


인공지능(AI)과 온톨로지(ontology)
0. 들어가면서
최근 지인과 온톨로지(ontology)에 대한 이야기를 잠깐 나눌 기회가 있었다. 나도 AI 관련 기술에 점점 관심이 커지는 중인데, 공부할 좋은 주제 거리를 하나 찾은 느낌이다. 기술적인 내용을 다루기 전에 온톨로지가 어떤 개념인지 간단히 블로그에 정리해봤다.
1. What is ontology?
온톨로지라는 개념은 철학의 한 분야에서 시작했다고 한다. ‘존재하는 것(onto)’과 ‘학문(logia)’의 합성어다. 이 온톨로지라는 개념은 AI 필드에선 또 다른 의미를 갖는다. 특정 분야(도메인)의 지식을 컴퓨터가 이해하고 처리할 수 있도록 지식을 구조화 해놓은 것이다. 쉽게 표현하면 “AI가 이해하고 의사결정에 활용할 수 있는 데이터 모델(혹은 자료 구조)”라고 말할 수 있다.
AI 필드에서 온톨로지는 개념화(conceptualization)에 대한 형식적(formal)이고 명시적인 명세(explicit specification)라고 한다. 설명이 추상적이라 이해하기 어려웠다. 이 부분을 구체적으로 정리하면 온톨로지의 개념을 이해하는 데 도움이 된다.
개념화란 복잡한 현실 세계를 컴퓨터가 이해할 수 있도록 핵심만 뽑아내어 단순한 모델로 만드는 과정이다. 현실 세계는 AI가 이해하기에 너무 복잡하고 방대하다. 우리가 AI를 사용하려는 목적에 맞춰 필요한 특징만 골라내어 정리하는 것이다. 다음 3가지 관점에서 개념화를 고려해야 한다.
- 추상화(abstraction)
- 관점의 결정(domain view point)
- 약속과 합의(shared understanding)
추상화란 현실의 사물에서 불필요한 세부 사항을 버리고 본질적인 특징만 뽑아내는 것이다. 예를 들어, 다음과 같은 준현이라는 사람이 있다.
- 키는 172cm다.
- 몸무게는 75kg다.
- 직업은 개발자다.
- 라면을 좋아해서 지난 밤에 야식으로 라면을 먹었다.
- 현재 경기도에서 거주하고 있다.
도메인에 따라 준현이라는 사람을 다르게 추상화한다. 같은 대상이라도 분야에 따라 관심 갖는 정보가 다르다. AI에게 준현에 대해 설명해 달라고 했을 때, AI가 어떤 도메인을 위해 일하는지에 따라 이를 다르게 정의하고 설명할 수 있어야 한다.
| 도메인 | 추상화 | 필요한 정보 | 불필요한 정보 |
|---|---|---|---|
| 병원 | 환자 | 이름, 주민번호, 병명, 혈액형, 신체 사이즈 | 지난 밤에 라면을 먹은 것 |
| 쇼핑몰 | 고객 | 이름, 주소, 구매 내역, 포인트 | 키나 몸무게 |
약속과 합의는 “우리끼리는 이것을 이렇게 부르기로 하자”는 약속이다. 철수는 “스마트폰”이라고 부르고, 영희는 “휴대폰”이라고 부르고, 민수는 “모바일 기기”라고 부르면 AI는 이 셋을 다 다른 것으로 인식해 버린다. 따라서 이 모든 것을 “MobileDevice”라고 정립하는 과정이 개념화다.
형식적(formal)이고 명시적인 명세(explicit specification)라는 것은 어떤 의미일까? 형식적이란 것은 단순히 단어를 나열하는 것이 아니라 형식 논리나 수학적/논리적 규칙에 따라 설계된다는 것을 의미한다. 이를 통해 지식의 정밀성(precision), 일관성(consistency)을 보장하고, 컴퓨터가 처리할 수 있는 구조적(structured) 쳬계를 갖춘다. 명시적인 명세는 이해 관계자 간의 공유된 이해를 가능하도록 숨겨진 의미 없이 개념과 관계를 RDF(Resource Description Framework), OWL(Web Ontology Language) 같은 형식 언어로 문서화하는 것을 말한다.
