템(eco system)을 구성한다.
- LangChain
- LLM 앱을 구성하는 기본 프레임워크다. 프롬프트, 모델, 출력 파싱, 메모리, 툴, 검색 등 다양한 요소를 연결해 복잡한 LLM 파이프라인을 구성할 수 있게 해준다.
- LangGraph
- LangChain 기반 컴포넌트를 노드처럼 연결해서 복잡한 흐름 제어가 가능한 상태 머신(state machine)/워크플로우(workflow) 엔진이다.
- 분기, 루프, 상태 전이 등을 처리한다.
- 각 노드는 LangChain Runnable 또는 체인을 의미한다.
- LangSmith
- LangChain 앱의 실행 흐름을 추적하고, 디버깅하고, 평가하는 플랫폼이다.
- LangChain, LangGraph를 사용한 앱의 입출력, 중간 과정, LLM 호출 내용을 시각화해서 보여준다.
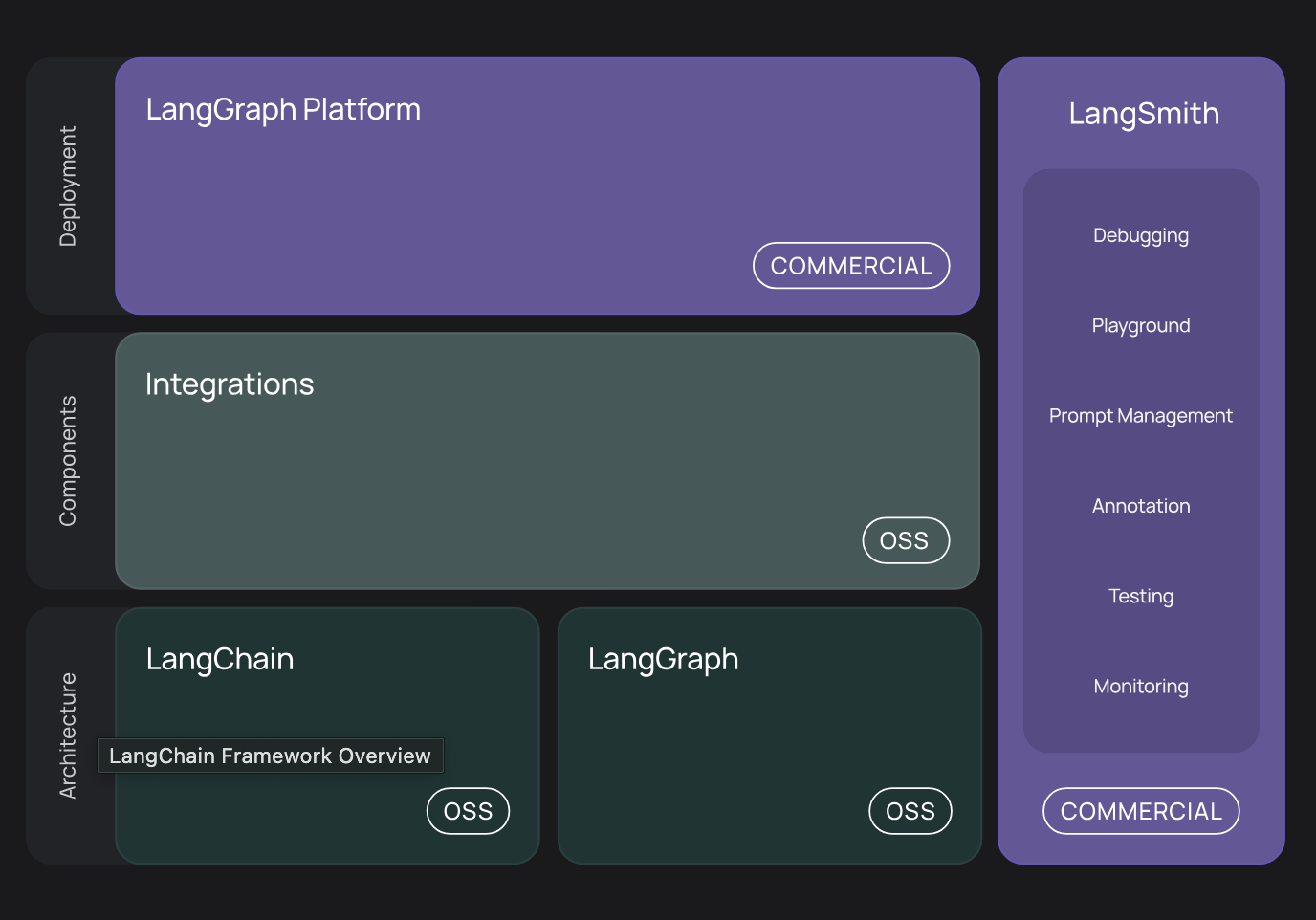
랭체인 프레임워크는 다음과 같은 패키지들을 제공한다.
