


ReAct(Reasoning and Acting) 에이전트
0. 들어가면서
최근 동료와 잡담할 시간이 있었다. 이때 리액트(ReAct) 에이전트라는 개념을 처음 접했다. 토이 프로젝트에서 랭그래프를 사용해서 에이전트를 개발하려고 했었는데, 이 방식보다 쉽게 에이전트를 만들어 볼 수 있을 것 같다는 생각이 들어서 관련된 개념을 공부해 봤다.
1. ReAct(Reasoning and Acting) Agent
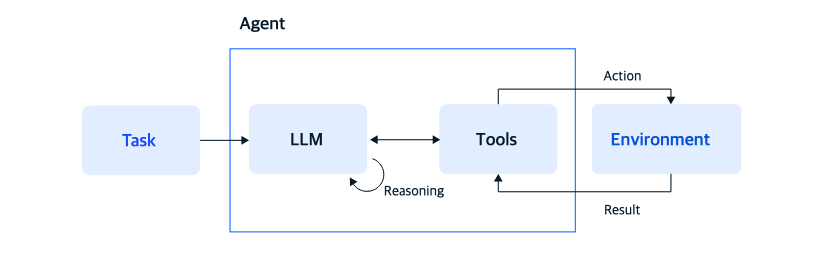
리액트(ReAct)는 Reasoning(추론)과 Acting(행동)의 줄임말이다. 리액트 에이전트의 컨셉은 사람이 복잡한 문제를 해결하는 방식을 모방했다. 모델이 스스로 ‘생각’하고 ‘행동’하며 그 결과를 ‘관찰’하여 다음 단계를 결정하는 순환형 구조를 갖추고 있다.
리액트 에이전트의 동작은 반복적인 사고 과정(Reason → Act → Observe)을 거친다.
- Reason (추론): 입력된 작업이나 현재 상황을 분석하여 문제를 더 작은 단계로 분해하고, 목표를 달성하기 위해 어떤 행동이 필요한지 계획하고 판단한다.
- Act (행동): 추론을 바탕으로 검색 엔진, 데이터베이스, API 등 적절한 외부 도구(Tool)를 선택하여 실행하고 정보를 수집하거나 환경과 상호작용한다.
- Observe (관찰): 도구 실행을 통해 얻은 외부 환경의 결과(관찰값)를 확인한다. 에이전트는 이 새로운 정보를 바탕으로 자신의 지식을 업데이트하고, 다음번 반복(Iteration)에서 추론을 더욱 정교하게 다듬는다.
에이전트는 주어진 작업이 성공적으로 완료되거나 만족스러운 결론에 도달할 때까지 이 추론-행동-관찰 루프를 자율적으로 반복한다.
프린스턴 대학교(princeton university) 컴퓨터 과학과와 구글 리서치 브레인 팀의 연구진들이 공동으로 진행한 연구 내용을 보면 리액트 에이전트를 4가지 벤치마크인 질의응답, 팩트 검증, 텍스트 기반 게임, 웹페이지 탐색에 대해 평가했고, 다음과 같은 결과를 얻었다고 한다.
- 기존의 ‘생각의 사슬(Chain-of-Thought, CoT)’ 프롬프팅에서 흔히 발생하던 환각(Hallucination) 현상과 오류 전파 문제를 성공적으로 극복하고, 인간의 해석 가능성과 모델의 신뢰성을 크게 향상시켰다.
- 위키피디아 API와 상호작용하도록 했을 때, 일반적인 행동 생성 모델보다 우수한 성능을 보였으며 CoT 방식과도 경쟁력 있는 결과를 냈다. 특히, 모델의 내부 지식과 외부 환경에서 얻은 정보를 모두 활용할 수 있는 ReAct 방식과 CoT 방식을 결합했을 때 가장 뛰어난 최고 성능을 달성했다.
- ReAct 방식은 단 1~2개의 예시(one or two-shot)만 프롬프트로 제공받고도 방대한 양의 데이터로 훈련된 모방 학습이나 강화 학습 기법의 성능을 능가했다. 성공률 측면에서 두 벤치마크에 대해 각각 34%와 10%의 성능 향상을 기록했다.