예를 들어, 스마트홈 AI에게 명령을 내리는 상황이다. 창문이 고장난 상태에서 “지금 너무 더워. 거실 창문을 닫고 에어컨을 켜줘.”라고 명령을 내리면 스마트홈 AI는 에어컨을 킨다. 하지만, 사람이라면 “창문이 열려 있는데 에어컨을 켜면 비효율적이잖아?”라는 답변을 할 것이다. 사람은 ‘에어컨 효율’을 위해서는 ‘밀폐된 공간’이 필요하다는 물리적 상식을 가지고 있다. 창문이 안 닫히면 에어컨을 켜는 게 무의미하다고 판단한다.
AI를 위해서 다음과 같은 명시적인 컨텍스트(규칙 정의)가 필요하다.
- Rule A (작동 전제 조건) - AirConditioner:TurnOn requires Room:Sealed
- Rule B (상태 정의) - Room:Sealed only if Window:Status == Closed
- Rule C (행동 제약) - Action Window:Close requires Window:Health == Functional
위와 같은 제약 조건을 주면 AI는 다음과 같은 추론을 한다.
- 에어컨을 켜기 위해 방이 폐쇄되어 있어야 한다.
- 방이 폐쇄하기 위해서 창문을 닫아야만 한다.
- 창문을 닫기 위해서 창문이 정상적인 상태여야 한다.
- 창문이 고장나서 창문을 닫을 수 없다.
- 방을 폐쇄할 수 없다.
- 에어컨을 못 킨다.
2. Key components of an ontology
온톨로지 구성하는 요소들은 어떤 것들이 있을까? 참고 자료마다 조금씩 달랐다. 나는 위키피디아의 Ontology components을 참조했다.
- 개체(individuals/instance)
- 가장 기초적인 바닥 단계(Ground level)의 객체다.
- 구체적인 사물(사람, 테이블)뿐만 아니라 추상적인 것(숫자, 단어)도 포함될 수 있다.
- 클래스(class)
- 개체들의 집합, 개념, 또는 유형(Type)이다.
- 개체가 충족해야 하는 조건(속성)을 정의한다.
- 속성(attributes)
- 개체나 클래스가 가지는 특징, 특성, 매개변수다.
- 이름, 부품(part), 숫자 데이터 등이 포함된다.
- 관계(relations)
- 개체와 개체, 혹은 클래스와 클래스가 서로 어떻게 연결되는지 규정한다.
- 상하 관계(subsumption): is-a-subclass-of (분류 체계 형성)
- 부분 관계(mereology): part-of (복합 객체 형성)
- 도메인 특화 관계: made-in 같은 특정 분야의 사실 관계
위의 기본 구성 요소에 논리(logic) 및 제약 구성 요소(constraints)에 관련된 구성 요소들이 있다.
- 함수 용어(function terms)
- 문장에서 개체 대신 사용할 수 있는 복잡한 구조다.
- 제약 조건(restrictions)
- 어떤 주장이 참이 되기 위해 반드시 만족해야 하는 조건이다.(입력 값 검증 등)
- 규칙(rules)
- “만약 A라면 B이다(If-Then)” 형태의 문장으로, 논리적 추론을 가능하게 한다.
- 공리(axioms)
- 도메인 이론 전체를 구성하는 논리적 주장(assertions)이다.
- 여기에는 기본적인 참인 명제뿐만 아니라 그로부터 유도된 이론들도 포함된다.
개념을 살펴봤지만, 여전히 이해하는 것이 어려울 수 있다. 현실 세계의 넷플릭스(netflix)라는 도메인을 예시로 온톨로지의 구성 요소들을 정리해보자. 가장 먼저 클래스를 정의한다. 예를 들어, 넷플릭스의 모든 영상물을 Content라는 클래스로 개념화한다.
- Content 클래스
- 모든 콘텐츠는 hasTitle 라는 속성을 갖고, 그 속성의 값은 반드시 String(문자열)이어야 한다.
- 모든 콘텐츠는 releaseYear 라는 속성을 갖고, 그 속성의 값은 반드시 Number(숫자)여야 한다.
다음은 계층이나 분류 쳬계를 만든다. is-a-subclass-of 관계를 사용해 계층을 만든다. Movie, Series는 Content의 일부다. 다음과 같이 표현할 수 있다.
- Movie is-a-subclass-of Content
- Series is-a-subclass-of Content
Content 클래스는 단순한 개념이기 때문에 실제 세계에선 실제로 존재하는 데이터가 아니다. 오징어 게임이라는 인스턴스를 만들어보자.