- langchain-core
- 기본적인 추상화 된 채팅 모델과 기타 컴포넌트를 제공한다.
- Integration packages
- langchain-openai, langchain-anthropic 등 주요 모델들과 연결할 수 있는 패키지다.
- langchain
- 체인, 에이전트, 검색 전략 등 애플리케이션의 인지 아키텍처를 만드는 기능들을 제공한다.
- langchain-community
- LLM 커뮤니티에서 유지보수하는 서드-파티(3rd-party) 라이브러리들과 결합하는 기능을 제공한다.
- langgraph
- 오케스트레이션(orchestration) 프레임워크로 랭체인 컴포넌트들을 연결한다.
2. Example
지금부터 간단한 랭체인 애플리케이션을 만들어보자. 먼저 파이썬 가상 환경을 구축한다.
$ python3 -m venv .venv
파이썬 가상 환경을 활성화한다.
$ source .venv/bin/activate
필요한 패키지를 설치한다.
$ pip install langchain_core langchain_ollama
Collecting langchain_core
Using cached langchain_core-0.3.69-py3-none-any.whl.metadata (5.8 kB)
...
Successfully installed PyYAML-6.0.2 annotated-types-0.7.0 anyio-4.9.0 certifi-2025.7.14 charset_normalizer-3.4.2 h11-0.16.0 httpcore-1.0.9 httpx-0.28.1 idna-3.10 jsonpatch-1.33 jsonpointer-3.0.0 langchain_core-0.3.69 langchain_ollama-0.3.5 langsmith-0.4.6 ollama-0.5.1 orjson-3.11.0 packaging-25.0 pydantic-2.11.7 pydantic-core-2.33.2 requests-2.32.4 requests-toolbelt-1.0.0 sniffio-1.3.1 tenacity-9.1.2 typing-extensions-4.14.1 typing-inspection-0.4.1 urllib3-2.5.0 zstandard-0.23.0
로컬 환경에 라마(llama) 모델을 실행 후 연결할 것이다. ollama 컨테이너를 실행한다.
$ docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
필요한 LLM을 실행한다. 이 예제에선 llama3.2 버전을 사용한다.
$ docker exec -it ollama ollama run llama3.2
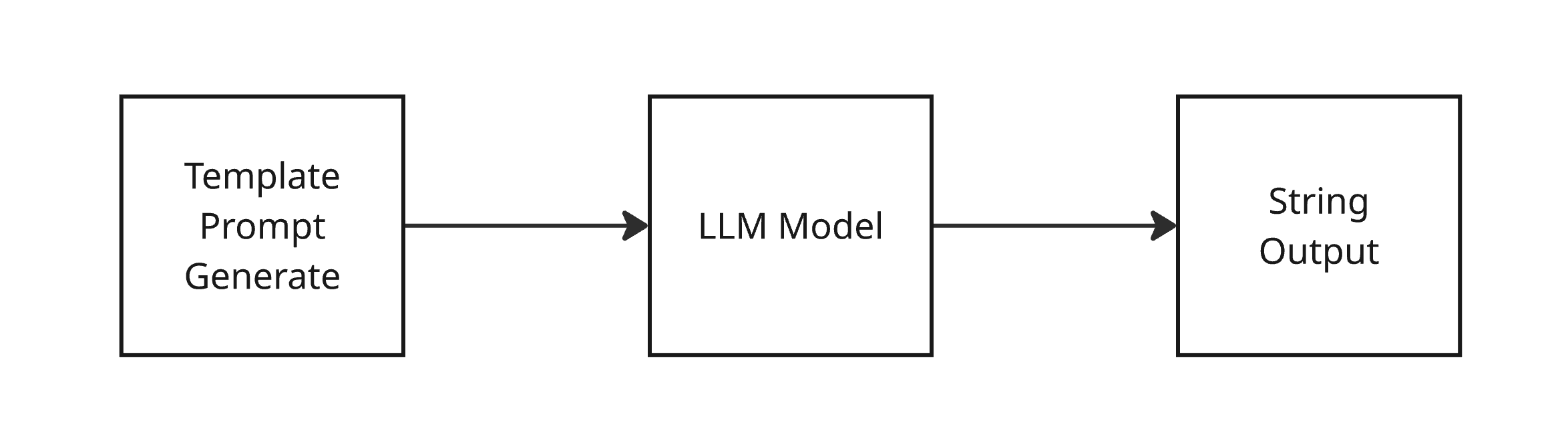
이제 필요한 준비는 모두 끝났다. 코드를 살펴보기 전에 어떤 체인을 구성할 것인지 그림을 살펴보자.
- 템플릿화 된 프롬프트를 만든다.
- LLM에게 해당 프롬프트를 전달한다.