반복 루프 내에서 추론-행동-관찰을 지속하니 단일 도구 호출로 끝나는 것이 아니라 여러 단계의 도구 호출을 거치며 복잡한 다단계 문제를 단계별로 분해하고, 유연하게 해결하고, 외부 개입 없이 모델 스스로 도구 사용 여부와 종료 시점을 결정하는 자율적 제어 능력을 갖추고 있다고 한다.
2. Example
개념에 대해 살펴봤으니 이번엔 예제 코드를 들여다보자. 랭체인(langchain)으로 리액트 에이전트를 구현한다. 이 글에서는 랭체인 v1 릴리즈를 사용한다. 빠르게 발전하는 분야라 그런지 참고한 예제 코드마다 구현 방법이 달랐다. 관련 내용들을 조사해 보니 v1 릴리즈를 기점으로 리액트 에이전트 구축 방식에 큰 변화가 있었다.
주요 내용은 기존의 랭그래프(langgraph)의 create_react_agent 함수 대신 create_agent 함수를 새로운 표준으로 사용하게 된 점이다. langgraph.prebuilt 패키지의 create_react_agent 함수 대신 langchain.agents 패키지의 create_agent 함수가 에이전트 구축의 새로운 권장 표준이 되었다. 이번 예제는 랭체인 v1의 create_agent 함수를 사용했다. 예제 전체 코드는 해당 레포지토리에서 확인할 수 있다.
먼저 프로젝트에 가상 환경을 준비한다.
$ python3 -m venv .venv
가상 환경을 활성화한다.
$ source .venv/bin/activate
필요한 의존성들을 설치한다.
$ pip install -r requirements.txt
이제 본격적으로 코드를 살펴보자. main.py에 작성된 코드가 길기 때문에, 설명의 가독성을 위해 코드를 분리해서 설명한다. 다음과 같은 의존성들이 필요하다.
import asyncio
import json
import random
from typing import Any, Dict
import nest_asyncio
from dotenv import load_dotenv
from langchain.agents import create_agent
from langchain_aws import ChatBedrockConverse
from langchain_core.runnables import RunnableConfig
from langchain_core.tools import tool
from rich.console import Console
from rich.markdown import Markdown
from rich.panel import Panel
아래 코드를 통해 중첩된 이벤트 루프 실행을 허용, 환경변수 주입, 보기 좋은 로깅을 위한 콘솔 객체를 준비한다.
nest_asyncio.apply()
load_dotenv()
console = Console(soft_wrap=True)
이 글에선 AWS 베드록(bedrock)을 사용했다. ChatBedrockConverse 클래스를 사용해 LLM(large language model) 객체를 생성한다. 클로드(claude sonnet 4.6)을 사용했다.
llm = ChatBedrockConverse(
model="jp.anthropic.claude-sonnet-4-6",
region_name="ap-northeast-1",
temperature=0.7,
)
다음과 같은 도구(tool)를 만든다. 1에서 10까지 랜덤한 숫자를 반환한다. 도구를 만들 때는 설명(docstring)이 반드시 작성되어 있어야 한다. AI는 이를 보고 자신이 사용할 도구인지 판단한다.
@tool
def random_number() -> int:
"""Returns a random number between 1 and 10."""
return random.randint(1, 10)
이제 리액트 에이전트가 동작하는 메인 함수를 살펴보자. 코드에 대한 설명은 가독성을 위해 주석으로 남긴다.
async def main():
# [1] create_agent 함수를 통해 에이전트를 만든다. 위에서 정의한 LLM과 도구를 전달한다.
agent = create_agent(model=llm, tools=[random_number])
final_answer = ""
# [2] 반복 조건과 완료 조건에 대한 프롬프트를 작성한다.
prompts = {
"messages": [
{
"role": "user",
"content": """
숫자가 30이 넘지 않을 때까지 랜덤한 숫자를 받아서 더해줘.
30이 넘어가는 순간 멈추고 최종 합계를 알려줘.