- Squid_Game_Season1 인스턴스(Type: Content)
- hasTitle - "오징어 게임"
- releaseYear - 2021
이번엔 객체 간의 상호 작용을 정의해보자. 이를 관계라고 한다.
- SquidGame directed-by HwangDongHyuk
- Squid_Game_Season1 is-part-of SquidGame
- User_Jun watches Squid_Game_Season1
- User_Jun subscribed-to PremiumPlan
시스템이 오류를 범하지 않도록 논리적인 규칙들도 정한다. “어떤 개체도 Movie이면서 동시에 Series일 수 없다”는 공리나 “Movie는 감독이 최소 1명 이상인 것들의 집합에 포함되어야 한다.” 같은 제약 조건은 다음과 같이 표현할 수 있다.
- Movie isDisjointWith Series
- Movie onProperty: directedBy -> min: 1
- Movie onProperty: releaseYear -> minInclusive: 1888
3. Express ontology with programming languages
위에서 온톨로지의 개념을 다룰 때 언급했던 RDF(Resource Description Framework)와 OWL(Web Ontology Language)이 어떤 것인지 가볍게 살펴보자. RDF는 데이터를 “주어-술어-목적어(Triple) 형태로 표현하자”는 추상적인 데이터 모델(개념)이다. 초창기에는 RDF/XML이라는 XML 포맷을 표준으로 사용했기에 보통 .rdf 파일은 하면 XML 형식으로 작성되어 있다. 예를 들어, “남자는 사람의 일종이다.”이라는 문장을 RDF/XML 형식으로 표현하면 다음과 같다.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdfs="http://www.w3.org/2000/01/rdf-schema#"
xmlns:ex="http://example.org/ontology#">
<rdfs:Class rdf:about="http://example.org/ontology#Human"/>
<rdfs:Class rdf:about="http://example.org/ontology#Man">
<rdfs:subClassOf rdf:resource="http://example.org/ontology#Human"/>
</rdfs:Class>
</rdf:RDF>
이는 기계는 이해하기 쉬울지 모르지만, 불필요한 태그가 많아 사람이 이해하기 어렵다. 이런 문제를 해결하기 위해 Turtle(.ttl)이나 JSON-LD(.jsonld) 같은 포맷을 사용하기도 한다. Turtle 형식으로 같은 문장을 표현하면 다음과 같다.
:Man rdfs:subClassOf :Person .
JSON-LD 형식으로 표현하면 다음과 같다.
{
"@id": "Man",
"rdfs:subClassOf": { "@id": "Person" }
}
W3C 웹 온톨로지 언어(OWL)에 따르면 OWL은 사물, 사물들의 집합(그룹), 그리고 사물 간의 관계에 대한 풍부하고 복잡한 지식을 표현하기 위해 설계된 시맨틱 웹(semantic web) 언어다. OWL은 계산 논리(computational logic) 기반의 언어다. OWL로 컴퓨터 프로그램이 활용할 수 있는 표현된 지식, 제약 사항, 규칙 등을 표현할 수 있다.
RDF만으로 논리적 제약을 만들 수 없기 때문에 OWL을 사용해야 한다. 예를 들어, “철수(Chulsoo)는 남자이자 여자다.”라는 문장을 RDF/Turtle 형식으로 표현하면 다음과 같다.
# 정의 (Schema)
:Man a rdfs:Class .
:Woman a rdfs:Class .
# 데이터 (Data)
:Chulsoo a :Man .
:Chulsoo a :Woman .
RDF에는 disjointWith 같은 문법이 없기 때문에 남자, 여자가 함께 공존할 수 없는 상태임을 정의할 수 없다. OWL 언어를 사용하면 다음과 같은 제약 사항을 포함시킬 수 있다.
# 정의 (Schema)
:Man a owl:Class .
:Woman a owl:Class .
# 핵심: OWL의 제약 조건
:Man owl:disjointWith :Woman .
# 데이터 (Data)
:Chulsoo a :Man .
:Chulsoo a :Woman .
남자, 여자라는 상태가 동시에 존재할 수 없음을 명시했기 때문에 AI는 스스로 데이터가 논리적으로 맞는지 검증하고 판단할 수 있다. 위에서 넷플릭스 도메인을 예시로 정의한 온톨로지를 PDF, OWL 언어로 작성된 Turtle 형식 문서로 만들어보면 아래와 같이 표현된다.