- LLM 호출 결과를 문자열 파서(parser)에게 전달한다.
다음과 같은 컴포넌트를 임포트(import)한다.
- StrOutputParser 클래스
- 문자열을 정리하고 불필요한 개행, 공백 등을 제거한다.
- ChatPromptTemplate 클래스
- 챗 모델용 프롬프트 템플릿을 만든다.
- ChatOllama 클래스
- Ollama 기반 Chat 모델을 위한 래퍼(wrapper)다. llama3, mistral, codellama 같은 모델을 로컬에서 사용하기 위해 사용한다.
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableSequence
from langchain_ollama import ChatOllama
프롬프트, LLM, 파서를 생성한다.
prompt = ChatPromptTemplate.from_template("Explain about {topic}.")
llm = ChatOllama(model = "llama3.2")
parser = StrOutputParser()
우선은 체이닝 없이 각 결과들을 직접 연결해보자. 아래 코드처럼 각 객체들의 실행 결과를 개발자가 직접 코드로 연결해줄 수 있다.
messages = prompt.invoke({
"topic": "deep learning"
})
result = llm.invoke(messages)
output = parser.stream(result)
print(output)
위 코드가 실행되면 라마 모델이 deep learning에 설명을 해준다.
Deep Learning is a subset of Machine Learning that uses artificial neural networks to analyze and interpret data. It's called "deep" because the neural network consists of multiple layers, each with a larger number of nodes (neurons) than the previous layer.
**Key Characteristics:**
1. **Multi-Layered Networks**: Deep learning models are composed of multiple layers, typically 2-10 or more. Each layer processes input data in a different way, allowing the model to learn complex representations.
2. **Artificial Neural Networks**: The core component of deep learning is inspired by the human brain's neural networks. Artificial neurons process inputs, apply non-linear transformations, and pass outputs to other neurons.
3. **Backpropagation**: Deep learning models use backpropagation (BP) to optimize the weights and biases in each layer during training. This process involves computing gradients and adjusting the parameters to minimize the error between predicted outputs and actual labels.
4. **Large Amounts of Data**: Deep learning typically requires large amounts of high-quality data for effective training.
**Types of Deep Learning:**
1. **Convolutional Neural Networks (CNNs)**: Designed for image processing tasks, CNNs use convolutional and pooling layers to extract features from images.
2. **Recurrent Neural Networks (RNNs)**: Suitable for sequential data such as text, speech, or time series, RNNs use feedback connections to capture temporal relationships.
3. **Long Short-Term Memory (LSTM) Networks**: A type of RNN that can learn long-term dependencies in sequential data.
**Applications of Deep Learning:**
1. **Computer Vision**: Image classification, object detection, segmentation, and generation
2. **Natural Language Processing (NLP)**: Text classification, sentiment analysis, machine translation, and question answering
3. **Speech Recognition**: Speech-to-text systems and voice assistants
4. **Robotics and Control Systems**: Perception, decision-making, and control of robots
5. **Healthcare**: Medical image analysis, disease diagnosis, and personalized medicine
**Benefits:**
1. **Improved Accuracy**: Deep learning models can achieve state-of-the-art performance on various tasks.
2. **Increased Efficiency**: Automated feature extraction, removal of unnecessary computations, and parallelization can lead to significant speedups.
3. **Scalability**: Deep learning models can be fine-tuned for specific tasks with relatively small amounts of data.
**Challenges:**
1. **Interpretability**: Complex neural networks are difficult to interpret, making it challenging to understand the reasoning behind their predictions or decisions.
2. **Overfitting**: Models may become too specialized to the training data and fail to generalize well to new situations.
3. **Computational Resources**: Training large deep learning models requires significant computational resources, including memory and processing power.
**Future Developments:**
1. **Explainability Techniques**: Developing techniques to explain the reasoning behind deep learning predictions or decisions will be crucial for increasing trust and understanding in AI systems.
2. **Efficient Architectures**: Designing more efficient neural network architectures that can learn with smaller amounts of data while maintaining performance is an active area of research.
3. **Transfer Learning**: Improving transfer learning methods to leverage pre-trained models on one task to improve performance on related tasks will be essential for real-world applications.
In conclusion, deep learning has revolutionized the field of artificial intelligence by enabling computers to learn from complex patterns in data and make accurate predictions or decisions. While there are challenges associated with deep learning, ongoing research is addressing these issues, leading to further improvements and advancements in this exciting field.
이제 위 코드를 체이닝을 통해 더 쉽게 만들어보자. 위에서 만든 prompt, llm, parser 객체는 모두 Runnable 클랙스의 인스턴스(istance)다.