""",
}
]
}
# [3] 리액트 에이전트의 실행 반복 횟수를 100회로 지정한다. 기본값이 25이므로 적당히 큰 값을 지정한다.
config: RunnableConfig = {"recursion_limit": 100}
# [4] 스트림을 통해 추론-행동-관찰 과정을 로그로 살펴본다.
async for event in agent.astream_events(prompts, version="v2", config=config):
kind = event["event"]
name = event.get("name", "")
data = event["data"]
if kind == "on_chat_model_start":
print_rule("Agent is Thinking", "yellow")
elif kind == "on_tool_start":
tool_input = get_input(data)
print_panel(tool_input, name, "cyan")
elif kind == "on_tool_end":
output = str(data.get("output", ""))[:300]
print_panel(output, "Tool Result", "green")
elif kind == "on_chain_end" and name == "LangGraph":
final_answer = get_message(data)
# [5] 최종 결과를 출력한다.
console.print()
print_rule("Final Answer", "magenta")
console.print(Markdown(final_answer))
print_rule("", "magenta")
메인 함수를 실행하는 코드를 맨 마지막에 작성한다.
asyncio.run(main())
위 코드를 실행한다.
$ python3 src/main.py
아래 이미지처럼 추론, 행동, 관찰 과정을 로그로 확인할 수 있다.
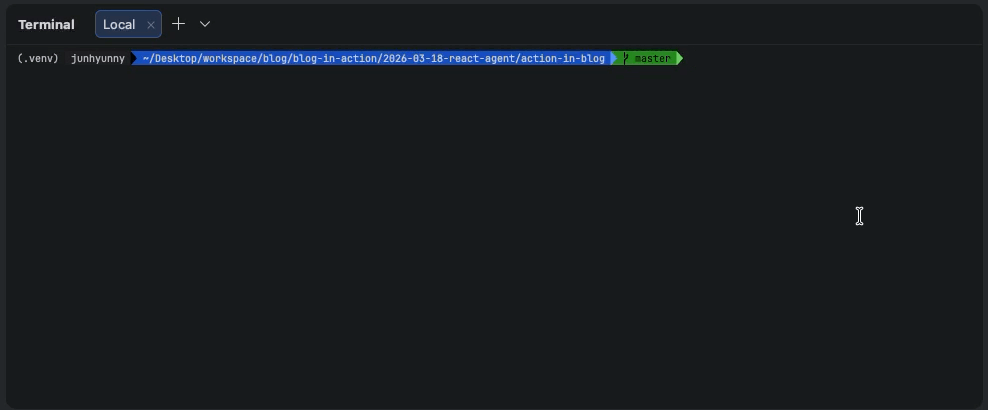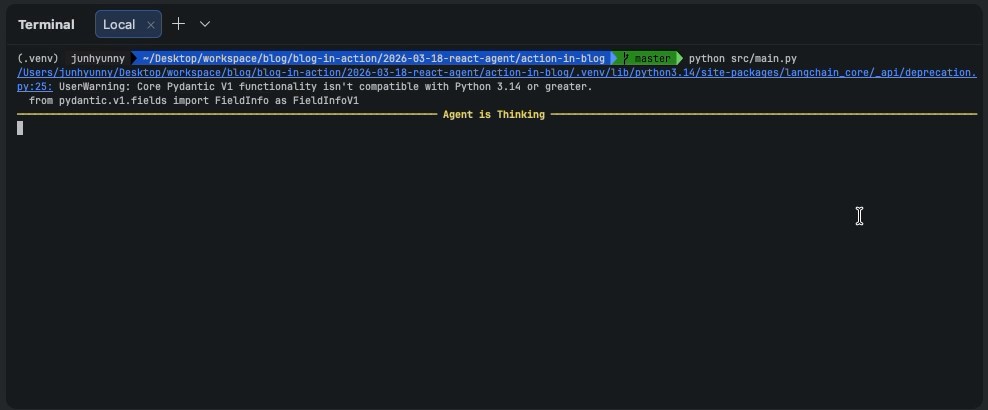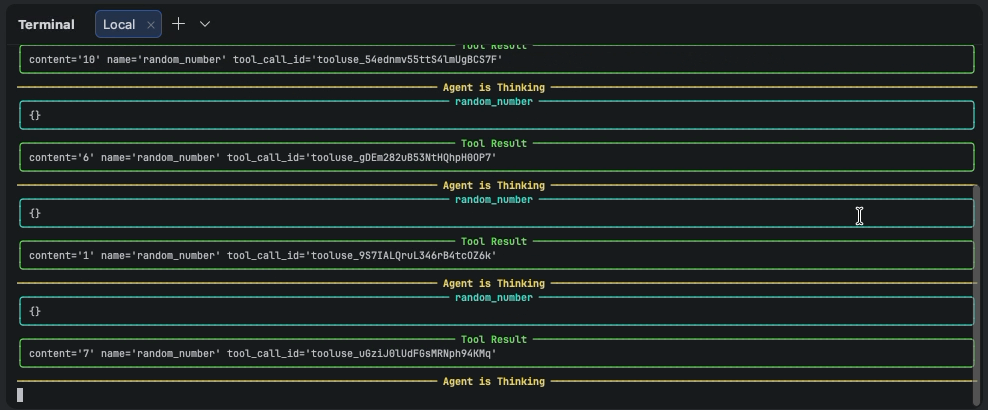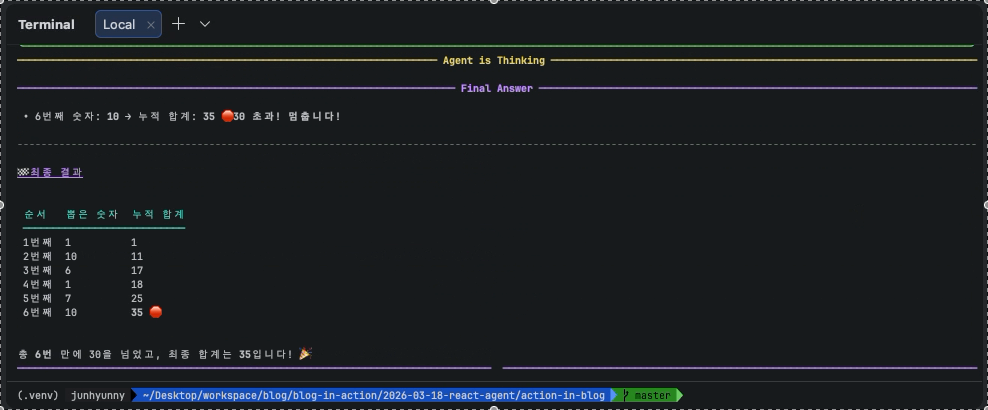
다음과 같은 최종 결과를 로그로 확인할 수 있다.
───────────────────────────────────────────────────────────────────────── Final Answer ─────────────────────────────────────────────────────────────────────────
• 6번째 숫자: 10 → 누적 합계: 35 🛑 30 초과! 멈춥니다!
----------------------------------------------------------------------------------------------------------------------------------------------------------------
🏁 최종 결과
순서 뽑은 숫자 누적 합계
───────────────────────────
1번째 1 1
2번째 10 11
3번째 6 17
4번째 1 18
5번째 7 25
6번째 10 35 🛑
총 6번 만에 30을 넘었고, 최종 합계는 35입니다! 🎉
─────────────────────────────────────────────────────────────────────────────── ───────────────────────────────────────────────────────────────────────────────
TEST CODE REPOSITORY
REFERENCE
- https://openreview.net/pdf?id=WE_vluYUL-X
- https://www.promptingguide.ai/kr/techniques/react
- https://docs.langchain.com/oss/python/migrate/langchain-v1
- https://docs.langchain.com/oss/python/releases/langchain-v1#create-agent
- https://devocean.sk.com/blog/techBoardDetail.do?ID=167523&boardType=techBlog
- https://www.leewayhertz.com/react-agents-vs-function-calling-agents/
- https://wikidocs.net/299482
댓글남기기