@prefix : <http://www.example.org/netflix#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
<http://www.example.org/netflix> rdf:type owl:Ontology .
# --- Classes ---
:Content rdf:type owl:Class .
:Movie rdf:type owl:Class ; rdfs:subClassOf :Content .
:Series rdf:type owl:Class ; rdfs:subClassOf :Content .
:Person rdf:type owl:Class .
# --- Properties ---
:directedBy rdf:type owl:ObjectProperty ;
rdfs:domain :Content ;
rdfs:range :Person .
:hasTitle rdf:type owl:DatatypeProperty ;
rdfs:domain :Content ;
rdfs:range xsd:string .
# --- Instances ---
:HwangDongHyuk rdf:type :Person ;
:hasTitle "황동혁" .
:SquidGame rdf:type :Series ;
:hasTitle "오징어 게임" ;
:directedBy :HwangDongHyuk .
:IronMan rdf:type :Movie ;
:hasTitle "아이언맨" .
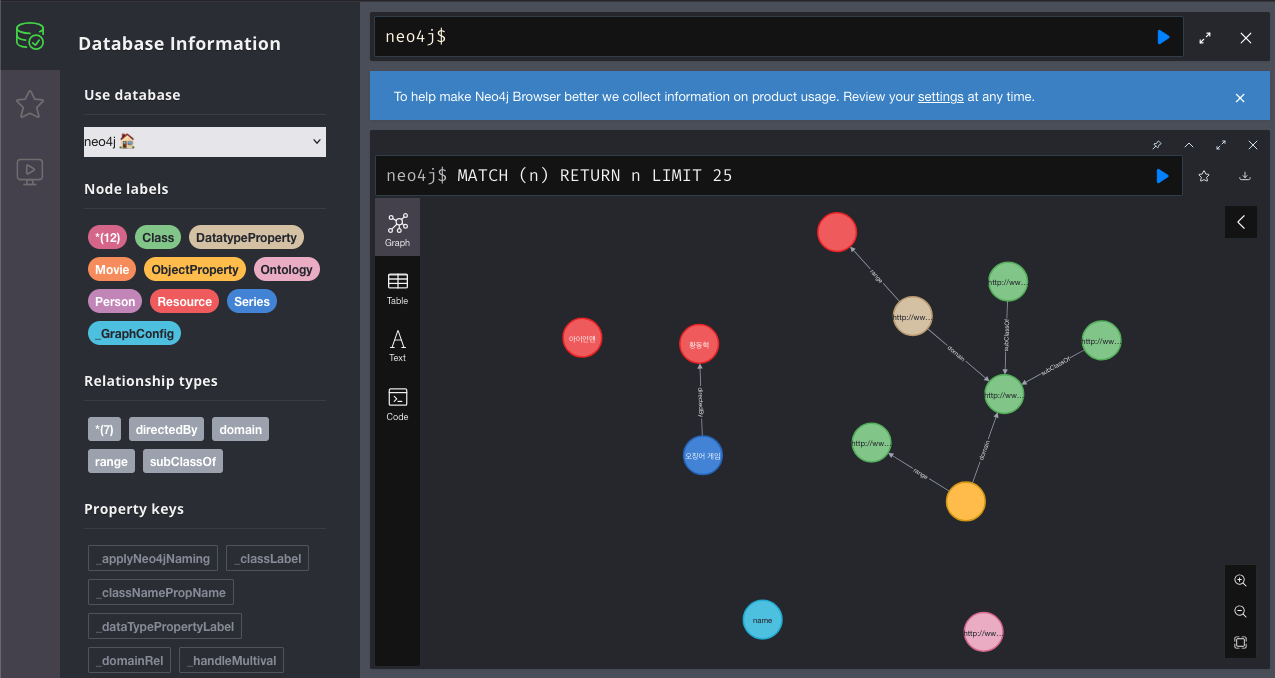
위 Turtle 파일을 neo4j 그래프 데이터베이스에 임포트(import)하면 다음과 같은 그래프가 그려진다.
CLOSING
공부하기 전에는 온톨로지라는 것이 팔란티어(palantir) 같은 특정 기업의 솔루션이라고 오해하고 있었다. 컨셉을 이해하고 보니 회사 비즈니스에 좋은 내러티브를 만들어 낼 수 있을 것 같다는 생각이 들었다. 기술적인 내용들을 공부해서 팀원들에게 공유해 볼 생각이다.
댓글남기기