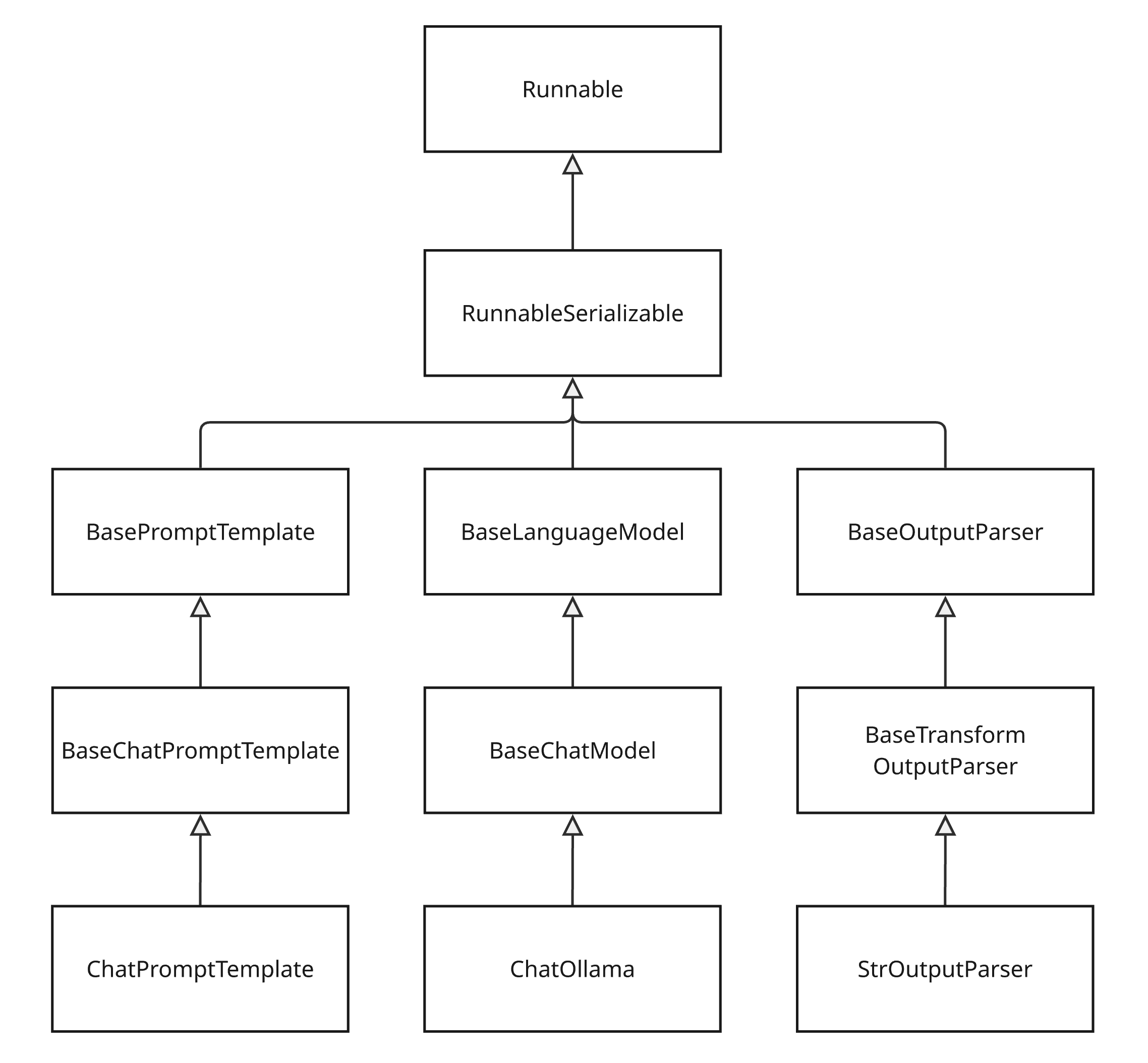
RunnableSequence 클래스를 사용하면 Runnable 인스턴스들을 체이닝 할 수 있다.
- RunnableSequence 클래스
- 여러 개의 Runnable을 순서대로 연결하는 객체다.
- 예제에선 프롬프트, 모델, 파서 등을 한 줄로 실행할 수 있도록 만든다.
from langchain_core.runnables import RunnableSequence
RunnableSequence 클래스를 사용해 아래와 같이 체인을 구성한다. 결과를 스트림(stream) 방식으로 출력하여 사용자에게 빠른 응답을 준다.
chain = RunnableSequence(
first = prompt,
middle = [llm],
last = parser
)
answer = chain.stream({
"topic": "deep learning"
})
for chunk in answer:
print(chunk, end = "", flush = True)
|(파이프, pipe)를 사용해서 Runnable 객체들을 연결하면 RunnableSequence 클래스 없이도 코드를 더 직관적으로 작성할 수 있다.
chain = prompt | llm | parser
answer = chain.stream({
"topic": "deep learning"
})
for chunk in answer:
print(chunk, end = "", flush = True)
댓글남기기